70 KiB
Einführung
Betriebssysteme stecken nicht nur in Einzelplatzrechnern, sondern z.B. auch in:
- Informationssystemen
- Gesundheitswesen
- Finanzdienstleister
- Verkehrsmanagement-Systemen
- Eisenbahn
- Flugwesen
- Kommunikationssystemen
- Mobilfunk
- Raumfahrt
- eingebettetenSystemen
- Multimedia
- Fahrzeugsysteme
- Sensornetze
- ...
\rightarrowverschiedenste Anforderungen!
Konsequenz: Spezialbetriebssysteme für Anforderungen wie ...
- Robustheit
- Echtzeitfähigkeit
- Energieeffizienz
- Sicherheit
- Adaptivität
- ...
Gegenstand dieser Vorlesung: Konstruktionsrichtlinien für solche ,,High-End Betriebssysteme''
Funktionale und nichtfunktionale Eigenschaften
-
Beispiel: Autokauf ,,Mit unserem Fahrzeug können Sie einkaufen fahren!''
-
Beispiel: Handykauf ,,Mit unserem Telefon können Sie Ihre Freunde und Familie anrufen!''
-
Anforderungen (Requirements)
- Funktionale und nichtfunktionale Eigenschaften (eines Produkts, z.B. Softwaresystems) entstehen durch Erfüllung von funktionalen und nichtfunktionalen Anforderungen
-
funktionale Eigenschaft
- legt fest, was ein Produkt tun soll.
- Bsp Handykauf: Das Produkt soll Telefongespräche ermöglichen.
-
eine nichtfunktionale Eigenschaft (NFE)
- legt fest, wie es dies tun soll, also welche sonstigen Eigenschaften das Produkt haben soll.
- Bsp Handykauf: Das Produkt soll klein, leicht, energiesparend, strahlungsarm, umweltfreundlich,... sein.
-
andere Bezeichnungen nichtfunktionaler Eigenschaften
- Qualitäten bzw. Qualitätsattribute (eines Software-Produkts):
- Nichtfunktionale Anforderungen bzw. Eigenschaften eines Software-Systems bzw. -Produkts oft auch als seine Qualitäten bezeichnet.
- einzelne realisierte Eigenschaft ist demzufolge ein Qualitätsattribut (quality property) dieses Systems bzw. Produkts.
- Weitere in der Literatur zu findende Begriffe in diesem Zusammenhang:
- Non-functionalrequirements/properties
- Constraints
- Quality ofservice(QoS) requirements
- u.a.
- Qualitäten bzw. Qualitätsattribute (eines Software-Produkts):
-
,,~ilities''
- im Englischen: nichtfunktionale Eigenschaften eines Systems etc. informell auch als seine ,,ilities'' bezeichnet, hergeleitet von Begriffen wie
- Stability
- Portability
- ...
- im Deutschen: ( ,,itäten'',,,barkeiten'', ... möglich aber sprachästhetisch fragenswert)
- Portab-ilität , Skalier-barkeit, aber: Offen-heit , Performanz, ...
- im Englischen: nichtfunktionale Eigenschaften eines Systems etc. informell auch als seine ,,ilities'' bezeichnet, hergeleitet von Begriffen wie
Konsequenzen für Betriebssysteme
Hardwarebasis
Einst: Einprozessor-Systeme
Heute:
- Mehrprozessor-Systeme
- hochparallele Systeme
- neue Synchronisationsmechanismen erforderlich
\rightarrowunterschiedliche Hardware und deren Multiplexing aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssystemarchitektur
Einst: Monolithische und Makrokernel-Architekturen
Heute:
- Mikrokernel(-basierte) Architekturen
- Exokernelbasierte Architekturen ( Library-Betriebssysteme )
- Virtualisierungsarchitekturen
- Multikernel-Architekturen
\rightarrowunterschiedliche Architekturen aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Ressourcenverwaltung
Einst: sog. Batch-Betriebssysteme: Stapelverarbeitung von Jobs (FIFO, Zeitgarantie: irgendwann)
Heute:
- Echtzeitgarantien für Multimedia und Safety-kritische Anwendungen (Unterhaltung, Luft-und Raumfahrt, autonomes Fahren)
- echtzeitfähige Scheduler, Hauptspeicherverwaltung, Ereignismanagement, Umgangmit Überlast und Prioritätsumkehr ...
\rightarrowunterschiedliche Ressourcenverwaltung aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssystemabstraktionen
- zusätzliche Abstraktionen und deren Verwaltung ...
- ... zur Reservierung von Ressourcen (
\rightarroweingebettete Systeme) - ... zur Realisierung von QoS-Anforderungen (
\rightarrowMultimediasysteme) - ... zur Erhöhung der Ausfallsicherheit (
\rightarrowverfügbarkeitskritische Systeme) - ... zum Schutz vor Angriffen und Missbrauch (
\rightarrowsicherheitskritische Systeme) - ... zum flexiblen und modularen Anpassen des Betriebssystems (
\rightarrowhochadaptive Systeme)
- ... zur Reservierung von Ressourcen (
\rightarrowhöchst diverse Abstraktionen von Hardware aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssysteme als Softwareprodukte
- Betriebssystem:
- eine endliche Menge von Quellcode, indiziert durch Zeilennummern: MACOSX =
\{0, 1, 2, ..., 4399822, ...\} - ein komplexes Softwareprodukt ...welches insbesondere allgemeinen Qualitätsanforderungen an den Lebenszyklusvon Softwareprodukten unterliegt!
- eine endliche Menge von Quellcode, indiziert durch Zeilennummern: MACOSX =
- an jedes Softwareprodukt gibt es Anforderungen an seine Nutzung und Pflege
\rightarrowEvolutionseigenschaften - diese können für Betriebssysteme höchst speziell sein (Korrektheitsverifikation, Wartung, Erweiterung, ...)
\rightarrowspezielle Anforderungen an das Softwareprodukt Betriebssystem aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
NFE von Betriebssystemen
Funktionale Eigenschaften (= Funktionen, Aufgaben) ... von Betriebssystemen:
- Betriebssysteme: sehr komplexe Softwareprodukte
- Ein Grund hierfür: besitzen Reihe von differenzierten Aufgaben - also funktionale Eigenschaften
Grundlegende funktionale Eigenschaften von Betriebssystemen:
- Hardware-Abstraktion (Anwendungen/Programmierern eine angenehme Ablaufumgebung auf Basis der Hardware bereitstellen)
- Hardware-Multiplexing (gemeinsame Ablaufumgebung zeitlich oder logisch getrennt einzelnen Anwendungen zuteilen)
- Hardware-Schutz (gemeinsame Ablaufumgebung gegen Fehler und Manipulation durch Anwendungen schützen)
Nichtfunktionale Eigenschaften (Auswahl) von Betriebssystemen:
- Laufzeiteigenschaften
- Sparsamkeit und Effizienz
- Robustheit
- Verfügbarkeit
- Sicherheit (Security)
- Echtzeitfähigkeit
- Adaptivität
- Performanz
- Evolutionseigenschaften
- Wartbarkeit
- Portierbarkeit
- Offenheit
- Erweiterbarkeit
Klassifizierung: Nichtfunktionale Eigenschaften unterteilbar in:
- Laufzeiteigenschaften (execution qualities)
- zur Laufzeit eines Systems beobachtbar
- Beispiele: ,,security'' (Sicherheit), ,,usability'' (Benutzbarkeit), ,,performance'' (Performanz), ...
- Evolutionseigenschaften (evolution qualities)
- charakterisieren (Weiter-) Entwicklung- und Betrieb eines Systems
- Beispiele: ,,testability'' (Testbarkeit), ,,extensibility'' (Erweiterbarkeit) usw.
- liegen in statischer Struktur eines Softwaresystems begründet
Inhalte der Vorlesung
Auswahl sehr häufiger NFE von Betriebssystemen:
- Sparsamkeit und Effizienz
- Robustheit
- Verfügbarkeit
- Sicherheit (Security)
- Echtzeitfähigkeit
- Adaptivität
- Performanz
Diskussion jeder Eigenschaft: (Bsp.: Echtzeitfähigkeit)
- Motivation, Anwendungsgebiete, Begriffsdefinition(en) (Bsp.: Multimedia- und eingebettete Systeme)
- Mechanismen und Abstraktionen des Betriebssystems (Bsp.: Fristen, Deadline-Scheduler)
- unterstützende Betriebssystem-Architekturkonzepte (Bsp.: Mikrokernel)
- ein typisches Beispiel-Betriebssystem (Bsp.: QNX)
- Literaturliste
Sparsamkeit und Effizienz
Motivation
Sparsamkeit (Arbeitsdefinition): Die Eigenschaft eines Systems, seine Funktion mit minimalem Ressourcenverbrauchauszuüben.
Hintergrund: sparsamer Umgang mit einem oder mehreren Ressourcentypen = präziser: Effizienz bei Nutzung dieser Ressourcen
Effizienz: Der Grad, zu welchem ein System oder eine seiner Komponenten seine Funktion mit minimalem Ressourcenverbrauch ausübt. (IEEE)
Entwurfsentscheidungen für BS:
- Wie muss bestimmter Ressourcentyp verwaltet werden, um Einsparungen zu erzielen?
- Welche Erweiterungen/Modifikationen des Betriebssystems (z.B. neue Funktionen, Komponenten, ...) sind hierfür notwendig?
Konkretisierung: Ressource, welche sparsam verwendet wird.
Beispiele:
- mobile Geräte: Sparsamkeit mit Energie
- kleine Geräte, eingebettete Systeme:
- Sparsamkeit mit weiteren Ressourcen, z.B. Speicherplatz
- Betriebssystem (Kernel + User Space): geringer Speicherbedarf
- optimale Speicherverwaltung durch Betriebssystem zur Laufzeit
- Hardwareoptimierungen im Sinne der Sparsamkeit:
- Baugrößenoptimierung(Platinen-und Peripheriegerätegröße)
- Kostenoptimierung(kleine Caches, keine MMU, ...)
- massiv reduzierte HW-Schnittstellen (E/A-Geräte, Peripherie, Netzwerk)
Mobile und eingebettete Systeme (eine kleine Auswahl)
- mobile Rechner-Endgeräte
- Smartphone, Smartwatch
- Laptop-/Tablet-PC
- Weltraumfahrt und -erkundung
- Automobile
- Steuerung von Motor-und Bremssystemen
- Fahrsicherheit
- Insasseninformation (und -unterhaltung)
- (teil-) autonomes Fahren
- verteilte Sensornetze (WSN)
- Chipkarten
- Multimedia-und Unterhaltungselektronik
- eBookReader
- Spielkonsolen
- Digitalkameras
Beispiel: Weltraumerkundung
- Cassini-Huygens (1997-2017)
- Radionuklidbatterien statt Solarzellen
- Massenspeicher: SSDs statt Magnetbänder
- Rosetta (2004-2016)
- 31 Monate im Energiesparmodus
- Opportunity (2003-2019)
- geplante Missionsdauer: 90 d
- Missionsdauer insgesamt: >> 5000 d
- Hayabusa (2003-2010)
- Beschädigung der Energieversorgung
- Energiesparmodus: um 3 Jahre verzögerte Rückkehr
- Voyager 1 (1977 bis heute)
- erste Flugphase: periodisch 20 Monate Standby, 20 Stunden Messungen
- liefert seit 40 Jahren Daten
Energieeffizienz
Hardwaremaßnahmen
- zeitweiliges Abschalten/Herunterschalten momentan nicht benötigter Ressourcen, wie
- Laufwerke: CD/DVD, ..., Festplatte
- Hauptspeicherelemente
- (integrierte/externe) Peripherie: Monitor, E/A-Geräte, ...
Betriebssystemmechanismen
- Dateisystem-E/A:energieeffizientes Festplatten-Prefetching(2.2.1)
- CPU-Scheduling: energieeffizientes Scheduling(2.2.2)
- Speicherverwaltung:minimale Leistungsaufnahme durchSpeicherzugriffe mittels Lokalitätsoptimierung [DGMB07]
- Netzwerk:energiebewusstes Routing
- Verteiltes Rechnen auf Multicore-Prozessoren: temperaturabhängige Lastverteilung
- ...
Energieeffiziente Dateizugriffe
Hardwarebedingungen: Magnetplatten (HDD), Netzwerkgeräte, DRAM-ICs,... sparen nur bei relativ langen Inaktivitätsintervallen Energie.
- Aufgabe: Erzeugen kurzer, intensiver Zugriffsmuster
\rightarrowlange Inaktivitätsintervalle (für alle Geräte mit geringem Energieverbrauch im Ruhezustand) - Beobachtung bei HDD-Geräten: i.A. vier Zustände mit absteigendem Energieverbrauch:
- Aktiv: einziger Arbeitszustand
- Idle (Leerlauf): Platte rotiert, aber Plattenelektronik teilweise abgeschaltet
- Standby: Rotation abgeschaltet
- Sleep: gesamte restliche Elektronik abgeschaltet
- ähnliche, noch stärker differenzierte Zustände bei DRAM (vgl. [DGMB07] )
Energiezustände beim Betrieb von Festplatten:
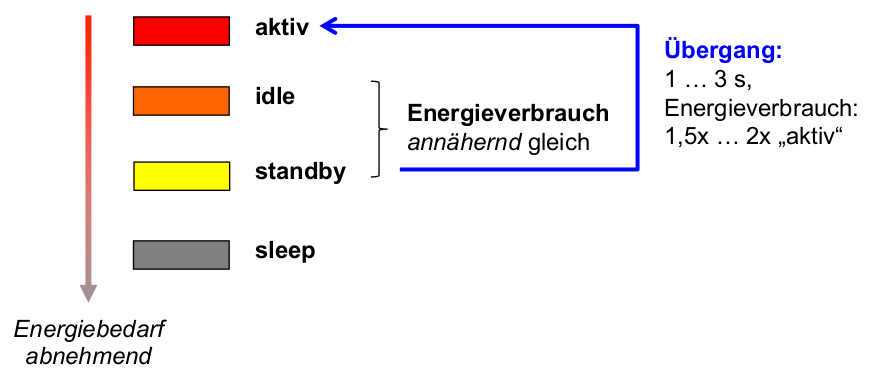
- Schlussfolgerung: durch geringe Verlängerungen des idle - Intervalls kann signifikant der Energieverbrauch reduziert werden.
