98 KiB
Motivation und Grundlagen
Aufgaben und Komponenten eines DBMS
Prinzipien: Die neun Codd’schen Regeln
- Integration: einheitliche, nichtredundante Datenverwaltung
- Operationen: Speichern, Suchen, Ändern
- Katalog: Zugriffe auf Datenbankbeschreibungen im Data Dictionary
- Benutzersichten
- Integritätssicherung: Korrektheit des Datenbankinhalts
- Datenschutz: Ausschluss unauthorisierter Zugriffe
- Transaktionen: mehrere DB-Operationen als Funktionseinheit
- Synchronisation: parallele Transaktionen koordinieren
- Datensicherung: Wiederherstellung von Daten nach Systemfehlern
Betrachtete Fragestellung
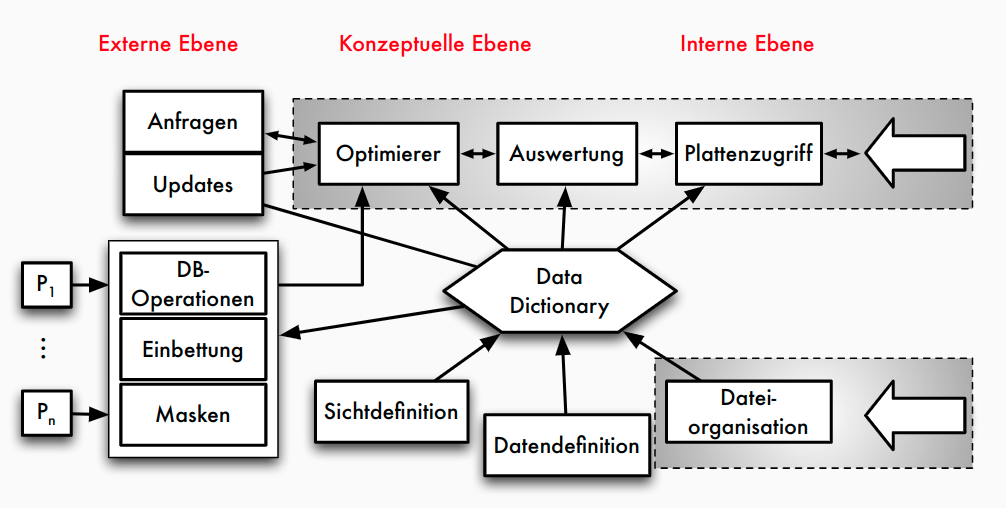
Zentrale Komponenten
- Anfrageverarbeitung : Planung, Optimierung und Ausführung deklarativer Anfragen
- Transaktionsverwaltung : Koordination und Synchronisation von Transaktionen, Durchführung von Änderungen, Sicherung der ACID-Eigenschaften
- Speichersystem : Organisation der Daten im Hauptspeicher und auf dem Externspeicher für effizienten Zugriff und Persistenz
Relationale vs. nicht-relationale DBMS
Relationale DBMS
- Basis: Relationenmodell = Daten in Tabellen strukturiert
- Beziehungen über Werte (= Fremdschlüssel), Integritätsbedingungen
- SQL als standardisierte Anfragesprache
- kommerziell erfolgreichstes Datenmodell: Oracle, IBM DB2, MS SQL Server, SAP HANA, ...
| WEINE | WeinID | Name | Farbe | Jahrgang | Weingut |
|---|---|---|---|---|---|
| 1042 | La Rose Grand Cru | Rot | 1998 | Château ... | |
| 2168 | Creek Shiraz | Rot | 2003 | Creek | |
| 3456 | Zinfandel | Rot | 2004 | Helena | |
| 2171 | Pinot Noir | Rot | 2001 | Creek | |
| 3478 | Pinot Noir | Rot | 1999 | Helena | |
| 4711 | Riesling Reserve | Weiß | 1999 | Müller | |
| 4961 | Chardonnay | Weiß | 2002 | Bighorn |
Kritik an RDBMS / SQL
- nicht skalierbar
- Normalisierung von Relationen, viele Integritätsbedingungen zu prüfen
- kann man in RDBMS auch vermeiden!
- starre Tabellen nicht flexibel genug
- schwach typisierte Tabellen (Tupel weichen in den tatsächlich genutzten Attributen ab) - viele Nullwerte wenn alle potentiellen Attribute definiert - alternativ Aufspaltung auf viele Tabellen - Schema-Evolution mit alter table unflexibel
- tatsächlich in vielen Anwendungen ein Problem
- Integration von spezifischen Operationen (Graphtraversierung, Datenanalyse-Primitive) mit Stored Procedures zwar möglich führt aber oft zu schwer interpretierbarem Code
NoSQL-Systeme
- Datenmodelle
- KV-Stores
- Wide Column Stores
- Dokumenten-orientierte Datenhaltung
- Graph-Speicher
- ...
- Anfragesprache -> unterschiedliche Ansätze:
- einfache funktionale API
- Programmiermodell für parallele Funktionen
- angelehnt an SQL-Syntax
- ...
- Beispiele
- dokumentenorientierte Datenbanksysteme: MongoDB
- semistrukturierte Dokumente in JSON- bzw. BSON-Format
- Anfragen: CRUD erweitert um dokumentspezifische Suche
- Graph-Datenbanksysteme: Neo4j
- Property Graphen als Datenmodell: Knoten und Kanten mit Eigenschaften
- Anfragesprache Cypher
- Muster der Form "Knoten -> Kante -> Knoten ..."