Prefetching-Mechanismus
- Prefetching (,,Speichervorgriff'', vorausschauendes Lesen) & Caching
- Standard-Praxis bei moderner Datei-E/A
- Voraussetzung: Vorwissen über benötigte Folge von zukünftigen Datenblockreferenzen (z.B. Blockadressen für bestimmte Dateien, gewonnen durch Aufzeichnung früherer Zugriffsmuster beim Start von Anwendungen -Linux: readahead syscall)
- Ziel: Performanzverbesserungdurch Durchsatzerhöhung u. Latenzzeit-Verringerung
- Idee: Vorziehen möglichst vieler E/A-Anforderungen an Festplatte + zeitlich gleichmäßige Verteilung der verbleibenden
- Umsetzung: Caching (Zwischenspeichern) dieser vorausschauend gelesenen Blöcke in ungenutzten Hauptspeicherseitenrahmen ( pagecache )
- Folge: Inaktivitätsintervalle überwiegend sehr kurz
\rightarrowEnergieeffizienz ...? - Zugriffsoperation: (durch Anwendung)
- access(x) ... greife (lesend/schreibend) auf den Inhalt von Festplattenblock x im Page Cache zu
- Festplattenoperationen:
- fetch(x) ... hole Block x nach einem access(x) von Festplatte
- prefetch(x) ... hole Block x ohne access(x) von Festplatte
- beide Operationen schreiben x in einen freien Platz des Festplattencaches; falls dieser voll ist ersetzen sie einen der Einträge gemäß fester Regeln
\rightarrowTeil der (Pre-) Fetching-Strategie
- Beispiel für solche Strategien: Anwendung ...
- mit Datenblock-Referenzstrom A, B, C, D, E, F, G, ...
- mit konstanter Zugriffsdauer: 10 Zeiteinheiten je Blockzugriff
- Cache-Kapazität: 3 Datenblöcke
- Zeit zum Holen eines Blocks bei Cache-Miss: 1 Zeiteinheit
- Beispiel: Traditionelles Prefetching
- Fetch-on-demand-Strategie (kein vorausschauendes Lesen)
- Strategie entsprechend Prefetching- Regeln nach Cao et al. [CFKL95] (= traditionelle Disk-Prefetching- Strategie)
- traditionelle Prefetching-Strategie: bestimmt
- wann ein Datenblock von der Platte zu holen ist (HW-Zustand aktiv )
- welcher Block zu holen ist
- welcher Block zu ersetzen ist
- Regeln für diese Strategie:
- Optimales Prefetching: Jedes prefetch sollte den nächsten Block im Referenzstrom in den Cache bringen, der noch nicht dort ist.
- Optimales Ersetzen: Bei jedem ersetzenden prefetch sollte der Block überschrieben werden, der am spätesten in der Zukunft wieder benötigt wird.
- ,,Richte keinen Schaden an'': Überschreibe niemals Block A um Block B zu holen, wenn A vor B benötigt wird.
- Erste Möglichkeit: Führe nie ein ersetzendes prefetch aus, wenn dieses schon vorher hätte ausgeführt werden können.
- Energieeffizientes Prefetching
- Optimale Ersetzungsstrategie und 3 unterschiedliche Prefetching-Strategien:
- Fetch-on-demand-Strategie:
- Laufzeit: 66 ZE für access(A) ... access(F) , 7 Cache-Misses
- Disk-Idle-Zeit: 6 Intervalle zu je 10 ZE
- Strategie entsprechend Prefetching-Regeln [CFKL95] (traditionelle Disk-Prefetching-Strategie):
- Laufzeit: 61 ZE für access(A) ... access(F) , 1 Cache-Miss
- Disk-Idle-Zeit: 5 Intervalle zu je 9 ZE und 1 Intervall zu 8 ZE (= 53 ZE)
- Energieeffiziente Prefetching-Strategie, die versucht Länge der Disk-Idle-Intervalle zu maximieren:
- gleiche Laufzeit und gleiche Anzahl Cache-Misses wie traditionelles Prefetching
- Disk-Idle-Zeit: 2 Intervalle zu 27 bzw. 28 ZE (= 55 ZE)
- Auswertung: Regeln für energieeffiziente Prefetching-Strategie nach Papathanasiou elal.: [PaSc04]
- Optimales Prefetching: Jedes prefetch sollte den nächsten Block im Referenzstrom in den Cache bringen, der noch nicht dort ist.
- Optimales Ersetzen: Bei jedem ersetzenden prefetch sollte der Block überschrieben werden, der am spätesten in der Zukunft wieder benötigt wird.
- ,,Richte keinen Schaden an'': Überschreibe niemals Block A um Block B zu holen, wenn A vor B benötigt wird.
- Maximiere Zugriffsfolgen: Führe immer dann nach einem fetch oder prefetch ein weiteres prefetch aus, wenn Blöcke für eine Ersetzung geeignet sind. (i.S.v. Regel 3)
- Beachte Idle-Zeiten: Unterbrich nur dann eine Inaktivitätsperiode durch ein prefetch , falls dieses sofort ausgeführt werden muss, um einen Cache-Miss zu vermeiden.
Allgemeine Schlussfolgerungen
- Hardware-Spezifikation nutzen: Modi, in denen wenig Energie verbraucht wird
- Entwicklung von Strategien, die langen Aufenthalt in energiesparenden Modi ermöglichen , und dabei Leistungsparameter in vertretbarem Umfang reduzieren
- Implementieren dieser Strategien in Betriebssystemmechanismen zur Ressourcenverwaltung
Energieeffizientes Prozessormanagement
Hardware-Gegebenheiten
- z.Zt. meistgenutzte Halbleitertechnologie für Prozessor-Hardware: CMOS ( Complementary Metal Oxide Semiconductor)
- Komponenten für Energieverbrauch:
P = P_{switching} + P_{leakage} + ...P_{switching}: für Schaltvorgänge notwendige LeistungP_{leakage}: Verlustleistung durch verschiedene Leckströme- ...: weitere Einflussgrößen (technologiespezifisch)
Hardwareseitige Maßnahmen
Schaltleistung: P_{switching}
- Energiebedarf kapazitiver Lade-u. Entladevorgänge während des Schaltens
- für momentane CMOS-Technologie i.A. dominanter Anteil am Energieverbrauch
- Einsparpotenzial: Verringerung von
- Versorgungsspannung (quadratische Abhängigkeit!)
- Taktfrequenz
- Folgen:
- längere Schaltvorgänge
- größere Latenzzwischen Schaltvorgängen
- Konsequenz: Energieeinsparung nur mit Qualitätseinbußen(direkt o. indirekt) möglich
- Anpassung des Lastprofils ( Zeit-Last-Kurve? Fristen kritisch? )
- Beeinträchtigung der Nutzererfahrung( Reaktivität kritisch? Nutzungsprofil? )
Verlustleistung: P_{leakage}
- Energiebedarf baulich bedingter Leckströme
- Fortschreitende Hardware-Miniaturisierung
\Rightarrowzunehmender Anteil vonP_{leakage}an P - Beispielhafte Größenordnungen zum Einsparpotenzial:
Schaltkreismaße Versorgungsspannung P_{leakage}/P180 nm 2,5 V 0, 70 nm 0,7 V 0, 22 nm 0,4 V > 0,5 - Konsequenz: Leckströme kritisch für energiesparenden Hardwareentwurf
Regelspielraum: Nutzererfahrung
- Nutzererwartung: wichtigstes Kriterium zur (subjektiven) Bewertung von auf einem Rechner aktiven Anwendungen durch Nutzer
\rightarrowNutzerwartung bestimmt Nutzererfahrung - Typ einer Anwendung
- entscheidet über jeweilige Nutzererwartung
- Hintergrundanwendung (z.B. Compiler); von Interesse: Gesamt-Bearbeitungsdauer, Durchsatz
- Echtzeitanwendung(z.B. Video-Player, MP3-Player); von Interesse: ,,flüssiges'' Abspielen von Video oder Musik
- Interaktive Anwendung (z.B. Webbrowser); von Interesse: Reaktivität, d.h. keine (wahrnehmbare) Verzögerung zwischen Nutzer-Aktion und Rechner-Reaktion
- Insbesondere kritisch: Echtzeitanwendungen, interaktive Anwendungen
- entscheidet über jeweilige Nutzererwartung
Reaktivität
- Reaktion von Anwendungen
- abhängig von sog. Reaktivität des Rechnersystems ≈ durchschnittliche Zeitdauer, mit der Reaktion eines Rechners auf eine (Benutzerinter-) Aktion erfolgt
- Reaktivität: von Reihe von Faktoren abhängig, z.B.:
- von Hardware an sich
- von Energieversorgung der Hardware (wichtig z.B. Spannungspegel an verschiedenen Stellen)
- von Software-Gegebenheiten (z.B. Prozess-Scheduling, Speichermanagement, Magnetplatten-E/A-Scheduling, Vorgänge im Fenstersystem, Arten des Ressourcen-Sharing usw.)
Zwischenfazit: Nutzererfahrung
- bietet Regelspielraum für Hardwareparameter (
\rightarrowSchaltleistung)\rightarrowVersorgungsspannung, Taktfrequenz - Betriebssystemmechanismen zum energieeffizienten Prozessormanagement müssen mit Nutzererfahrung(jeweils erforderlicher Reaktivität) ausbalanciert werden (wie solche Mechanismen wirken: 2.2.3)
- Schnittstelle zu anderen NFE:
- Echtzeitfähigkeit
- Performanz
- Usability
- ...
Energieeffizientes Scheduling
- so weit besprochen: Beschränkung des durchschnittlichen Energieverbrauchs eines Prozessors
- offene Frage zum Ressourcenmultiplexing: Energieverbrauch eines Threads/Prozesses?
- Scheduling-Probleme beim Energiesparen:
- Fairness (der Energieverteilung)?
- Prioritätsumkehr?
- Beispiel: Round Robin (RR) mit Prioritäten (Hoch, Mittel, Niedrig)
- Problem 1: Unfaire Energieverteilung
- Beschränkung des Energieverbrauchs (durch Qualitätseinbußen, schlimmstenfalls Ausfall)ab einem oberen Schwellwert
E_{max} - Problem: energieintensive Threads behindern alle nachfolgenden Threads trotz gleicher Priorität
\rightarrowFairnessmaß von RR (gleiche Zeitscheibenlänge T ) untergraben
- Beschränkung des Energieverbrauchs (durch Qualitätseinbußen, schlimmstenfalls Ausfall)ab einem oberen Schwellwert
- Problem 2: energieintensive Threads niedrigerer Priorität behindern später ankommende Threads höherer Priorität
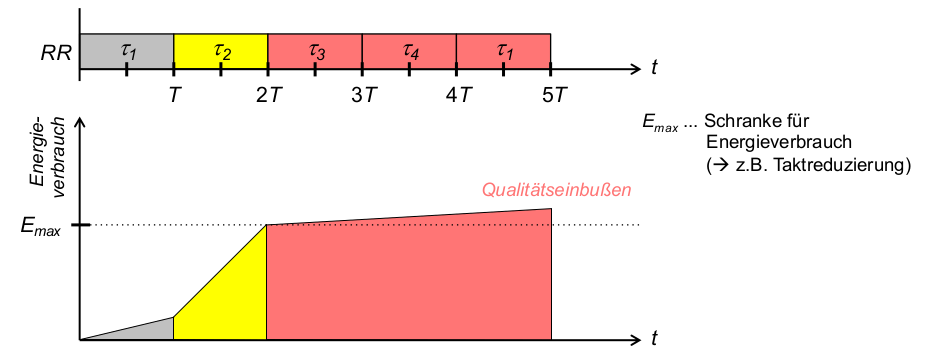
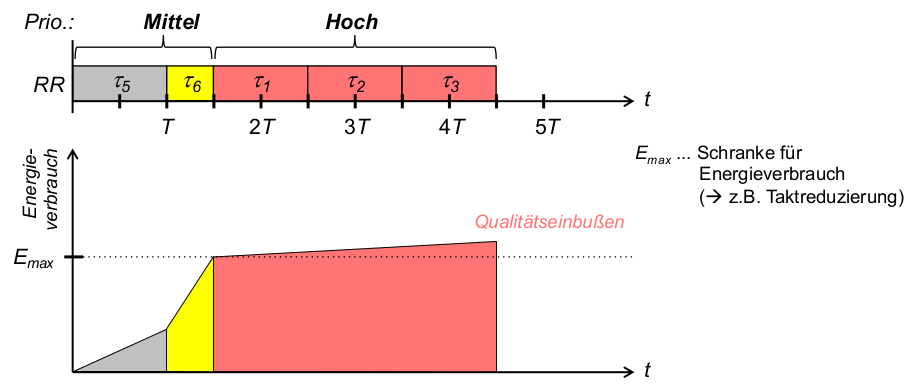
Energiebewusstes RR: Fairness
- Begriffe:
E_i^{budget}... Energiebudget vont_iE_i^{limit}... Energielimit vont_iP_{limit}... Leistungslimit: maximale Leistungsaufnahme [Energie/Zeit]T... resultierende Zeitscheibenlänge
- Strategie 1: faire Energieverteilung (einheitliche Energielimits)
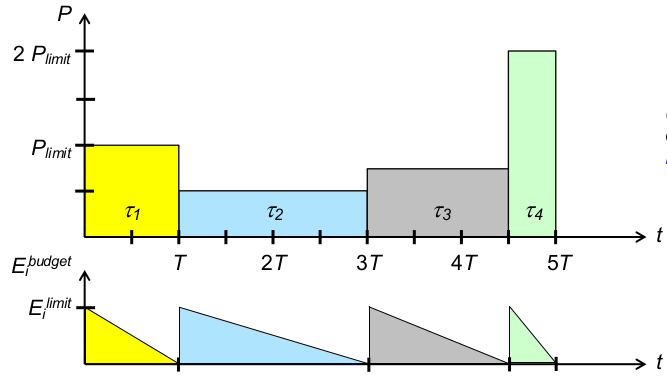
1\leq i\leq 4: E_i^{limit} = P_{limit}* T- (Abweichungen = Wichtung der Prozesse
\rightarrowbedingte Fairness)
Energiebewusstes RR: Reaktivität
- faire bzw. gewichtete Aufteilung begrenzter Energie optimiert Energieeffizienz
- Problem: lange, wenig energieintensive Threads verzögern Antwort-und Wartezeiten kurzer, energieintensiver Threads
- Lösung im Einzelfall: Wichtung per
E_i^{limit} - globale Reaktivität (
\rightarrowNutzererfahrung bei interaktiven Systemen) ...?
- Lösung im Einzelfall: Wichtung per
- Strategie 2: maximale Reaktivität (
\rightarrowklassisches RR)

Energiebewusstes RR: Reaktivität und Fairness
- Problem: sparsame Threads werden bestraft durch Verfallen des ungenutzten Energiebudgets
- Idee: Ansparen von Energiebudgets
\rightarrowmehrfache Ausführung eines Threads innerhalb einer Scheduling-Periode - Strategie 3: Reaktivität, dann faire Energieverteilung

Implementierungsfragen
-
Scheduling-Zeitpunkte?
- welche Accounting-Operationen (Buchführung über Budget)?
- wann Accounting-Operationen?
- wann Verdrängung?
-
Datenstrukturen?
- ... im Scheduler
\rightarrowWarteschlange(n)? - ... im Prozessdeskriptor?
- ... im Scheduler
-
Kosten ggü. klassischem RR? (durch Prioritäten...?)
-
Pro:
- Optimierung der Energieverteilung nach anwendungsspezifischen Schedulingzielen(
\rightarrowStrategien) - Berücksichtigung von prozessspezifischen Energieverbrauchsmustern möglich:fördert Skalierbarkeit i.S.v. Lastadaptivität, indirekt auch Usability (
\rightarrowNutzererfahrung)
- Optimierung der Energieverteilung nach anwendungsspezifischen Schedulingzielen(
-
Kontra:
- zusätzliche sekundäre Kosten: Energiebedarf des Schedulers, Energiebedarf zusätzlicher Kontextwechsel, Implementierungskosten (Rechenzeit, Speicher)
- Voraussetzung hardwareseitig: Monitoring des Energieverbrauchs (erforderliche/realisierbare Granularität...? sonst: Extrapolation?)
-
generelle Alternative: energieintensive Prozesse verlangsamen
\rightarrowRegelung der CPU-Leistungsparameter (Versorgungsspannung) (auch komplementär zum Schedulingals Maßnahme nach Energielimit-Überschreitung) -
Beispiel: Synergie nichtfunktionaler Eigenschaften
- Performanz nur möglich durch Parallelität
\rightarrowMulticore-Hardware - Multicore-Hardware nur möglich mit Lastausgleich und Lastverteilungauf mehrere CPUs
- dies erfordert ebenfalls Verteilungsstrategien: ,,Energy-aware Scheduling'' (Linux-Strategie zur Prozessorallokation -nicht zeitlichem Multiplexing!)
- Performanz nur möglich durch Parallelität
Systemglobale Energieeinsparungsmaßnahmen
- Traditionelle Betriebssysteme: Entwurf so, dass zu jedem Zeitpunkt Spitzen-Performanzangestrebt
- Beobachtungen:
- viele Anwendungen benötigen keine Spitzen-Performanz
- viele Hardware-Komponenten verbringen Zeit in Leerlaufsituationen bzw. in Situationen, wo keine Spitzen-Performanz erforderlich
- Konsequenz (besonders für mobile Systeme) :
- Hardware mit Niedrigenergiezuständen(Prozessoren und Magnetplattenlaufwerke, aber auch DRAM, Netzwerkschnittstellen, Displays, ...)
- somit kann Betriebssystem Energie-Management realisieren
Hardwaretechnologien
- DPM: Dynamic Power Management
- versetzt leerlaufende/unbenutzte Hardware-Komponenten selektiv in Zustände mit niedrigem Energieverbrauch
- Zustandsübergänge durch Power-Manager (in Hardware) gesteuert, dem bestimmte DPM- Strategie (Firmware) zugrunde liegt, um gutes Verhältnis zwischen Performanz/Reaktivität und Energieeinsparung zu erzielen
- DVS: Dynamic Voltage Scaling
- effizientes Verfahren zur dynamischen Regulierungvon Taktfrequenz gemeinsammit Versorgungsspannung
- Nutzung quadratischer Abhängigkeitder dynamischen Leistung von Versorgungsspannung
- Steuerung/Strategien: Softwareunterstützungnotwendig!
Dynamisches Energiemanagement (DPM)- Strategien (Klassen) bestimmt, wann und wie lange eine Hardware-Komponente sich in Energiesparmodusbefinden sollte
- Greedy: Hardware-Komponente sofort nach Erreichen des Leerlaufs in Energiesparmodus, ,,Aufwecken'' durch neue Anforderung
- Time-out: Energiesparmodus erst nachdem ein definiertes Intervall im Leerlauf, ,,Aufwecken'' wie bei Greedy-Strategien
- Vorhersage: Energiesparmodus sofort nach Erreichen des Leerlaufs, wenn Heuristik vorhersagt,dass Kosten gerechtfertigt
- Stochastisch: Energiesparmodus auf Grundlage eines stochastischen Modells
Spannungsskalierung (DVS)
- Ziel: Unterstützung von DPM-Strategien durch Maßnahmen auf Ebene von Compiler, Betriebssystem und Applikationen:
- Compiler
- kann Informationen zur Betriebssystem-Unterstützung bezüglich Spannungs-Einstellung in Anwendungs-Code einstreuen,
- damit zur Laufzeit Informationen über jeweilige Arbeitslast verfügbar
- Compiler
- Betriebssystem (prädiktives Energiemanagement)
- kann Benutzung verschiedener Ressourcen (Prozessor usw.) beobachten
- kann darüber Vorhersagen tätigen
- kann notwendigen Performanzbereich bestimmen
- Anwendungen
- können Informationen über jeweils für sie notwendige Performanz liefern
\rightarrowKombination mit energieefizientemScheduling!
Speichereffizienz
- ... heißt: Auslastung des verfügbaren Speichers
- oft implizit: Hauptspeicherauslastung (memoryfootprint)
- besonders für kleine/mobile Systeme: Hintergrundspeicherauslastung
- Maße zur Konkretisierung:
- zeitliche Dimension: Maximum vs. Summe genutzten Speichers?
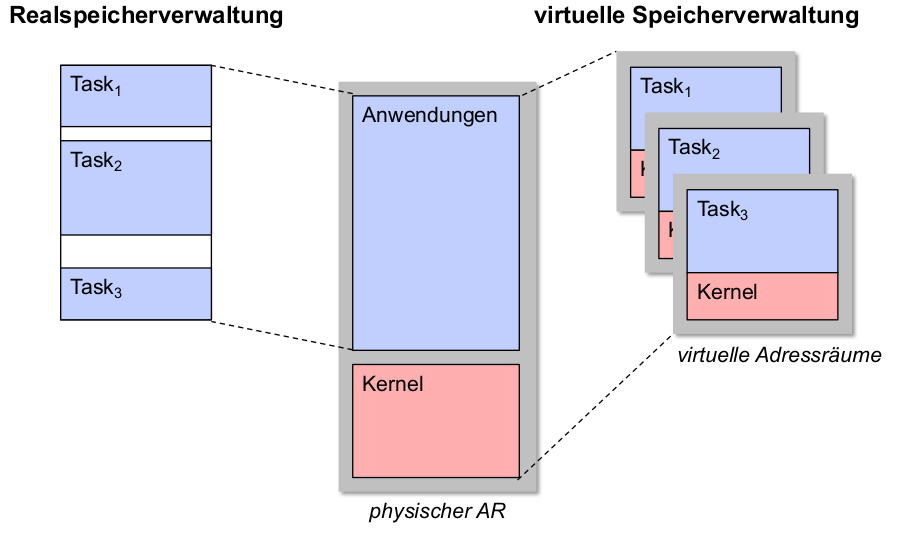
- physischer Speicherverwaltung?
\rightarrowBelegungsanteil pAR - virtuelle Speicherverwaltung?
\rightarrowBelegungsanteil vAR
- Konsequenzen für Ressourcenverwaltung durch BS:
- Taskverwaltung (Accounting, Multiplexing, Fairness, ...)
- Programmiermodell, API (besonders: dynamische Speicherreservierung)
- Sinnfrage und ggf. Strategien virtueller Speicherverwaltung (VMM)
- Konsequenzen für Betriebssystem selbst:
- minimaler Speicherbedarfdurch Kernel
- minimale Speicherverwaltungskosten (durch obige Aufgaben)
Hauptspeicherauslastung
Problem: externe Fragmentierung
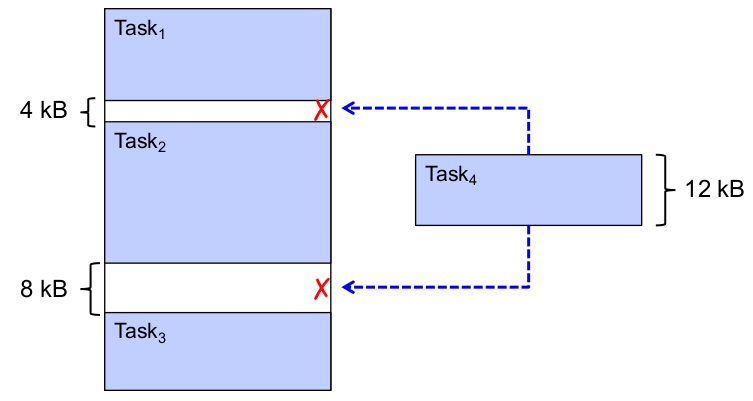
- Lösungen:
- First Fit, Best Fit, WorstFit, Buddy
- Relokation
- Kompromissloser Weg: kein Multitasking!
Problem: interne Fragmentierung
-
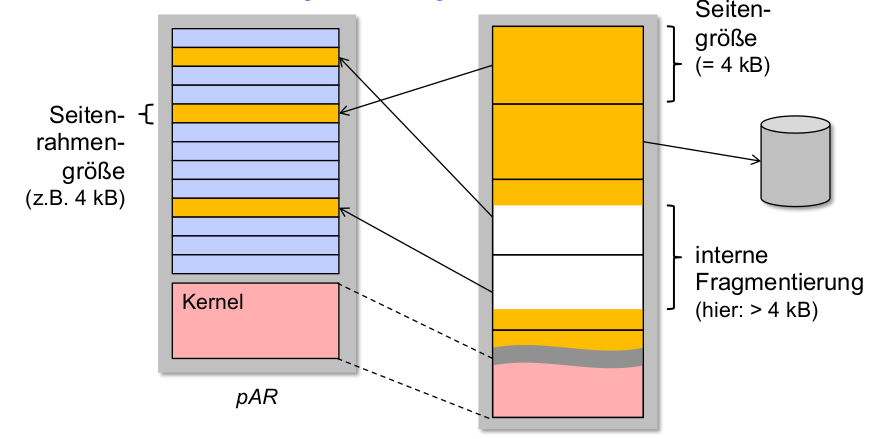
-
Lösung:
- Seitenrahmengröße verringern
- Tradeoff: dichter belegte vAR
\rightarrowgrößere Datenstrukturen für Seitentabellen!
-
direkter Einfluss des Betriebssystems auf Hauptspeicherbelegung:
\rightarrowSpeicherbedarf des Kernels- statische(Minimal-) Größe des Kernels (Anweisungen + Daten)
- dynamischeSpeicherreservierung durch Kernel
- bei Makrokernel: Speicherbedarf von Gerätecontrollern (Treibern)!
weitere Einflussfaktoren: Speicherverwaltungskosten
- VMM: Seitentabellengröße
\rightarrowMehrstufigkeit - Metainformationen über laufende Programme: Größe von Taskkontrollblöcken( Prozess-/Threaddeskriptoren ...)
- dynamische Speicherreservierung durch Tasks
Beispiel 1: sparsam
Prozesskontrollblock (PCB, Metadatenstruktur des Prozessdeskriptors) eines kleinen Echtzeit-Kernels (,,DICK''):
// Process Control Block (PCB)
struct pcb {
char name[MAXLEN +1]; // process name
proc (*addr)(); // first instruction
int type; // process type
int state; // process state
long dline; // absolute deadline
int period; // period
int prt; // priority
int wcet; // worst-case execution time
float util; // processor utilization
int *context;
proc next;
proc prev;
};
Beispiel 2: eher nicht sparsam
Linux Prozesskontrollblock (taskstruct):
struct task_struct {
volatile long state; /* - 1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#endif
int on_rq;
// SCHEDULING INFORMATION
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
// Scheduling Entity
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
#ifdef CONFIG_PREEMPT_NOTIFIERS
struct hlist_head preempt_notifiers; /* list of struct preempt_notifier */
#endif
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
cpumask_t cpus_allowed;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
// virtual address space reference
struct mm_struct *mm, *active_mm;
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned int jobctl; /* JOBCTL_*, siglock protected */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1;/* Tell the LSMs that the process is doing an * execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
unsigned irq_thread;
#endif
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
// Relatives
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/* children/sibling forms the list of my natural children */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid;
...