- dokumentenorientierte Datenbanksysteme: MongoDB
OLTP, OLAP und HTAP
OLTP vs OLAP
| Online Transactional Processing (OLTP) | Online Analytical Processing (OLAP) | |
|---|---|---|
| -> Klassische operative Informationssysteme | -> Data Warehouse | |
| Erfassung und Verwaltung von Daten | Analyse im Mittelpunkt = entscheidungsunterstützende Systeme | |
| Verarbeitung unter Verantwortung der jeweiligen Abteilung | Langandauernde Lesetransaktionen auf vielen Datensätzen | |
| Transaktionale Verarbeitung: kurze Lese-/ Schreibzugriffe auf wenigen Datensätzen | Integration, Konsolidierung und Aggregation der Daten | |
| ACID-Eigenschaften | ||
| Anfragen | ||
| Fokus | Lesen, Schreiben, Modifizieren, Löschen | Lesen, periodisches Hinzufügen |
| Transaktionsdauer und -typ | kurze Lese- / Schreibtransaktionen | langandauernde Lesetransaktionen |
| Anfragestruktur | einfach strukturiert | komplex |
| Datenvolumen einer Anfrage | wenige Datensätze | viele Datensätze |
| Datenmodell | anfrageflexibel | analysebezogen |
| Antwortzeit | msecs ...secs | secs ...min |
| Daten | ||
| Datenquellen | meist eine | mehrere |
| Eigenschaften | nicht abgeleitet, zeitaktuell, autonom, dynamisch | abgeleitet / konsolidiert, historisiert, integriert, stabil |
| Datenvolumen | MByte ...GByte | GByte ...TByte ...PByte |
| Zugriffe | Einzeltupelzugriff | Tabellenzugriff (spaltenweise) |
OLTP: Beispiel
BEGIN ;
SELECT KundenNr INTO KNr
FROM Kunden WHERE email = '...';
INSERT INTO BESTELLUNG VALUES (KNr, BestNr, 1);
UPDATE Artikel SET Bestand = Bestand-1
WHERE ArtNr = BestNr;
COMMIT TRANSACTION ;
OLAP: Beispiel
SELECT DISTINCT ROW Zeit.Dimension AS Jahr,
Produkt.Dimension AS Artikel,
AVG(Fact.Umsatz) AS Umsatzdurchschnitt,
Ort.Dimension AS Verkaufsgebiet
FROM (Produktgruppe INNER JOIN Produkt ON Produktgruppe.
[Gruppen-Nr] = Produkt.[Gruppen-ID]) INNER JOIN
((((Produkt INNER JOIN [Fact.Umsatz] ON Produkt.[Artikel-Nr]
= [Fact.Umsatz].[Artikel-Nr]) INNER JOIN Order ON
[Fact.Umsatz].[Bestell-Nr]= Order.[Order-ID]) INNER JOIN
Zeit.Dimension ON Orders.[Order-ID] =
Zeit.Dimension.[Order-ID]) INNER JOIN Ort.Dimension ON
Order.[Order-ID] = Ort.Dimension.[Order-ID]) ON
Produktgruppe.[Gruppen-Nr] = Produkt.[Gruppen-ID]
GROUP BY Produkt.Dimension.Gruppenname, Ort.Dimension.Bundesland,
Zeit.Dimension.Jahr;
HTAP
- HTAP = Hybrid Transactional and Analytics Processing
- Ziel: schnellere Geschäftsentscheidungen durch "Echtzeit"-Verarbeitung
- OLAP und OLTP auf der gleichen Datenbank: naheliegend aber große technische Herausforderung
- sehr unterschiedliche Workloads (Anfrage- und Lastprofile)
- Transaktionsverwaltung: gegenseitige Beeinflussung von Änderungs- und Leseoperationen reduzieren
- unterschiedliche Datenorganisation (physisch, logisch)
- Herausforderungen
- Analytical (OLAP) und Transactional processing (OLTP)
- verschiedene Zugriffscharakterisiken
- verschiedene Performance-Ziele (Latenz vs. Durchsatz)
- => Unterschiedliche Optimierungen notwendig
- Analytical (OLAP) und Transactional processing (OLTP)
Disk- vs. Main-Memory-Systeme**
Traditionelle Annahmen
- Daten sollen dauerhauft aufbewahrt werden
- Datenbank >> Hauptspeicher
- Disk >> Hauptspeicher
- Hauptspeicher = flüchtiger (volatiler) Speicher
- Disk-IO dominiert Kosten
Speicherhierarchie
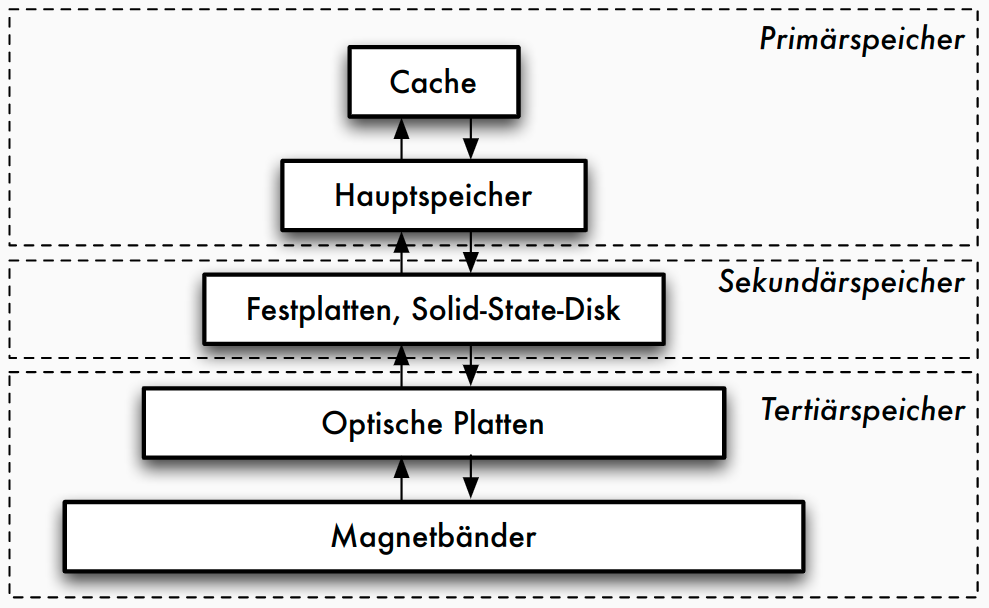
Eigenschaften von Speichermedien
| Primär | Sekundär | Tertiär | |
|---|---|---|---|
| Geschwindigkeit | schnell | langsam | sehr langsam |
| Preis | teuer | preiswert | billig |
| Stabilität | flüchtig | stabil | stabil |
| Größe | klein | groß | sehr groß |
| Granulate | fein | grob | grob |