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
struct list_head *scm_work_list;
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
...
Hintergrundspeicherauslastung
Einflussfaktoren des Betriebssystems:
- statische Größe des Kernel-Images, welches beim Bootstrapping gelesen wird
- statische Größe von Programm-Images (Standards wie ELF)
- statisches vs. dynamisches Einbinden von Bibliotheken: Größe von Programmdateien
- VMM: Größe des Auslagerungsbereichs (inkl. Teilen der Seitentabelle!) für Anwendungen
- Modularisierung (zur Kompilierzeit) des Kernels: gezielte Anpassung an Einsatzdomäne möglich
- Adaptivität (zur Kompilier-und Laufzeit) des Kernels: gezielte Anpassung an sich ändernde Umgebungsbedingungen möglich (
\rightarrowCassini-Huygens-Mission)
Architekturentscheidungen
- bisher betrachtete Mechanismen: allgemein für alle BS gültig
- ... typische Einsatzgebiete sparsamer BS: eingebettete Systeme
- eingebettetes System: (nach [Manl94] )
- Computersystem, das in ein größeres technisches System, welches nicht zur Datenverarbeitung dient,physisch eingebunden ist.
- Wesentlicher Bestandteil dieses größeren Systems hinsichtlich seiner Entwicklung, technischer Ausstattung sowie seines Betriebs.
- Liefert Ausgaben in Form von (menschenlesbaren)Informationen, (maschinenlesbaren)Daten zur Weiterverarbeitung und Steuersignalen.
- BS für eingebettete Systeme: spezielle, anwendungsspezifische Ausprägung der Aufgaben eines ,,klassischen'' Universal-BS
- reduzierter Umfang von HW-Abstraktion, generell: hardwarenähere Ablaufumgebung
- begrenzte (extrem: gar keine) Notwendigkeit von HW-Multiplexing & -Schutz
- daher eng verwandte NFE: Adaptivitätvon sparsamen BS
- sparsame Betriebssysteme:
- energieeffizient ~ geringe Architekturanforderungen an energieintensive Hardware (besonders CPU, MMU, Netzwerk)
- speichereffizient ~ Auskommen mit kleinen Datenstrukturen (memory footprint)
- Konsequenz: geringe logische Komplexität des Betriebssystemkerns
- sekundär: Adaptivität des Betriebssystemkerns
Makrokernel (monolithischer Kernel)
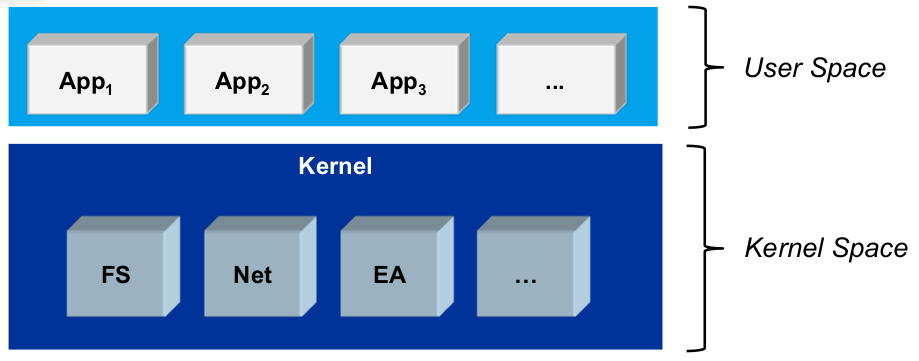
- User Space:
- Anwendungstasks
- CPU im unprivilegiertenModus (Unix ,,Ringe'' 1...3)
- Isolation von Tasks durch Programmiermodell(z.B. Namespaces) oder VMM(private vAR)
- Kernel Space:
- Kernelund Gerätecontroller (Treiber)
- CPU im privilegierten Modus (Unix ,,Ring'' 0)
- keine Isolation (VMM: Kernel wird in alle vAR eingeblendet)
Mikrokernel

- User Space:
- Anwendungstasks, Kernel-und Treiber tasks ( Serverprozesse, grau)
- CPU im unprivilegiertenModus
- Isolation von Tasks durch VMM
- Kernel Space:
- funktional minimaler Kernel(μKernel)
- CPU im privilegierten Modus
- keine Isolation (Kernel wird in alle vAR eingeblendet)
Architekturkonzepte im Vergleich
- Makrokernel:
- ✓ vglw. geringe Kosten von Kernelcode (Energie, Speicher)
- ✓ VMM nicht zwingend erforderlich
- ✓ Multitasking (
\rightarrowProzessmanagement!)nicht zwingend erforderlich - ✗ Kernel (inkl. Treibern) jederzeit im Speicher
- ✗ Robustheit, Sicherheit, Adaptivität
- Mikrokernel:
- ✓ Robustheit, Sicherheit, Adaptivität
- ✓ Kernelspeicherbedarf gering, Serverprozesse nur wenn benötigt (
\rightarrowAdaptivität) - ✗ hohe IPC-Kosten von Serverprozessen
- ✗ Kontextwechselkosten von Serverprozessen
- ✗ VMM, Multitasking i.d.R. erforderlich
Beispiel-Betriebssysteme
TinyOS
- Beispiel für sparsame BS im Bereich eingebetteter Systeme
- verbreitete Anwendung: verteilte Sensornetze (WSN)
- ,,TinyOS'' ist ein quelloffenes, BSD-lizenziertes Betriebssystem
- das für drahtlose Geräte mit geringem Stromverbrauch, wie sie in
- Sensornetzwerke, (
\rightarrowSmart Dust) - Allgegenwärtiges Computing,
- Personal Area Networks,
- intelligente Gebäude,
- und intelligente Zähler.
- Sensornetzwerke, (
- Architektur:
- grundsätzlich: monolithisch (Makrokernel) mit Besonderheiten:
- keine klare Trennung zwischen der Implementierung von Anwendungen und BS (wohl aber von deren funktionalen Aufgaben!)
\rightarrowzur Laufzeit: 1 Anwendung + Kernel
- Mechanismen:
- kein Multithreading, keine echte Parallelität
\rightarrowkeine Synchronisation zwischen Tasks\rightarrowkeine Kontextwechsel bei Taskwechsel- Multitasking realisiert durch Programmiermodell
- nicht-präemptives FIFO-Scheduling
- kein Paging$\rightarrow$ keine Seitentabellen, keine MMU
- in Zahlen:
- Kernelgröße: 400 Byte
- Kernelimagegröße: 1 - 4 kByte
- Anwendungsgröße: typisch ca. 15 kB, Datenbankanwendung: 64 kB
- Programmiermodell:
- BS und Anwendung werden als Ganzes übersetzt: statische Optimierungen durch Compilermöglich (Laufzeit, Speicherbedarf)
- Nebenläufigkeit durch ereignisbasierte Kommunikation zw. Anwendung und Kernel
\rightarrowcommand: API-Aufruf, z.B. EA-Operation (vglb. Systemaufruf)\rightarrowevent: Reaktion auf diesen durch Anwendung
- sowohl commands als auch events : asynchron
- Beispieldeklaration:
interface Timer { command result_t start(char type, uint32_t interval); command result_t stop(); event result_t fired(); } interface SendMsg { command result_t send(uint16_t address, uint8_t length, TOS_MsgPtr msg); event result_t sendDone(TOS_MsgPtr msg, result_t success); }
RIOT
[RIOT-Homepage: http://www.riot-os.org]
- ebenfalls sparsames BS,optimiert für anspruchsvollere Anwendungen (breiteres Spektrum)
- ,,RIOT ist ein Open-Source-Mikrokernel-basiertes Betriebssystem, das speziell für die Anforderungen von Internet-of-Things-Geräten (IoT) und anderen eingebetteten Geräten entwickelt wurde.''
- Smartdevices,
- intelligentes Zuhause, intelligente Zähler,
- eingebettete Unterhaltungssysteme
- persönliche Gesundheitsgeräte,
- intelligentes Fahren,
- Geräte zur Verfolgung und Überwachung der Logistik.
- Architektur:
- halbwegs: Mikrokernel
- energiesparendeKernelfunktionalität:
- minimale Algorithmenkomplexität
- vereinfachtes Threadkonzept
\rightarrowkeine Kontextsicherung erforderlich - keine dynamische Speicherallokation
- energiesparende Hardwarezustände vom Scheduler ausgelöst (inaktive CPU)
- Mikrokerneldesign unterstützt komplementäre NFE: Adaptivität, Erweiterbarkeit
- Kosten: IPC (hier gering!)
- Mechanismen:
- Multithreading-Programmiermodell
- modulare Implementierung von Dateisystemen, Scheduler, Netzwerkstack
- in Zahlen:
- Kernelgröße: 1,5 kByte
- Kernelimagegröße: 5 kByte
Implementierung
- ... kann sich jeder mal ansehen (keine spezielle Hardware, beliebige Linux-Distribution, FreeBSD, macOSX mit git ):
$ git clone git://github.com/RIOT-OS/RIOT.git $ cd RIOT $ cd examples/default/ $ make all $ make term - startet interaktive Instanz von RIOT als ein Prozess des Host-BS
- Verzeichnis RIOT: Quellenzur Kompilierung des Kernels, mitgelieferte Bibliotheken, Gerätetreiber, Beispielanwendungen; z.B.:
- RIOT/core/include/thread.h: Threadmodell, Threaddeskriptor
- RIOT/core/include/sched.h,
- RIOT/core/sched.c: Implementierung des (einfachen) Schedulers
- weitere Infos: riot-os.org/api
Robustheit und Verfügbarkeit
Motivation
- allgemein: verlässlichkeitskritischeAnwendungsszenarien
- Forschung in garstiger Umwelt
- Weltraumerkundung
- hochsicherheitskritische Systeme:
- Rechenzentren von Finanzdienstleistern
- Rechenzentren von Cloud-Dienstleistern
- hochverfügbare System:
- all das bereits genannte
- öffentliche Infrastruktur(Strom, Fernwärme, ...)
- HPC (high performancecomputing)
Allgemeine Begriffe
- Verlässlichkeit, Zuverlässigkeit (dependability)
- übergeordnete Eigenschaft eines Systems [ALRL04]
- Fähigkeit, eine Leistungzu erbringen, der man berechtigterweise vertrauen kann
- Taxonomie: umfasst entsprechend Definition die Untereigenschaften
- Verfügbarkeit (availability)
- Robustheit (robustness, reliability
- (Funktions-) Sicherheit (safety)
- Vertraulichkeit (confidentiality)
- Integrität (integrity)
- Wartbarkeit (maintainability) (vgl.: evolutionäre Eigenschaften)
- 1., 4. & 5. auch Untereigenschaften von IT-Sicherheit (security)
\rightarrownicht für alle Anwendungen sind alle Untereigenschaften erforderlich
Robustheitsbegriff
- Teil der primären Untereigenschaften von Verlässlichkeit: Robustheit (robustness, reliability)
- Ausfall: beobachtbare Verminderung der Leistung, die ein System tatsächlich erbringt, gegenüber seiner als korrekt spezifizierten Leistung
- Robustheit: Verlässlichkeit unter Anwesenheit externer Ausfälle (= Ausfälle, deren Ursache außerhalb des betrachteten Systems liegt)
- im Folgenden: kurze Systematik der Ausfälle ...
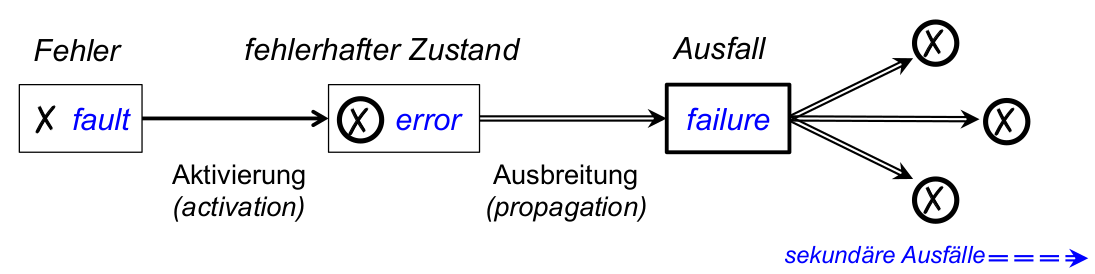
Fehler und Ausfälle ...
- Fehler
\rightarrowfehlerhafter Zustand\rightarrowAusfall - grundlegende Definitionen dieser Begriffe (ausführlich: [ALRL04, AvLR04] ):
- Ausfall (failure): liegt vor, wenn tatsächliche Leistung(en), die ein System erbringt, von als korrekt spezifizierter Leistung abweichen
- fehlerhafter Zustand ( error ): notwendige Ursacheeines Ausfalls (nicht jeder error muss zu failure führen)
- Fehler ( fault ): Ursache für fehlerhaften Systemzustand ( error ), z.B. Programmierfehler
... und ihre Vermeidung
- Umgang mit ...
- faults:
- Korrektheit testen
- Korrektheit beweisen(
\rightarrowformale Verifikation)
- errors:
- Maskierung, Redundanz
- Isolationvon Subsystemen
\rightarrowIsolationsmechanismen
- failures:
- Ausfallverhalten (neben korrektem Verhalten) spezifizieren
- Ausfälle zur Laufzeit erkennen und Folgen beheben, abschwächen...
\rightarrowMicro-Reboots
- faults:
Fehlerhafter Zustand
- interner und externer Zustand (internal & external state)
- externer Zustand (einer Systems oder Subsystems): der Teil des Gesamtzustands, der an externer Schnittstelle (also für das umgebende (Sub-) System) sichtbar wird
- interner Zustand: restlicher Teilzustand
- (tatsächlich) erbrachte Leistung: zeitliche Folge externer Zustände
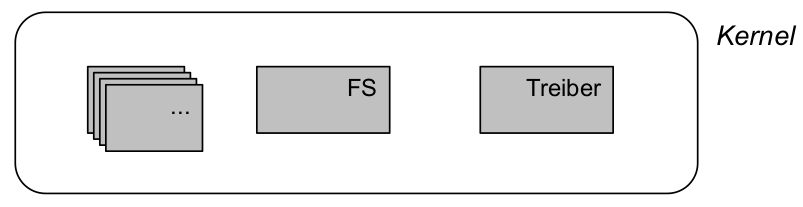
- Beispiele für das System ( Betriebssystem-) Kernel :
- Subsysteme: Dateisystem, Scheduler, E/A, IPC, ..., Gerätetreiber
- fault : Programmierfehler im Gerätetreiber
- externer Zustand des Treibers (oder des Dateisystems, Schedulers, E/A, IPC, ...) ⊂ interner Zustand des Kernels
Fehlerausbreitung und (externer) Ausfall
- Wirkungskette:
-[X] Treiber-Programmierfehler (fault)
-[X] fehlerhafter interner Zustand des Treibers (error)
- Ausbreitung dieses Fehlers ( failure des Treibers)
- = fehlerhafter externer Zustand des Treibers
- = fehlerhafter interner Zustand des Kernels( error )
- = Kernelausfall!( failure )
- Auswirkung: fehlerhafter interner Zustand eines weiteren Kernel-Subsystems (z.B. error des Dateisystems)
\rightarrowRobustheit: Isolationsmechanismen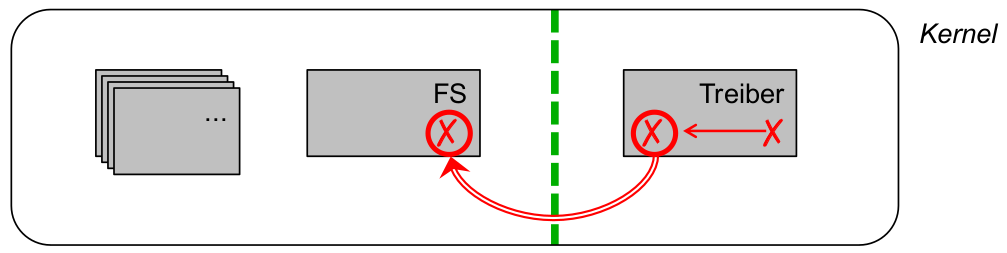
Isolationsmechanismen
- im Folgenden: Isolationsmechanismen für robuste Betriebssysteme
- durch strukturierte Programmierung
- durch Adressraumisolation
- es gibt noch mehr: Isolationsmechanismen für sichere Betriebssysteme
- all die obigen...
- durch kryptografische Hardwareunterstützung: Enclaves
- durch streng typisierte Sprachen und managed code
- durch isolierte Laufzeitumgebungen: Virtualisierung
Strukturierte Programmierung
Monolithisches BS... in historischer Reinform:
- Anwendungen
- Kernel
- gesamte BS-Funktionalität
- programmiert als Sammlung von Prozeduren
- jede darf jede davon aufrufen
- keine Modularisierung
- keine definierten internen Schnittstellen
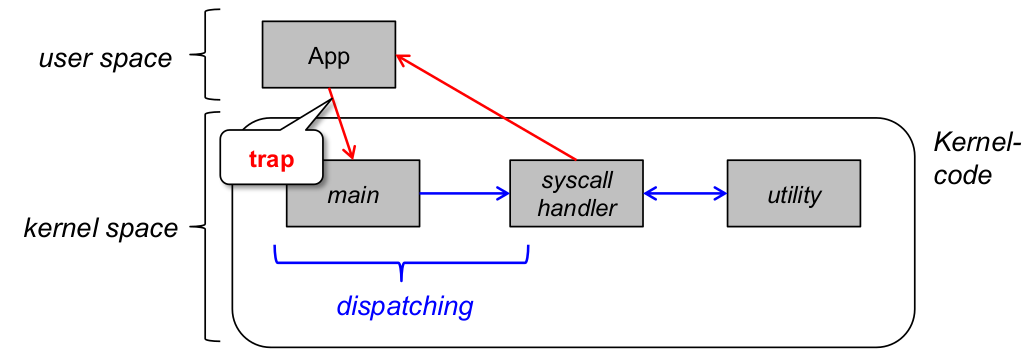
Monolithisches Prinzip
- Ziel: Isolation zwischen Anwendungen und Betriebssystem
- Mechanismus: Prozessor-Privilegierungsebenen ( user space und kernel space )
- Konsequenz für Strukturierung des Kernels: Es gibt keine Strukturierung des Kernels ...
- ... jedenfalls fast: Ablauf eines Systemaufrufs (Erinnerung)

Strukturierte Makrokernarchitektur
- Resultat: schwach strukturierter (monolithischer) Makrokernel
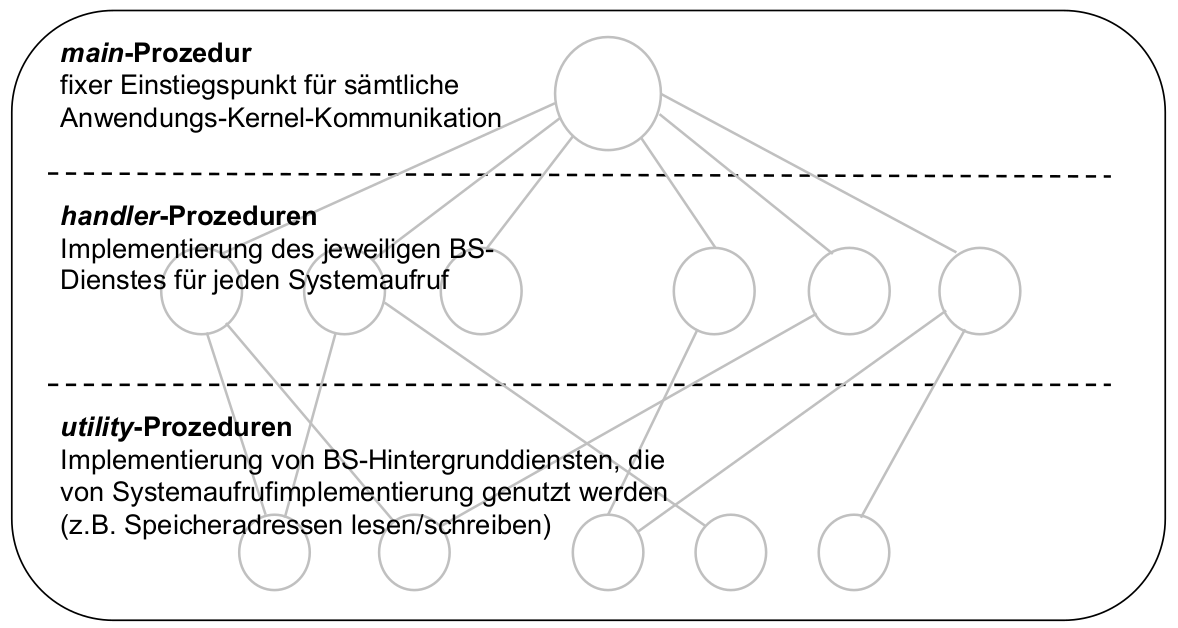
- nach [TaWo05], S. 45
- Weiterentwicklung:
- Schichtendifferenzierung ( layered operating system )
- Modularisierung (Bsp.: Linux-Kernel)
Kernelcode VFS IPC, Dateisystem Scheduler, VMM Dispatcher, Gerätetreiber - Modularer Makrokernel:
- alle Kernelfunktionen in Moduleunterteilt (z.B. verschiedene Dateisystemtypen)
\rightarrowErweiterbarkeit, Wartbarkeit, Portierbarkeit - klar definierte Modulschnittstellen(z.B. virtualfilesystem, VFS )
- Module zur Kernellaufzeit dynamisch einbindbar (
\rightarrowAdaptivität)
Fehlerausbreitung beim Makrokernel
- strukturierte Programmierung:
- ✓ Wartbarkeit
- ✓ Portierbarkeit
- ✓ Erweiterbarkeit
- O (begrenzt) Adaptivität
- O (begrenzt) Schutz gegen statische Programmierfehler: nur durch Compiler (z.B. C private, public)
- ✗ kein Schutz gegen dynamische Fehler
\rightarrowRobustheit...?- nächstes Ziel: Schutz gegen Laufzeitfehler...
\rightarrowLaufzeitmechanismen
Adressraumisolation
- zur Erinnerung: private virtuelle Adressräume zweier Tasks (
i\not= j) - private virtuelle vs. physischer Adresse
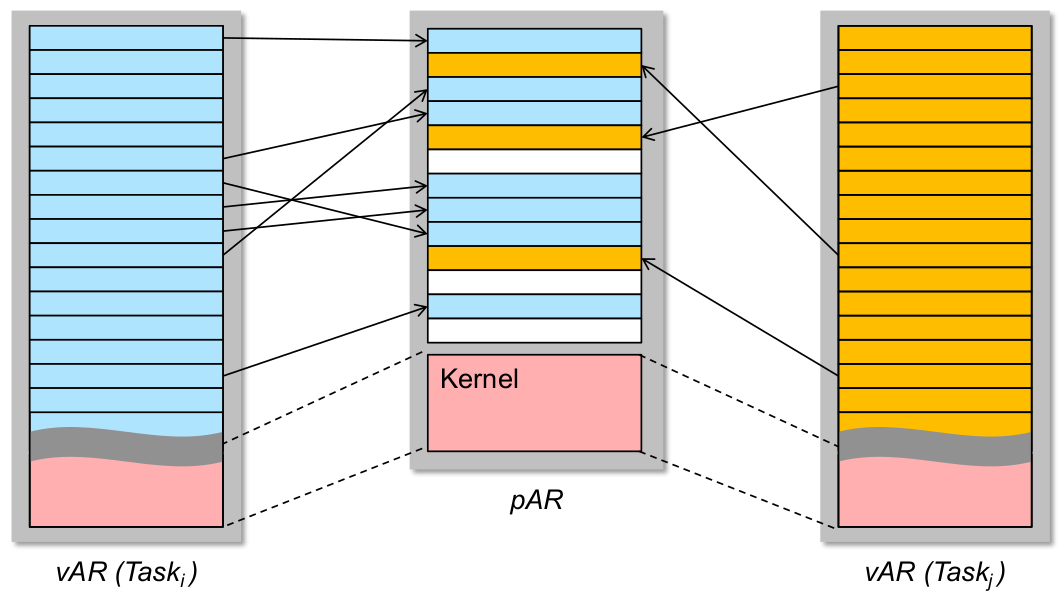
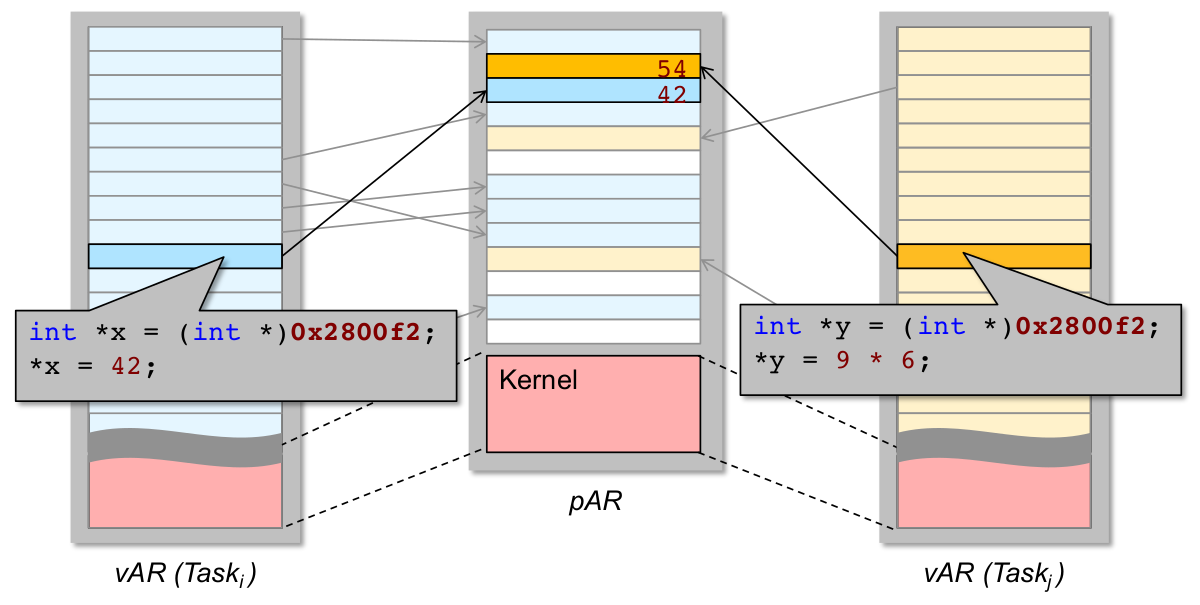
Private virtuelle Adressräume und Fehlerausbreitung
- korrekte private vAR ~ kollisionsfreie Seitenabbildung!
- Magie in Hardware: MMU (BS steuert und verwaltet...)
- Robustheit: Was haben wir von privaten vAR?