Speichermedien
- Primärspeicher
- Primärspeicher: Cache und Hauptspeicher
- sehr schnell, Zugriff auf Daten fein granular: theoretisch jedes Byte adressierbar (Cachelines)
- Sekundärspeicher
- Sekundärspeicher oder Online-Speicher
- meist Plattenspeicher, nicht-flüchtig
- Granularität des Zugriffs gröber: Blöcke, oft 512 Bytes
- Zugriffslücke: Faktor 10^5 langsamerer Zugriff
- Tertiärspeicher
- Zur langfristigen Datensicherung (Archivierung) oder kurzfristigen Protokollierung (Journale)
- üblich: optische Platten, Magnetbänder
- "Offline-Speicher" meist Wechselmedium
- Nachteil: Zugriffslücke extrem groß
Transferraten HDD vs. SSD
![]()
Konsequenz für disk-basierte Systeme
- blockbasierter Zugriff mit typischen Blockgrößen ≥ 4 KB
- speziell für Magnetplatten Optimierung auf sequentielle Zugriffe - Disklayout: Organisation der Daten auf der Disk = fortlaufende Folge von Blöcken - sequentielles Lesen und Schreiben
- Zugriffslücke zwischen Hauptspeicher und Disk durch Caching verbergen (Lokalität von Zugriffen ausnutzen)
Main-Memory-Datenbanken
- klassische Annahmen nicht mehr zutreffend:
- Systeme mit Hauptspeicher im TB-Bereich verfügbar
- Datenbank kann komplett im Hauptspeicher gehalten werden (muss aber dennoch persistent sein)
- Main-Memory- oder Hauptspeicher- Datenbanken: Ausnutzung der großen Hauptspeicher und Multicore-Architekturen - Beispiele: SAP HANA, Oracle TimesTen, SQL Server Hekaton, Hyper, MemSQL, ... - Besonderheiten: hauptspeicheroptimierte Datenstrukturen (Main-Memory-Scans), Persistenz trotz volatilem Speicher, Datenkompression, Nebenläufigkeitskontrolle
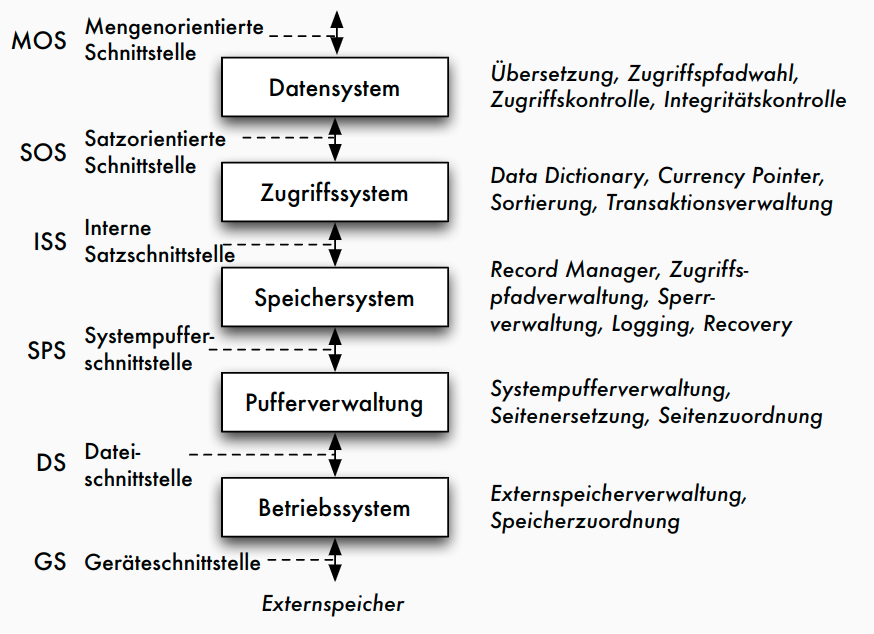
Klassische 5-Schichtenarchitektur
Fünf-Schichtenarchitektur
- Architektur für klassische DBMS
- basierend auf Idee von Senko 1973
- Weiterentwicklung von Härder 1987
- Umsetzung im Rahmen des IBM-Prototyps System R
- genauere Beschreibung der Transformationskomponenten
- schrittweise Transformation von Anfragen/Änderungen bis hin zu Zugriffen auf Speichermedien
- Definition der Schnittstellen zwischen Komponenten
5-Schichtenarchitektur: Funktionen
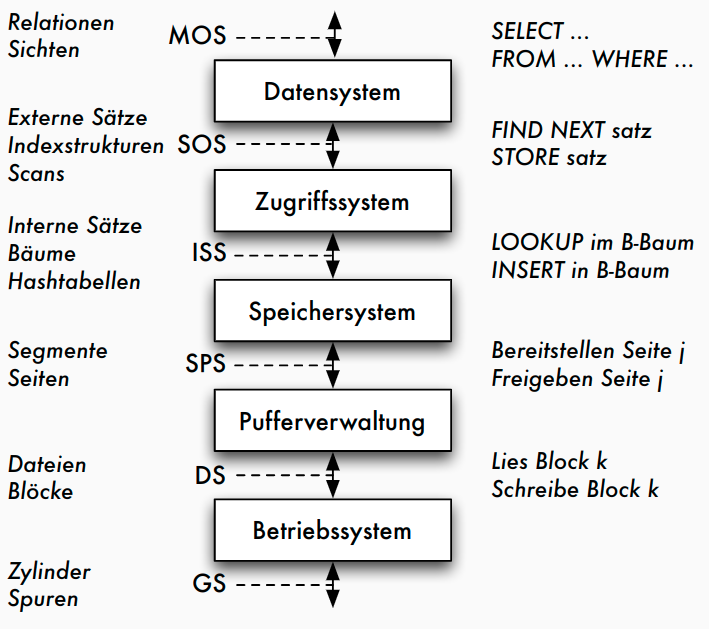
5-Schichtenarchitektur: Objekte
Erläuterungen
- mengenorientierte Schnittstelle MOS :
- deklarative Datenmanipulationssprache auf Tabellen und Sichten (etwa SQL)
- durch Datensystem auf satzorientierte Schnittstelle SOS umgesetzt: - navigierender Zugriff auf interner Darstellung der Relationen - manipulierte Objekte: typisierte Datensätze und interne Relationen sowie logische Zugriffspfade (Indexe) - Aufgaben des Datensystems: Übersetzung und Optimierung von SQL-Anfragen
- durch Zugriffssystem auf interne Satzschnittstelle ISS umgesetzt: - interne Tupel einheitlich verwalten, ohne Typisierung - Speicherstrukturen der Zugriffspfade (konkrete Operationen auf B+-Bäumen und Hashtabellen), Mehrbenutzerbetrieb mit Transaktionen
- durch Speichersystem Datenstrukturen und Operationen der ISS auf interne Seiten eines virtuellen linearen Adressraums umsetzen - Manipulation des Adressraums durch Operationen der Systempufferschnittstelle SPS - Typische Objekte: interne Seiten, Seitenadressen - Typische Operationen: Freigeben und Bereitstellen von Seiten, Seitenwechselstrategien, Sperrverwaltung, Schreiben des Logs
- durch Pufferverwaltung interne Seiten auf Blöcke der Dateischnittstelle DS abbilden - Umsetzung der DS-Operationen auf Geräteschnittstelle erfolgt durch BS
Neue Entwicklungen
Anforderungen aus neuen Anwendungen
- Nicht-Standard-Datenmodelle (siehe NoSQL-Systeme)
- flexibler Umgang mit Datenstrukturen (JSON, Schema on Read, ...)
- beschränkte (Lookups) vs. erweiterte (z.B. Graphoperationen, Datenanalysen) Anfragefunktionalität
- Skalierbarkeit zu Big Data (massiv parallele/verteilte Systeme)
- dynamische Daten / Datenströme
- ...
Entwicklungen im Hardware-Bereich
- Multicore- und Manycore-Prozessoren: 64+ Cores
- Nutzung erfordert Parallelisierungstechniken und Nebenläufigkeitskontrolle
- Memory Wall: Hauptspeicherzugriff als Flaschenhals
- RAM-Zugriff 60 ns, L1-Cache: 4 CPU-Zyklen -> Cache-optimierte Strukturen
- Datenbank-Accelerators
- Hardware-unterstütztes Datenmanagement: FPGA, GPU als Coprozessoren, Highspeed-Netzwerk, SSDs als zusätzliche Cache-Ebene, ...
- Persistenter Memory: nicht-volatiler Speicher
- Instant Restart / Recovery von Main-Memory-Datenbanken
Zusammenfassung
- Datenmanagementfunktionalitäten in vielen Softwaresystemen erforderlich
- nicht auf Implementierung kompletter DBMS beschränkt, sondern für nahezu alle datenintensiven Systeme: auch in Suchmaschinen, Datenanalyseanwendungen, eingebetteten Systemen, Visualisierungssystemen, Steuerungssystemen, Entwicklungsumgebungen, ...
- gemeinsame Aufgaben / Komponenten: Datenorganisation und -verwaltung (Indexstrukturen), Transaktionsverwaltung / Nebenläufigkeitskontrolle / Recovery, Anfrageverarbeitung
- betrifft Datenstrukturen und Algorithmen
Speicherstrukturen für Datenbanken
Speicher- und Sicherungsmedien
Speichermedien
- verschiedene Zwecke:
- Daten zur Verarbeitung bereitstellen
- Daten langfristig speichern (und trotzdem schnell verfügbar halten)
- Daten sehr langfristig und preiswert archivieren unter Inkaufnahme etwas längerer Zugriffszeiten
- Speicherhierarchie:
- Extrem schneller Prozessor mit Registern
- Sehr schneller Cache-Speicher
- Schneller Hauptspeicher
- Langsamer Sekundärspeicher mit wahlfreiem Zugriff
- Sehr langsamer Nearline-Tertiärspeicher bei dem die Speichermedien automatisch bereitgestellt werden
- Extrem langsamer Offline-Tertiärspeicher, bei dem die Speichermedien per Hand bereitgestellt werden
Zugriffslücke in Zahlen
- Zugriffslücke: Unterschiede in den Zugriffsgeschwindigkeiten auf den verschiedenen Speicherebenen
| Speicherart | Zugriffszeit | CPU cycles | typische Kapazität |
|---|---|---|---|
| CacheSpeicher | 6 ns | 12 | 256 KB (L2) bis 32 MB (L3) |
| Hauptspeicher | 60 ns | 120 | 1 GB bis 1.5 TB |
Zugriffslücke 10^5 |
|||
| Magnetplattenspeicher | 8-12 ms | 16*10^6 | 160 GB bis 4 TB |
| Platten-Farm oder -Array | 12 ms | 24*10^6 | im TB- bis PB-Bereich |
Typische Merkmale von Sekundärspeicher
| Merkmal | Kapazität | Latenz | Bandbreite |
|---|---|---|---|
| 1983 | 30 MB | 48.3 ms | 0.6 MB/s |
| 1994 | 4.3 GB | 12.7 ms | 9 MB/s |
| 2003 | 73.4 GB | 5.7 ms | 86 MB/s |
| 2009 | 2 TB | 5.1 ms | 95 MB/s |
| 2019 SSD (NVMe) | 2 TB | ?? | seq.read 3.500 MB/s |
| ?? | seq.write 1.600 MB/s |
Solid State Disk (SSD)
- basierend auf EEPROMs in NAND- oder NOR-Technologie
- Arrays (=Flash-Block mit ca. 128 KB) von Speicherzellen, entweder ein Bit (SLC) oder 2-4 Bit (MLC)
- MLC sind langsamer und haben verkürzte Lebensdauer
- initial ist jedes Bit auf 1 gesetzt, durch Reprogrammieren auf 0
- Löschen zurück auf 1 nur für ganzen Block