- ✓ nichtvertrauenswürdiger (i.S.v. potenziell nicht korrekter) Code kann keine beliebigen physischen Adressen schreiben (er erreicht sie ja nicht mal...)
- ✓ Kommunikation zwischen nvw. Code (z.B. Anwendungstasks) muss durch IPC-Mechanismen explizit hergestellt werden (u.U. auch shared memory)
\rightarrowÜberwachung und Validierung zur Laufzeit möglich
- ✓ Kontrollfluss begrenzen: Funktionsaufrufe können i.A. (Ausnahme: RPC) keine AR-Grenzen überschreiten
\rightarrowBS-Zugriffssteuerungkann nicht durch Taskfehler ausgehebelt werden\rightarrowunabsichtliche Terminierungsfehler(unendliche Rekursion) erschwert ...
Was das für den Kernel bedeutet
- private virtuelle Adressräume
- gibt es schon so lange wie VMM
- gab es lange nur auf Anwendungsebene
\rightarrowkeine Isolation zwischen Fehlern innerhalb des Kernels!
- nächstes Ziel: Schutz gegen Kernelfehler (Gerätetreiber)...
\rightarrowBS-Architektur
Mikrokernelarchitektur
- Fortschritt ggü. Makrokernel:
- Strukturierungskonzept:
- strenger durchgesetzt durch konsequente Isolation voneinander unabhängiger Kernel-Subsysteme
- zur Laufzeit durchgesetzt
\rightarrowReaktion auf fehlerhafte Zustände möglich!
- zusätzlich zu vertikaler Strukturierung des Kernels: horizontale Strukturierungeingeführt
\rightarrowfunktionale Einheiten: vertikal (Schichten)\rightarrowisolierteEinheiten: horizontal (private vAR)
- Strukturierungskonzept:
- Idee:
- Kernel (alle BS-Funktionalität)
\rightarrowμKernel (minimale BS-Funktionalität) - Rest (insbes. Treiber): ,,gewöhnliche'' Anwendungsprozesse mit Adressraumisolation
- Kommunikation: botschaftenbasierteIPC (auch client-server operating system )
- Nomenklatur: Mikrokernelund Serverprozesse
- Kernel (alle BS-Funktionalität)
Modularer Makrokernel vs. Mikrokernel
![Abb. nach [Heis19]](/wieerwill/Informatik/media/commit/937c7a0723a99459b1397f5ec412ecd0a4c33f50/Assets/AdvancedOperatingSystems-modularer-makrokernel.png)
- minimale Kernelfunktionalität:
- keine Dienste, nur allgemeine Schnittstellenfür diese
- keine Strategien, nur grundlegende Mechanismenzur Ressourcenverwaltung
- neues Problem: minimales Mikrokerneldesign
- ,,Wir haben 100 Leute gefragt...'': Wie entscheide ich das?
![Abb. nach [Heis19]](/wieerwill/Informatik/media/commit/937c7a0723a99459b1397f5ec412ecd0a4c33f50/Assets/AdvancedOperatingSystems-modularer-makrokernel-2.png)
- Ablauf eines Systemaufrufs
- schwarz: unprivilegierteInstruktionen
- blau:privilegierte Instruktionen
- rot:Übergang zwischen beidem (μKern
\rightarrowKontextwechsel!)
Robustheit von Mikrokernen
- = Gewinn durch Adressraumisolation innerhalb des Kernels
- ✓ kein nichtvertrauenswürdiger Code im kernelspace , der dort beliebige physische Adressen manipulieren kann
- ✓ Kommunikation zwischen nvw. Code (nicht zur zwischen Anwendungstasks)muss durch IPC explizit hergestellt werden
\rightarrowÜberwachung und Validierung zur Laufzeit - ✓ Kontrollfluss begrenzen: Zugriffssteuerung auch zwischen Serverprozessen, zur Laufzeit unabhängiges Teilmanagement von Code (Kernelcode) möglich (z.B.: Nichtterminierung erkennen)
- Neu:
- ✓ nvw. BS-Code muss nicht mehr im kernelspace (höchste Prozessorprivilegierung) laufen
- ✓ verbleibender Kernel (dessen Korrektheit wir annehmen): klein, funktional weniger komplex, leichter zu entwickeln, zu testen, evtl. formal zu verifizieren
- ✓ daneben: Adaptivitätdurch konsequentere Modularisierung des Kernels gesteigert
Mach
- Mikrokernel-Design: Erster Versuch
- Carnegie Mellon University (CMU), School of Computer Science 1985 - 1994
- ein wenig Historie
- UNIX (Bell Labs) - K. Thompson, D. Ritchie
- BSD (U Berkeley) - W. Joy
- System V - W. Joy
- Mach (CMU) - R. Rashid
- MINIX - A. Tanenbaum
- NeXTSTEP (NeXT) - S. Jobs
- Linux - L. Torvalds
- GNU Hurd (FSF) - R. Stallman
- Mac OS X (Apple) - S. Jobs
Mach: Ziele
Entstehung
- Grundlage:
- 1975: Aleph(BS des ,,Rochester Intelligent Gateway''), U Rochester
- 1979/81: Accent (verteiltes BS), CMU
- gefördert durch militärische Geldgeber:
- DARPA: Defense AdvancedResearch Projects Agency
- SCI: Strategic Computing Initiative
Ziele
- Mach 3.0 (Richard Rashid, 1989): einer der ersten praktisch nutzbaren μKerne
- Ziel: API-Emulation(≠ Virtualisierung!)von UNIX und -Derivaten auf unterschiedlichen Prozessorarchitekturen
- mehrere unterschiedliche Emulatoren gleichzeitig lauffähig
- Emulation außerhalb des Kernels
- jeder Emulator:
- Komponente im Adressraum des Applikationsprogramms
- 1...n Server, die unabhängig von Applikationsprogramm laufen
Mach-Server zur Emulation
![Abb.: [TaBo15]](/wieerwill/Informatik/media/commit/937c7a0723a99459b1397f5ec412ecd0a4c33f50/Assets/AdvancedOperatingSystems-mach-server.png)
- Emulation von UNIX-Systemen mittels Mach-Serverprozessen
μKernel-Funktionen
- Prozessverwaltung
- Speicherverwaltung
- IPC-und E/A-Dienste, einschließlich Gerätetreiber
unterstützte Abstraktionen (\rightarrow API, Systemaufrufe):
- Prozesse
- Threads
- Speicherobjekte
- Ports (generisches, ortstransparentes Adressierungskonzept; vgl. UNIX ,,everything is a file'')
- Botschaften
- ... (sekundäre, von den obigen genutzte Abstraktionen)
Architektur
-

-
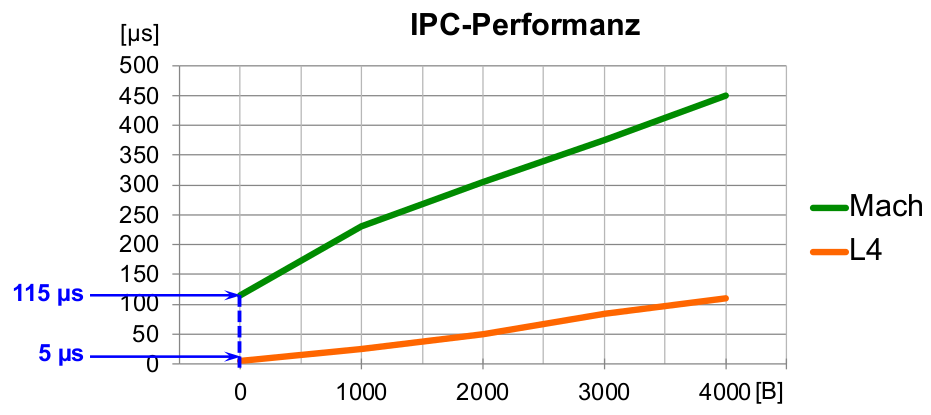
Systemaufrufkosten:
- IPC-Benchmark (1995): i486 Prozessor, 50 MHz
- Messung mit verschiedenen Botschaftenlängen( x - Werte)
- ohne Nutzdaten (0 Byte Botschaftenlänge): 115 μs (Tendenz unfreundlich ...)
-
Bewertung aus heutiger Sicht:
- funktional komplex
- 153 Systemaufrufe
- mehrere Schnittstellen, parallele Implementierungen für eine Funktion
\rightarrowAdaptivität (Auswahl durch Programmierer)
-
Fazit:
- zukunftsweisender Ansatz
- langsame und ineffiziente Implementierung
Lessons Learned
- erster Versuch:
- Idee des Mikrokernelsbekannt
- Umsetzung: Designkriterienweitgehend unbekannt
- Folgen für Performanz und Programmierkomfort: [Heis19]
- ✗ ,,complex''
- ✗ ,,inflexible''
- ✗ ,,slow''
- wir wissen etwas über Kosten: IPC-Performanz, Kernelabstraktionen
- wir wissen noch nichts über guten μKern-Funktionsumfangund gute Schnittstellen...
\rightarrownächstes Ziel!
L4
- Made in Germany:
- Jochen Liedtke (GMD, ,,Gesellschaft für Mathematik und Datenverarbeitung''), Betriebssystemgruppe (u.a.): J. Liedtke, H. Härtig, W. E. Kühnhauser
- Symposium on Operating Systems Principles 1995 (SOSP '95): ,,On μ-Kernel Construction'' [Lied95]
- Analyse des Mach-Kernels:
- falsche Abstraktionen
- unperformanteKernelimplementierung
- prozessorunabhängige Implementierung
- Letzteres: effizienzschädliche Eigenschaft eines Mikrokernels
- Neuimplementierung eines (konzeptionell sauberen!) μ-Kerns kaum teurer als Portierung auf andere Prozessorarchitektur
L3 und L4
- Mikrokerne der 2. Generation
- zunächst L3, insbesondere Nachfolger L4: erste Mikrokerne der 2. Generation
- vollständige Überarbeitung des Mikrokernkonzepts: wesentliche Probleme der 1. Generation (z.B. Mach) vermieden
- Bsp.: durchschnittliche Performanz von User-Mode IPC in L3 ggü. Mach: Faktor 22 zugunsten L3
- heute: verschiedene Weiterentwicklungen von L4 (bezeichnet heute Familie ähnlicher Mikrokerne)
First generation Second Generation Third generation Eg Mach [87] Eg L4 [95] seL4 [09] 

180 syscalls ~7 syscalls ~3 syscalls 100 kLOC ~10 kLOC 9 kLOC 100 \mu sIPC~1 \mu sIPC0,2-1 \mu sIPC
Mikrokernel-Designprinzipien
- Was gehört in einen Mikrokern?
- Liedtke: Unterscheidung zwischen Konzepten und deren Implementierung
- bestimmende Anforderungen an beide:
- Konzeptsicht
\rightarrowFunktionalität, - Implementierungssicht
\rightarrowPerformanz
- Konzeptsicht
\rightarrow1. μKernel-Generation: Konzept durch Performanzentscheidungen aufgeweicht\rightarrowEffekt in der Praxis genau gegenteilig: schlechte (IPC-) Performanz!
,,The determining criterion used is functionality, not performance. More precisely, a concept is tolerated inside the μ-kernel only if moving it outside the kernel, i.e. permitting competing implementations, would prevent the implementation of the systems‘s required functionality .'' [Jochen Liedtke]
Designprinzipien für Mikrokernel-Konzept:
\rightarrowAnnahmen hinsichtlich der funktionalen Anforderungen:
- System interaktive und nicht vollständig vertrauenswürdige Applikationen unterstützen (
\rightarrowHW-Schutz, -Multiplexing), - Hardware mit virtueller Speicherverwaltung und Paging
Designprinzipien:
- Autonomie: ,,Ein Subsystem (Server)muss so implementiert werden können, dass es von keinem anderen Subsystem gestört oder korrumpiert werden kann.''
- Integrität: ,,Subsystem (Server)
S_1muss sich auf Garantien vonS_2verlassen können. D.h. beide Subsysteme müssen miteinander kommunizieren können, ohne dass ein drittes Subsystem diese Kommunikation stören, fälschen oder abhören kann.''