- Konsequenz: langsames Löschen (Lesen = 25 μs, Löschen = 2 ms), begrenzte Lebensdauer (ca. 100.000 Lösch-Schreib-Zyklen)
- Schnittstelle: SATA oder PCIe (NVMe)
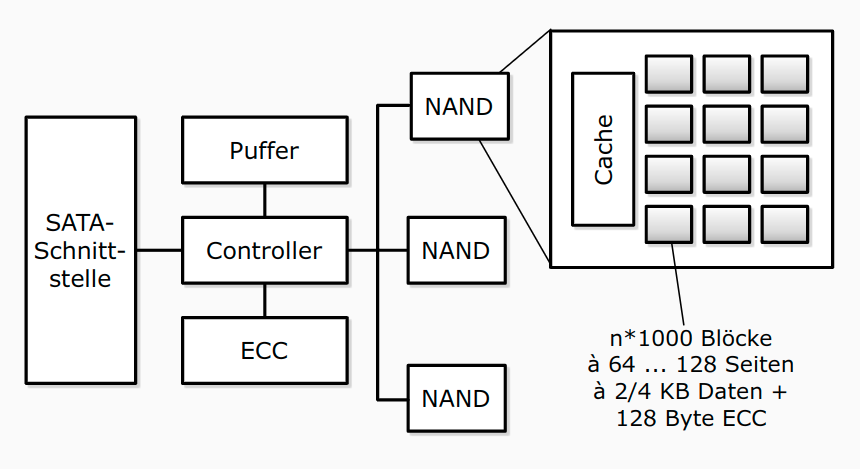
SSDs in DBMS
- klassische, auf sequenzielles Lesen ausgerichtete, Strategien von DBMS nutzen die Stärken von Flash-Speicher nicht aus
- kleinere Blockgrößen lassen sich effizient adressieren, sollten aber ein Vielfaches der Flash-Seiten sein
- wahlfreie Lesezugriffe sind effizienter als auf Magnetplatten, sollten aber auf Größen von ca. 4 bis 16 MB begrenzt werden
- konkurrierende IO-Zugriffe sind bis zu einem gewissen Maße ohne negativen Performanzeinfluss durchführbar
Speicherarrays: RAID
- Kopplung billiger Standardplatten unter einem speziellen Controller zu einem einzigen logischen Laufwerk
- Verteilung der Daten auf die verschiedenen physischen Festplatten übernimmt Controller
- zwei gegensätzliche Ziele:
- Erhöhung der Fehlertoleranz (Ausfallsicherheit, Zuverlässigkeit) durch Redundanz
- Effizienzsteigerung durch Parallelität des Zugriffs
Erhöhung der Fehlertoleranz
- Nutzung zusätzlicher Platten zur Speicherung von Duplikaten (Spiegeln) der eigentlichen Daten => bei Fehler: Umschalten auf Spiegelplatte
- bestimmte RAID-Levels (1, 0+1) erlauben eine solche Spiegelung
- Alternative: Kontrollinformationen wie Paritätsbits nicht im selben Sektor wie die Originaldaten, sondern auf einer anderen Platte speichern
- RAID-Levels 2 bis 6 stellen durch Paritätsbits oder Error Correcting Codes (ECC) fehlerhafte Daten wieder her
- ein Paritätsbit kann einen Plattenfehler entdecken und bei Kenntnis der fehlerhaften Platte korrigieren
Erhöhung der Effizienz
- Datenbank auf mehrere Platten verteilen, die parallel angesteuert werden können => Zugriffszeit auf große Datenmengen verringert sich fast linear mit der Anzahl der verfügbaren Platten
- Verteilung: bit-, byte- oder blockweise
- höhere RAID-Levels (ab Level 3) verbinden Fehlerkorrektur und block- oder bitweises Verteilen von Daten
- Unterschiede:
- schnellerer Zugriff auf bestimmte Daten
- höherer Durchsatz für viele parallel anstehende Transaktionen durch eine Lastbalancierung des Gesamtsystems
RAID-Levels
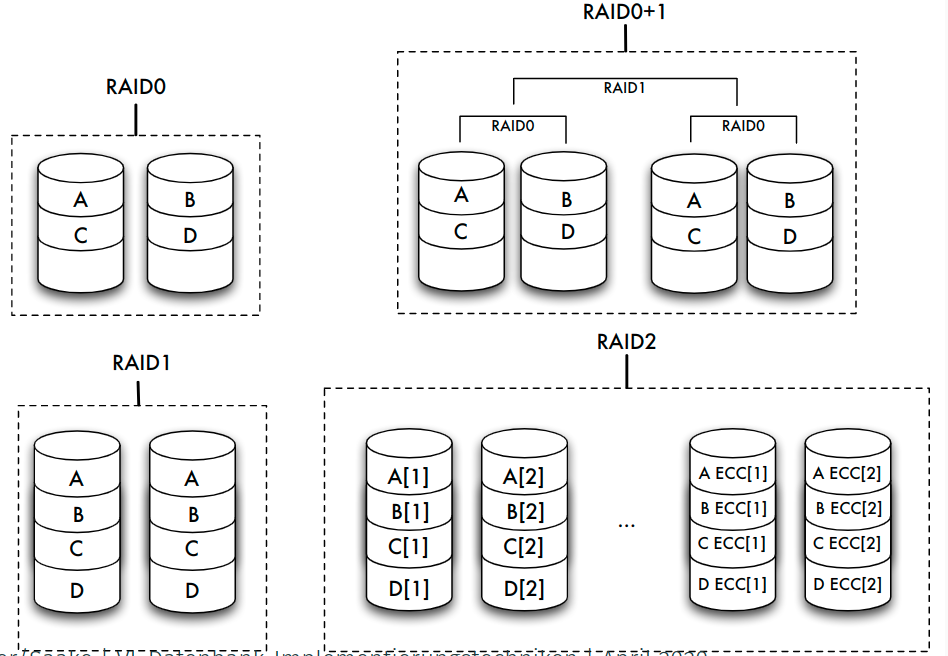
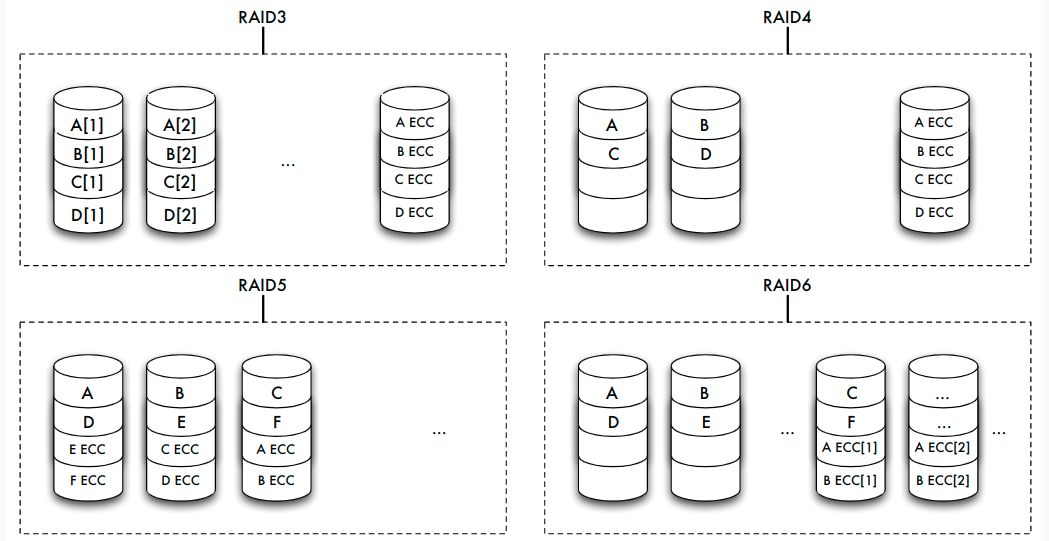
| Level | Striping blockweise | Striping bitweise | Kopie | Parität | Parität dedizierte Platte | Parität verteilt | Erkennen mehrerer Fehler |
|---|---|---|---|---|---|---|---|
| 0 | √ | ||||||
| 1 | √ | ||||||
| 0+1 | √ | √ | |||||
| 2 | √ | √ | |||||
| 3 | √ | √ | √ | ||||
| 4 | √ | √ | √ | ||||
| 5 | √ | √ | √ | ||||
| 6 | √ | √ | √ |
Sicherungsmedien: Tertiärspeicher
- weniger oft benutzte Teile der Datenbank, die eventuell sehr großen Umfang haben (Text, Multimedia) "billiger" speichern als auf Magnetplatten
- aktuell benutzte Datenbestände zusätzlich sichern (archivieren)
- Tertiärspeicher: Medium austauschbar
- offline: Medien manuell wechseln (optische Platten, Bänder)
- nearline: Medien automatisch wechseln (Jukeboxes, Bandroboter)
Langzeitarchivierung
- Lebensdauer, Teilaspekte:
- physische Haltbarkeit des Mediums garantiert die Unversehrtheit der Daten:
- 10 Jahre für Magnetbänder,
- 30 Jahre für optische Platten,
- Papier???
- Vorhandensein von Geräten und Treibern garantiert die Lesbarkeit von Daten:
- Geräte für Lochkarten oder 8-Zoll-Disketten?
- zur Verfügung stehende Metadaten garantieren die Interpretierbarkeit von Daten
- Vorhandensein von Programmen, die auf den Daten arbeiten können, garantieren die Wiederverwendbarkeit von Daten
Struktur des Hintergrundspeichers
Verwaltung des Hintergrundspeichers
- Abstraktion von Speicherungs- oder Sicherungsmediums
- Modell: Folge von Blöcken
- Alternativen:
- jede Relation oder jeder Zugriffspfad in genau einer Betriebssystem-Datei
- ein oder mehrere BS-Dateien, DBS verwaltet Relationen und Zugriffspfade selbst innerhalb dieser Dateien
- DBS steuert selbst Magnetplatte an und arbeitet mit den Blöcken in ihrer Ursprungsform ( raw device )
- Warum nicht immer BS-Dateiverwaltung?
- Betriebssystemunabhängigkeit
- In 32-Bit-Betriebssystemen: Dateigröße 4 GB maximal
- BS-Dateien auf maximal einem Medium
- betriebssystemseitige Pufferverwaltung von Blöcken des Sekundärspeichers im Hauptspeicher genügt nicht den Anforderungen des Datenbanksystems
Blöcke und Seiten
- Zuordnung der physischen Blöcke zu Seiten
- meist mit festen Faktoren: 1, 2, 4 oder 8 Blöcke einer Spur auf eine Seite
- hier: "ein Block — eine Seite"
- höhere Schichten des DBS adressieren über Seitennummer
Dienste des Dateisystems
- Allokation oder Deallokation von Speicherplatz
- Holen oder Speichern von Seiteninhalten
- Allokation möglichst so, dass logisch aufeinanderfolgende Datenbereiche (etwa einer Relation) auch möglichst in aufeinanderfolgenden Blöcken der Platte gespeichert werden
- Nach vielen Update-Operationen: Reorganisationsmethoden
- Freispeicherverwaltung: doppelt verkettete Liste von Seiten
Abbildung der Datenstrukturen
- Abbildung der konzeptuellen Ebene auf interne Datenstrukturen
- Unterstützung durch Metadaten (im Data Dictionary, etwa das interne Schema)
| Konz. Ebene | Interne Ebene | Dateisystem/Platte |
|---|---|---|
| Relationen -> | Log. Dateien -> | Phys. Dateien |
| Tupel -> | Datensätze -> | Seiten/Blöcke |
| Attributwerte -> | Felder -> | Bytes |
- Beispiel: jede Relation in je einer logischen Datei, diese insgesamt in einer einzigen physischen Datei
Seiten, Sätze und Adressierung
Seite
- Block:
- kleinste adressierbare Einheit auf Externspeicher
- Zuordnung zu Seiten im Hauptspeicher
- Aufbau von Seiten
- Header
- Informationen über Vorgänger- und Nachfolger-Seite
- eventuell auch Nummer der Seite selbst
- Informationen über Typ der Sätze
- freier Platz
- Datensätze
- unbelegte Bytes
- Header
Seitenorganisation
- Organisation der Seiten: doppelt verkettete Liste
- freie Seiten in Freispeicherverwaltung
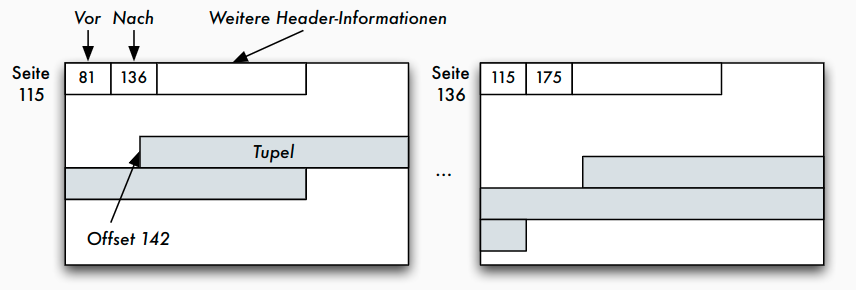
Seite: Adressierung der Datensätze
- adressierbare Einheiten
- Zylinder
- Spuren
- Sektoren
- Blöcke oder Seiten
- Datensätze in Blöcken oder Seiten
- Datenfelder in Datensätzen
- Beispiel: Adresse eines Satzes durch Seitennummer und Offset (relative Adresse in Bytes vom Seitenanfang)
Seitenzugriff als Flaschenhals