L4: Speicherabstraktion
- Adressraum: Abbildung, die jede virtuelle Seite auf einen physischen Seitenrahmen abbildet oder als ,,nicht zugreifbar'' markiert
- Implementierung über Seitentabellen, unterstützt durch MMU-Hardware
- Aufgabe des Mikrokernels (als gemeinsame obligatorische Schicht aller Subsysteme): muss Hardware-Konzept des Adressraums verbergen und durch eigenes Adressraum-Konzept überlagern (sonst Implementierung von VMM-Mechanismen durch Server unmöglich)
- Mikrokernel-Konzept des Adressraums:
- muss Implementierung von beliebigen virtuellen Speicherverwaltungs-und -schutzkonzepten oberhalb des Mikrokernels (d.h. in den Subsystemen) erlauben
- sollte einfach und dem Hardware-Konzept ähnlich sein
- Idee: abstrakte Speicherverwaltung
- rekursive Konstruktion und Verwaltung der Adressräume auf Benutzer-(Server-)Ebene
- Mikrokernel stellt dafür genau drei Operationen bereit:
- grant(x) - Server
Süberträgt Seitexseines AR in AR von EmpfängerS‘ - map(x) - Server
Sbildet Seitexseines AR in AR von EmpfängerS‘ab - flush(x) - Server
Sentfernt (flusht) Seite x seines AR aus allen fremden AR
- grant(x) - Server
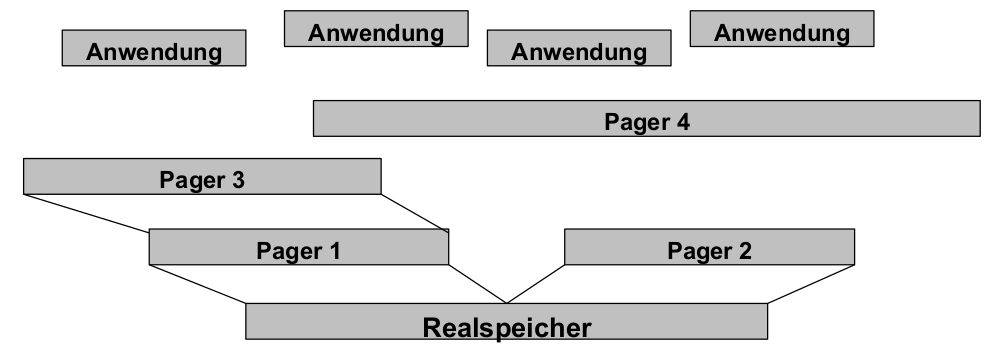
Hierarchische Adressräume
- Rekursive Konstruktion der Adressraumhierarchie
- Server und Anwendungenkönnen damit ihren Klienten Seiten des eigenen Adressraumes zur Verfügung stellen
- Realspeicher: Ur-Adressraum, vom μKernel verwaltet
- Speicherverwaltung(en), Paging usw.: vollständig außerhalb des μ-Kernels realisiert
L4: Threadabstraktion
- Thread
- innerhalb eines Adressraumesablaufende Aktivität
\rightarrowAdressraumzuordnung ist essenziell für Threadkonzept (Code + Daten)- Bindung an Adressraum: dynamisch oder fest
- Änderung einer dynamischen Zuordnung: darf nur unter vertrauenswürdiger Kontrolle erfolgen (sonst: fremde Adressräume les- und korrumpierbar)
- Designentscheidung
\rightarrowAutonomieprinzip\rightarrowKonsequenz: Adressraumisolation\rightarrowentscheidender Grund zur Realisierung des Thread-Konzepts innerhalb des Mikrokernels
IPC
- Interprozess-Kommunikation
- Kommunikation über Adressraumgrenzen: vertrauenswürdig kontrollierte Aufhebung der Isolation
\rightarrowessenziell für (sinnvolles) Multitasking und -threading
- Designentscheidung
\rightarrowIntegritätsprinzip\rightarrowwir haben schon: vertrauenswürdige Adressraumisolation im μKernel\rightarrowgrundlegendes IPC-Konzepts innerhalb des Mikrokernels (flexibel und dynamisch durch Server erweiterbar, analog Adressraumhierarchie)
Identifikatoren
- Thread-und Ressourcenbezeichner
- müssen vertrauenswürdig vergeben (authentisch und i.A. persistent) und verwaltet(eindeutig und korrekt referenzierbar)werden
\rightarrowessenziell für (sinnvolles) Multitasking und -threading\rightarrowessenziell für vertrauenswürdige Kernel-und Server-Schnittstellen
- Designentscheidung
\rightarrowIntegritätsprinzip\rightarrowID-Konzept innerhalb des Mikrokernels (wiederum: durch Server erweiterbar)
Lessons Learned
- Ein minimaler Mikrokernel
- soll Minimalmenge an geeigneten Abstraktionenzur Verfügung stellen:
- flexibel genug, um Implementierung beliebiger Betriebssysteme zu ermöglichen
- Nutzung umfangreicher Mengeverschiedener Hardware-Plattformen
- Geeignete, funktional minimale Mechanismen im μKern:
- Adressraum mit map-, flush-, grant-Operation
- Threadsinklusive IPC
- eindeutige Identifikatoren
- Wahl der geeigneten Abstraktionen:
- kritischfür Verifizierbarkeit (
\rightarrowRobustheit), Adaptivität und optimierte Performanz des Mikrokerns
- kritischfür Verifizierbarkeit (
- Bisherigen μ-Kernel-Abstraktionskonzepte:
- ungeeignete
- zu viele
- zu spezialisierte u. inflexible Abstraktionen
- Konsequenzen für Mikrokernel-Implementierung
- müssen für jeden Prozessortyp neu implementiert werden
- sind deshalb prinzipiell nicht portierbar
\rightarrowL3-und L4-Prototypen by J. Liedtke: 99% Assemblercode
- innerhalb eines Mikrokernels sind
- grundlegende Implementierungsentscheidungen
- meiste Algorithmen u. Datenstrukturen
- von Prozessorhardware abhängig
- Fazit:
- Mikrokernelmit akzeptabler Performanz: hardwarespezifische Implementierung minimalerforderlicher, vom Prozessortyp unabhängiger Abstraktionen
Heutige Bedeutung
- nach Tod von J. Liedtke (2001) auf Basis von L4 zahlreiche moderne BS
- L4 heute: Spezifikation eines Mikrokernels (nicht Implementierung)
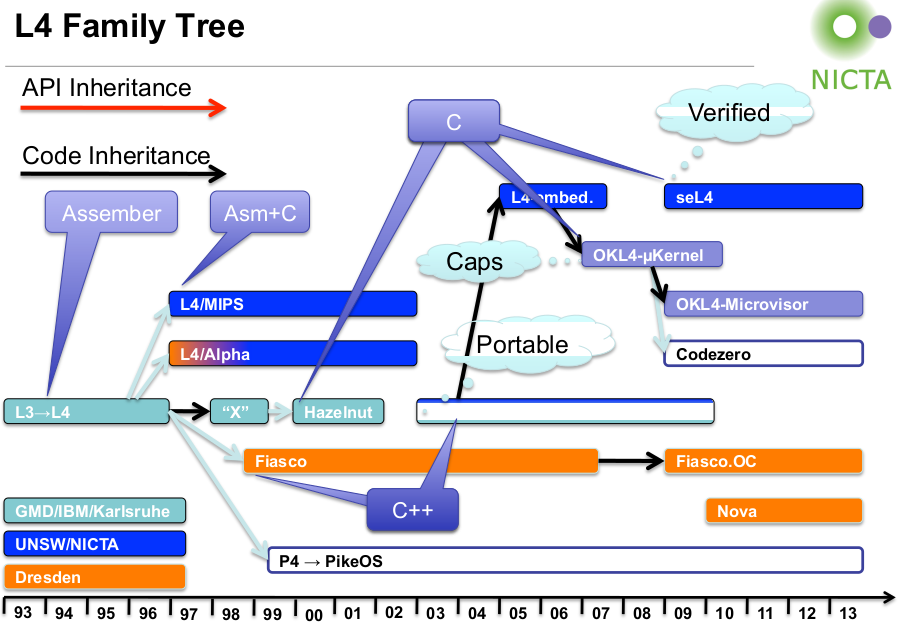
- Einige Weiterentwicklungen:
- TU Dresden (Hermann Härtig): Neuimplementierung in C++ (L4/Fiasco), Basis des Echtzeit-Betriebssystems DROPS, der VirtualisierungsplattformNOVA (genauer: Hypervisor) und des adaptiven BS-Kernels Fiasco.OC
- University ofNew South Wales (UNSW), Australien (Gernot Heiser):
- Implementierung von L4 auf verschiedenen 64 - Bit-Plattformen, bekannt als L4/MIPS, L4/Alpha
- Implementierung in C (Wartbarkeit, Performanz)
- Mit L4Ka::Pistachio bisher schnellste Implementierung von botschaftenbasierterIPC (2005: 36 Zyklen auf Itanium-Architektur)
- seit 2009: seL4, erster formal verifizierter BS-Kernel (d.h. mathematisch bewiesen, dass Implementierung funktional korrekt ist und nachweislich keinen Entwurfsfehler enthält)
Zwischenfazit
- Begrenzung von Fehlerausbreitung (
\rightarrowFolgen von errors ): - konsequent modularisierte Architektur aus Subsystemen
- Isolationsmechanismen zwischen Subsystemen
- Konsequenzen für BS-Kernel:
- statische Isolation auf Quellcodeebene
\rightarrowstrukturierte Programmierung - dynamische Isolation zur Laufzeit
\rightarrowprivate virtuelle Adressräume - Architektur, welche diese Mechanismen komponiert: Mikrokernel
- Was haben wir gewonnen?
- ✓ Adressraumisolation für sämtlichen nichtvertrauenswürdigen Code
- ✓ keine privilegierten Instruktionen in nvw. Code (Serverprozesse)
- ✓ geringe Größe (potenziell: Verifizierbarkeit) des Kernels
- ✓ neben Robustheit: Modularitätund Adaptivitätdes Kernels
- Und was noch nicht?
- ✗ Behandlung von Ausfällen (
\rightarrowabstürzende Gerätetreiber ...)
- ✗ Behandlung von Ausfällen (
3.5 Micro-Reboots
- Beobachtungen am Ausfallverhalten von BS:
- Kernelfehler sind (potenziell) fatal für gesamtes System
- Anwendungsfehler sind es nicht
\rightarrowkleiner Kernel = geringeres Risiko von Systemausfällen\rightarrowdurch BS-Code in Serverprozessen: verbleibendes Risiko unabhängiger Teilausfälle von BS-Funktionalität (z.B. FS, Treiberprozesse, GUI, ...)- Ergänzung zu Isolationsmechanismen:
- Mechanismen zur Behandlung von Subsystem-Ausfällen
- = Mechanismen zur Behandlung Anwendungs-, Server- und Gerätetreiberfehlen
\rightarrowMicro-Reboots
Ansatz
- wir haben:
- kleinen, ergo vertrauenswürdigen (als fehlerfrei angenommenen)μKernel
- BS-Funktionalität in bedingt vertrauenswürdigen Serverprozessen (kontrollierbare, aber wesentlich größere Codebasis)
- Gerätetreiber und Anwendungen in nicht vertrauenswürdigen Prozessen (nicht kontrollierbare Codebasis)
- wir wollen:
- Systemausfälle verhindern durch Vermeidung von errors im Kernel
\rightarrowhöchste Priorität - Treiber-und Serverausfälle minimieren durch Verbergen ihrer Auswirkungen
\rightarrownachgeordnete Priorität (Best-Effort-Prinzip) - Idee:
- Systemausfälle
\rightarrowμKernel - Treiber-und Serverausfälle
\rightarrowNeustart durch spezialisierten Serverprozess
- Systemausfälle
Beispiel: Ethernet-Treiberausfall
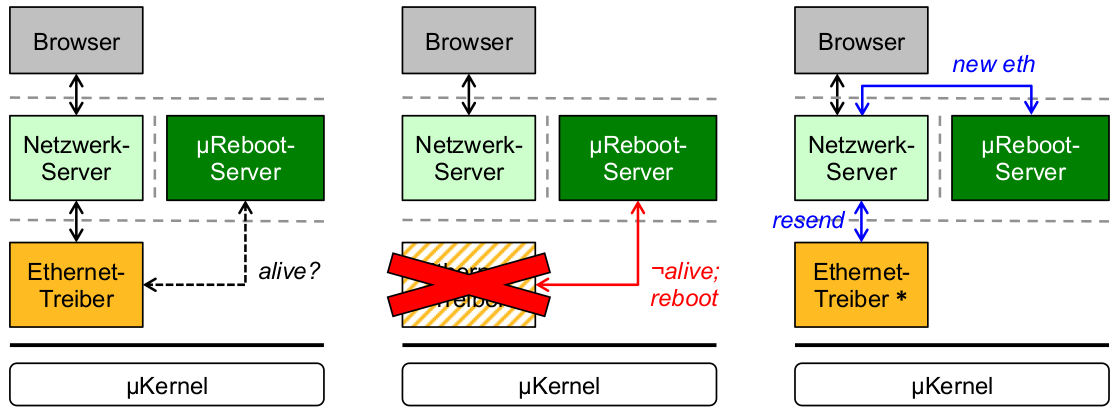
- schwarz: ausfallfreie Kommunikation
- rot: Ausfall und Behandlung
- blau: Wiederherstellung nach Ausfall
Beispiel: Dateisystem-Serverausfall
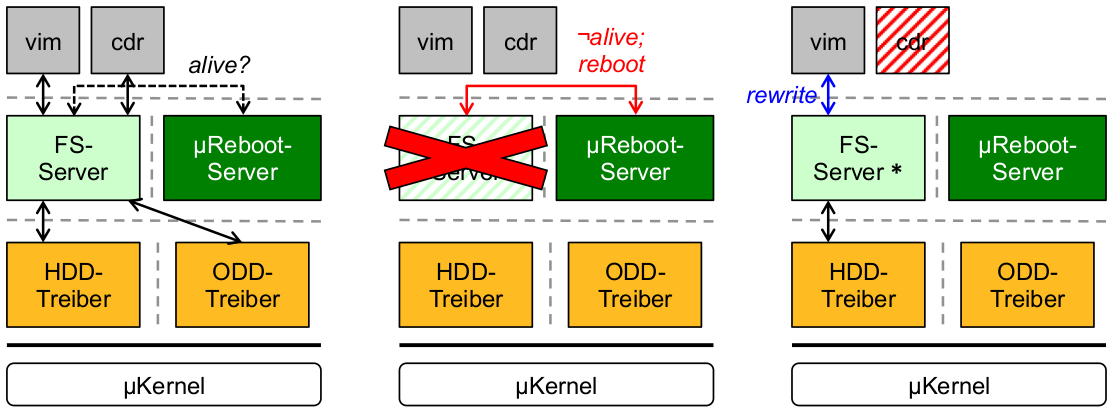
- schwarz: ausfallfreie Kommunikation
- rot: Ausfall und Behandlung
- blau: Wiederherstellung nach Ausfall
Beispiel-Betriebssystem: MINIX
- Ziele:
- robustes Betriebssystems
\rightarrowSchutz gegen Sichtbarwerden von Fehlern(= Ausfälle) für Nutzer- Fokus auf Anwendungsdomänen: Endanwender-Einzelplatzrechner (Desktop, Laptop, Smart*) und eingebettete Systeme
- Anliegen: Robustheit > Verständlichkeit > geringer HW-Bedarf
- aktuelle Version: MINIX 3.3.0
Architektur
- Kommunikationsschnittstellen ...