- Maß für die Geschwindigkeit von Datenbankoperationen: Anzahl der Seitenzugriffe auf dem Sekundärspeicher (wegen Zugriffslücke)
- Faustregel: Geschwindigkeit des Zugriffs ⇐ Qualität des Zugriffspfades ⇐ Anzahl der benötigten Seitenzugriffe
- Hauptspeicheroperationen nicht beliebig vernachlässigbar
Einpassen von Datensätzen auf Blöcke
- Datensätze (eventuell variabler Länge) in die aus einer fest vorgegebenen Anzahl von Bytes bestehenden Blöcke einpassen: Blocken
- Blocken abhängig von variabler oder fester Feldlänge der Datenfelder - Datensätze mit variabler Satzlänge: höherer Verwaltungsaufwand beim Lesen und Schreiben, Satzlänge immer wieder neu ermitteln - Datensätze mit fester Satzlänge: höherer Speicheraufwand
Verschiedene Satztypen
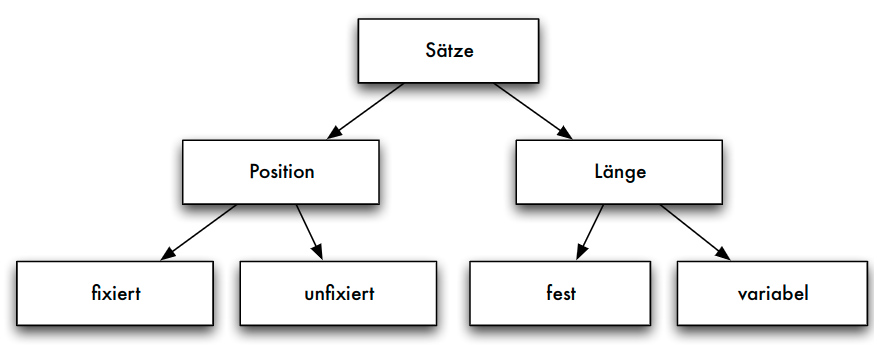
Sätze fester Länge
- SQL: Datentypen fester und variabler Länge
- char(n) Zeichenkette der festen Länge n
- varchar(n) Zeichenkette variabler Länge mit der Maximallänge n
- Aufbau der Datensätze, falls alle Datenfelder feste Länge:
- Verwaltungsblock mit Typ eines Satzes (wenn unterschiedliche Satztypen auf einer Seite möglich) und Löschbit
- Freiraum zur Justierung des Offset
- Nutzdaten des Datensatzes
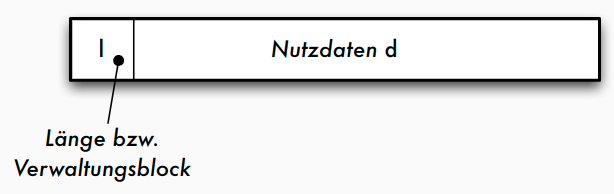
Sätze variabler Länge
- im Verwaltungsblock nötig: Satzlänge l, um die Länge des Nutzdaten-Bereichs d zu kennen
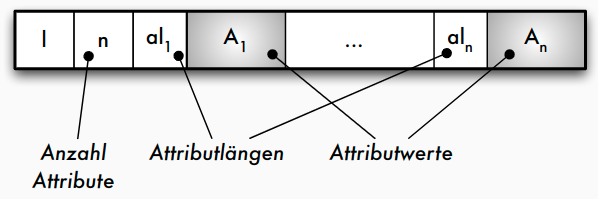
- Strategie a)
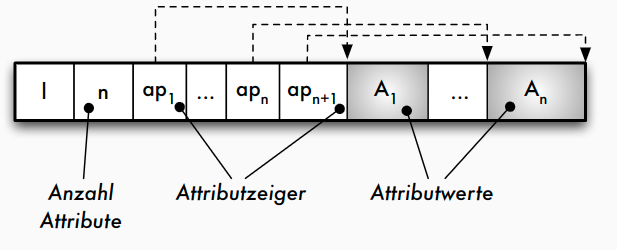
- Strategie b)
Speicherung von Sätzen variabler Länge
- Strategie a): Jedes Datenfeld variabler Länge
A_ibeginnt mit einem _Längenzeigeral_i, der angibt, wie lang das folgende Datenfeld ist - Strategie b): Am Beginn des Satzes wird nach dem Satz-Längenzeiger l und der Anzahl der Attribute ein Zeigerfeld
ap_1 ,..., ap_nfür alle variabel langen Datenfelder eingerichtet - Vorteil Strategie b): leichtere Navigation innerhalb des Satzes (auch für Sätze in Seiten => TID)
Anwendung variabel langer Datenfelder
- "Wiederholgruppen": Liste von Werten des gleichen Datentyps
- Zeichenketten variabler Länge wie varchar(n) sind Wiederholgruppe mit char als Basisdatentyp, mathematisch also die Kleene’sche Hülle $(char)∗$
- Mengen- oder listenwertige Attributwerte, die im Datensatz selbst denormalisiert gespeichert werden sollen (Speicherung als geschachtelte Relation oder Cluster-Speicherung), bei einer Liste von integer -Werten wäre dies $(integer)∗$
- Adressfeld für eine Indexdatei, die zu einem Attributwert auf mehrere Datensätze zeigt (Sekundärindex), also
(pointer)∗
Blockungstechniken: Nichtspannsätze
- jeder Datensatz in maximal einem Block
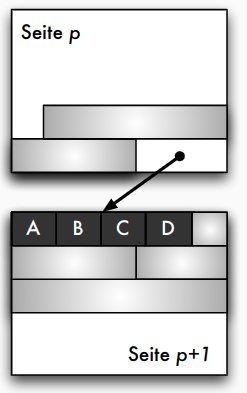
- Standardfall (außer bei BLOBs oder CLOBs)
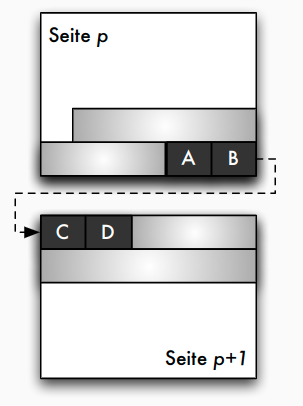
Blockungstechniken: Spannsätze
- Spannsätze: Datensatz eventuell in mehreren Blöcken
Adressierungstechniken

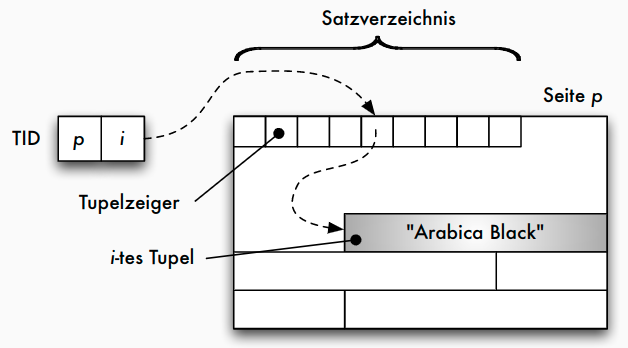
Adressierung: TID-Konzept
- Tupel-Identifier (TID) ist Datensatz-Adresse bestehend aus Seitennummer und Offset
- Offset verweist innerhalb der Seite bei einem Offset-Wert von i auf den i -ten Eintrag in einer Liste von Tupelzeigern (Satzverzeichnis), die am Anfang der Seite stehen