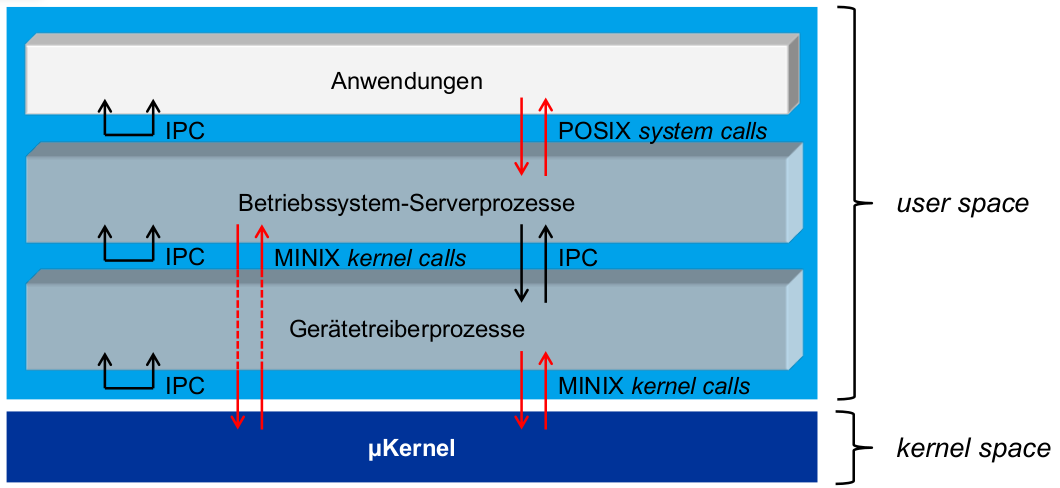
- ... für Anwendungen (weiß): Systemaufrufe im POSIX-Standard
- ... für Serverprozesse (grau):
- untereinander: IPC (botschaftenbasiert)
- mit Kernel: spezielle MINIX-API (kernel calls), für Anwendungsprozesse gesperrt
- Betriebssystem-Serverprozesse:

- Dateisystem (FS)
- Prozessmanagement (PM)
- Netzwerkmanagement (Net)
- Reincarnation Server (RS)
\rightarrowMicro-Reboots jeglicher Serverprozesse - (u. a.) ...
- Kernelprozesse:
- systemtask
- clocktask
Reincarnation Server
- Implementierungstechnik für Micro-Reboots:
- Prozesse zum Systemstart (
\rightarrowKernel Image): system, clock, init, rs- system, clock: Kernelprogramm
- init: Bootstrapping (Initialisierung von rs und anderer BS-Serverprozesse), Fork der Login-Shell (und damit sämtlicher Anwendungsprozesse)
- rs: Fork sämtlicher BS-Serverprozesse, einschließlich Gerätetreiber
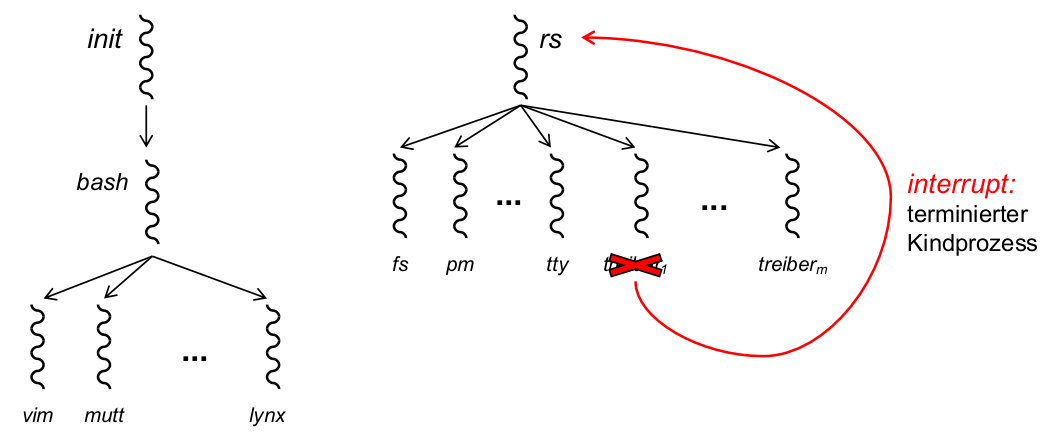
MINIX: Ausprobieren
Verfügbarkeit
- komplementäre NFE zu Robustheit: Verfügbarkeit ( availability )
- Zur Erinnerung: Untereigenschaften von Verlässlichkeit
- Verfügbarkeit (availability)
- Robustheit (robustness, reliability)
- Beziehung:
- Verbesserung von Robustheit
\RightarrowVerbesserung von Verfügbarkeit - Robustheitsmaßnahmen hinreichend , nicht notwendig (hochverfügbare Systeme können sehr wohl von Ausfällen betroffen sein...)
- Verbesserung von Robustheit
- eine weitere komplementäre NFE:
- Robustheit
\RightarrowSicherheit (security)
- Robustheit
Allgemeine Definition: Der Grad, zu welchem ein System oder eine Komponente funktionsfähig und zugänglich (erreichbar) ist,wann immer seine Nutzung erforderlichist. (IEEE)
genauer quantifiziert:
- Der Anteil an Laufzeit eines Systems, in dem dieses seine spezifizierte Leistung erbringt.
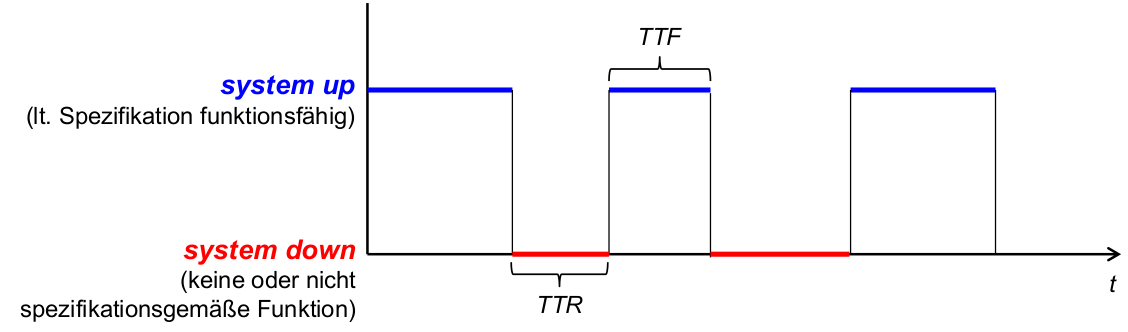
- Availability= Total Uptime/ Total Lifetime= MTTF / (MTTF + MTTR)
- MTTR: Mean Time to Recovery ... Erwartungswert für TTR
- MTTF: Mean Time to Failure ... Erwartungswert für TTF
- einige Verfügbarkeitsklassen:
Verfügbarkeit Ausfallzeit pro Jahr Ausfallzeit pro Woche 90% > 1 Monat ca. 17 Stunden 99% ca. 4 Tage ca. 2 Stunden 99,9% ca. 9 Stunden ca. 10 Minuten 99,99% ca. 1 Stunde ca. 1 Minute 99,999% ca. 5 Minuten ca. 6 Sekunden 99,9999% ca. 2 Sekunden << 1 Sekunde - Hochverfügbarkeitsbereich (gefeierte ,,five nines'' availability)
- Maßnahmen:
- Robustheitsmaßnahmen
- Redundanz
- Ausfallmanagement
QNX Neutrino: Hochverfügbares Echtzeit-BS
Überblick QNX:
- Mikrokern-Betriebssystem
- primäres Einsatzfeld: eingebettete Systeme, z.B. Automobilbau
- Mikrokernarchitektur mit Adressraumisolation für Gerätetreiber
- (begrenzt) dynamische Micro-Rebootsmöglich
\rightarrowMaximierung der Uptime des Gesamtsystems
Hochverfügbarkeitsmechanismen:
- ,,High-Avalability-Manager'': Laufzeit-Monitor, der Systemdienste oder Anwendungsprozesse überwacht und neustartet
\rightarrowμReboot-Server - ,,High-Availability-Client-Libraries'': Funktionen zur transparenten automatischen Reboot für ausgefallene Server-Verbindungen
Sicherheit
Echtzeitfähigkeit
Adaptivität
Performanz und Parallelität
Zusammenfassung
Literatur
- NFE in Betriebssystemen
- Eeles, Peter; Cripps, Peter: The Process of Software Architecting
- Funktionale Eigenschaften eines Betriebssystem
- Tanebaum, Andrews; Bos, Herbert: Modern Operating Systems
- Tanebaum, Andrews; Woodhull, Alberts: Operating Systems Design and Implementation
- Stallings, William: Operating Systems: Internals and Design Principles
- Energieeffizienz
- GUPTA, RAJESHK.; IRANI, SANDY; SHUKLA, SANDEEPK.; SHUKLA, SANDEEPK.: Formal Methods for Dynamic Power Management
- RANGANATHAN, PARTHASARATHY: Recipe for efficiency: principles of power-aware computing
- SIMUNIC, TAJANA; BENINI, LUCA; GLYNN, PETER; DEMICHELI, GIOVANNI: Dynamic Power Management for Portable Systems
- Effiziente Hauptspeicherverwaltung
- DINIZ, BRUNO; GUEDES, DORGIVAL; MEIRA, WAGNER, JR.; BIANCHINI, RICARDO: Limiting the Power Consumption of Main Memory
- Traditionelles Festplatten-Prefetching
- CAO, PEI; FELTEN, EDWARDW.; KARLIN, ANNAR.; LI, KAI: A Study ofIntegrated Prefetching and Caching Strategies
- Effizienter Betrieb von Festplatten
- PAPATHANASIOU, ATHANASIOSE.; SCOTT, MICHAELL.: Energy Efficient Prefetching and Caching
- Energieeffizientes Scheduling
- KLEE, CHRISTOPH: Design and Analysis of Energy-Aware Scheduling Policies
- Energieeffiziente Betriebssysteme
- LANG, CLEMENS: Components for Energy-Efficient Operating Systems
- YAN, LE; ZHONG, LIN; JHA, NIRAJK.: Towards a Responsive, Yet Power-efficient, Operating System: A Holistic Approach
- YAN, LE; ZHONG, LIN; JHA, NIRAJK.: User-perceived Latency Driven Voltage Scaling for Interactive Applications
- Eingebettete Systeme
- MANLEY, JOHNH.: Embedded Systems, MARCINIAK, J. J.(Hrsg.)
- TinyOS
- KELLNER, SIMON; BELLOSA, FRANK: Energy Accounting Support in TinyOS
- KELLNER, SIMON: Flexible Online Energy Accounting in TinyOS
- Verlässlichkeitsbegriff, Fehlermodell:
- [ALRL04] AVIŽIENIS, ALGIRDAS; LAPRIE, JEAN-CLAUDE; RANDELL, BRIAN; LANDWEHR, CARL: Basic Concepts and Taxonomy of Dependable and Secure Computing. In: IEEE Trans. Dependable Secur. Comput. https://doi.org/10.1109/TDSC.2004.2
- [AvLR04] AVIŽIENIS, ALGIRDAS; LAPRIE, JEAN-CLAUDE; RANDELL, BRIAN: Dependability and Its Threats: A Taxonomy. In: JACQUART, R.(Hrsg.): Building theInformation Society , IFIP International Federation for Information Processing : Springer US, 2004, https://doi.org/10.1007/978
- DeepSpace 1 Remote Debugging:
- GARRET, RON: Lispingat JPL. URL http://www.flownet.com/gat/jpl-lisp.html
- Kernelarchitekturdesign und Mikrokernelprinzip:
- [Heis19] HEISER, GERNOT: COMP9242 Advanced Operating Systems. Lecture Slides UNSW Australia, 2019. Courtesy of Gernot Heiser, UNSW. https://www.cse.unsw.edu.au/~cs9242/19/lectures.shtml
- [TaBo15] TANENBAUM, ANDREWS; WOODHULL, ALBERTS: Operating Systems Design and Implementation. 3. Aufl. UpperSaddleRiver, NJ, USA: Prentice-Hall, Inc., 2005
- Mikrokerneldesign, L4:
- [Lied95] LIEDTKE, JOCHEN: On μ-Kernel Construction. In: Operating Systems Review. Special issue for the Fifteenth ACM Symposium on Operating System Principles Bd. 29 (1995), https://doi.org/10.1145/224056.224075
- MINIX:
- HERDER, JORRITN.; BOS, HERBERT; GRAS, BEN; HOMBURG, PHILIP; TANENBAUM, ANDREWS.: MINIX 3: A Highly Reliable, Self-repairing Operating System. In: ACM SIGOPS Operating Systems Review https://doi.org/10.1145/1151374.1151391
- TANENBAUM, ANDREWS. APPUSWAMY, RAJA; BOS, HERBERTJ. ; CAVALLARO, LORENZO; GIUFFRIDA, CRISTIANO; HRUBY, TOMAS; HERDER, JORRIT; VANDERKOUWE, ERIK; U.A.: MINIX 3: Status Report and Current Research. In: login: The USENIX Magazine Bd. 35 (2010) https://www.usenix.org/publications/login/june- 2010
- [TaWo05] TANENBAUM, ANDREWS; WOODHULL, ALBERTS: Operating Systems Design and Implementation. 3. Aufl. UpperSaddleRiver, NJ, USA: Prentice-Hall, Inc.