- Jeder Tupel-Zeiger enthält Offsetwert
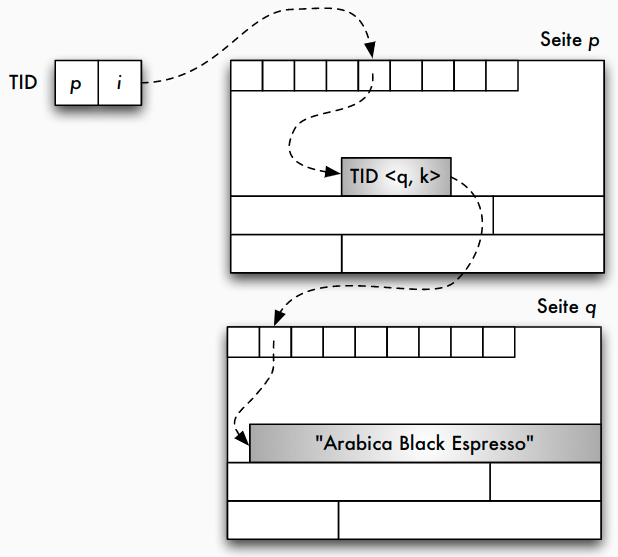
- Verschiebung auf der Seite: sämtliche Verweise von außen bleiben unverändert
- Verschiebungen auf eine andere Seite: statt altem Datensatz neuer TID-Zeiger
- diese zweistufige Referenz aus Effizienzgründen nicht wünschenswert: Reorganisation in regelmäßigen Abständen
TID-Konzept: einstufige Referenz
TID-Konzept: zweistufige Referenz
Alternative Speichermodelle
- bisher klassisches N-äres Speichermodell (NSM), auch "row store"
- Vorteile:
- gesamter Datensatz kann mit einem Seitenzugriff gelesen werden
- leichte Änderbarkeit einzelner Attributwerte
- Nachteil:
- werden nur wenige Attributwerte benötigt, müssen trotzdem immer alle Attributwerte gelesen werden -> unnötiger IO-Aufwand
- Alternativen: spaltenorientierte Speichermodelle
- Zerlegung einer n -stelligen Relation in eine Menge von Projektionen (z.B. binäre Relation)
- Identifikation (und Rekonstruktion) über eine Schlüsselspalte oder Position
Spaltenorientierte Datenorganisation

Alternative Speichermodelle: DSM
- Decomposition Storage Model (DSM) -> column stores
- alle Werte einer Spalte (Attribut) werden hintereinander gespeichert
- Adressierung über Position
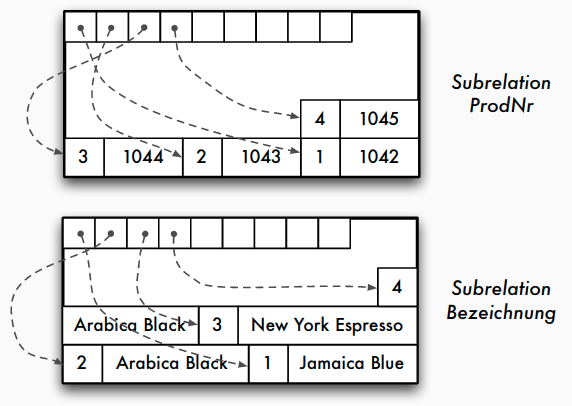
- Kompression einfach möglich (z.B. Run length encoding)
- effizientere Scanoperationen (Feldoperationen -> bessere Cache-Nutzung)
- jedoch: Updateoperationen sind komplexer, Lesen aller Spalten aufwendiger
- Einsatz bei leseoptimierten Datenbanken
Ein Full-Table-Scan in NSM
- Im NSM-Modell stehen alle Tupel einer Tabelle sequenziell hintereinander auf einer Datenbankseite.
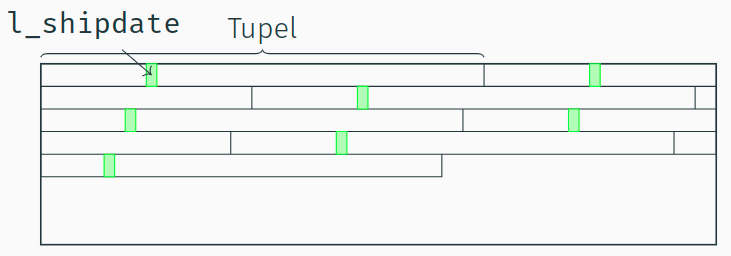
Ein "Full-Table-Scan" in DSM
- Im DSM-Modell stehen alle Werte eines Attributs sequenziell hintereinander auf einer Datenbankseite.

- Alle Daten, die für den "l_shipdate Scan" geladen werden sind auch dafür relevant.
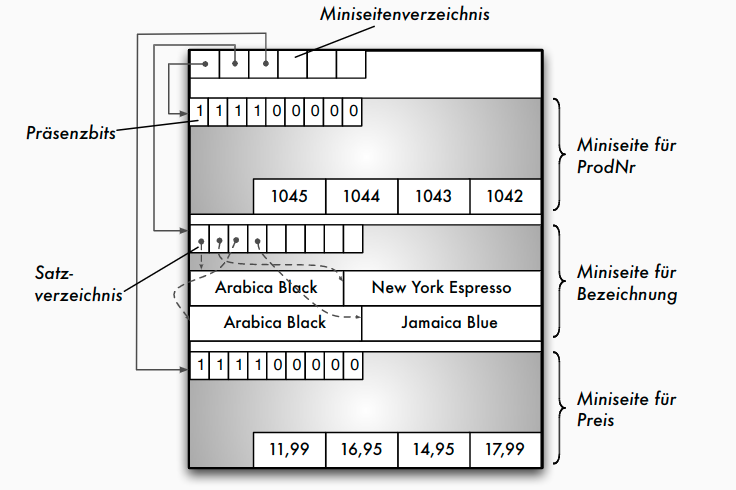
Alternative Speichermodelle: PAX
- Partition Attributes Across (PAX) als Kompromiss
- NSM: alle Spalten eines Satzes auf der gleichen Seite
- DSM: vertikale Partitionierung, Miniseiten für jeweils eine Spalte
Main-Memory-Strukturen
Speicherstrukturen für Main-Memory-Datenbanken
- Vermeidung der seiten-basierten Indirektion (über Seitenadresse, Puffer)
- Hauptspeicherzugriffe als neuer Bottleneck ("Memory Wall")
- Cache-freundliche Datenstruktur: Hauptspeicherzugriffe tatsächlich nicht byteweise, sondern in Cachelines (64 Bytes)
- Speicherlayout: Row Store vs. Column Store - abhängig vom Workload (Reduzierung der Cache Misses)
- ggf. Partitionierung für Multicore-Systeme
- Kompression der Daten zur Reduktion des Speicherbedarfs
- Persistenz weiterhin notwendig, z.B. über Logging
- Bsp.: In-Memory-Datenstruktur für relationale Column Stores - pro Spalte = Feld von Attributwerten - Kompression der Attributwerte (siehe Kapitel 8) - ggf. Strukturierung in Segmemten (Chunks) für bessere Speicherverwaltung, NUMA-Effekte
Speicherorganisation in konkreten DBMS
Oracle: Datenbankstruktur
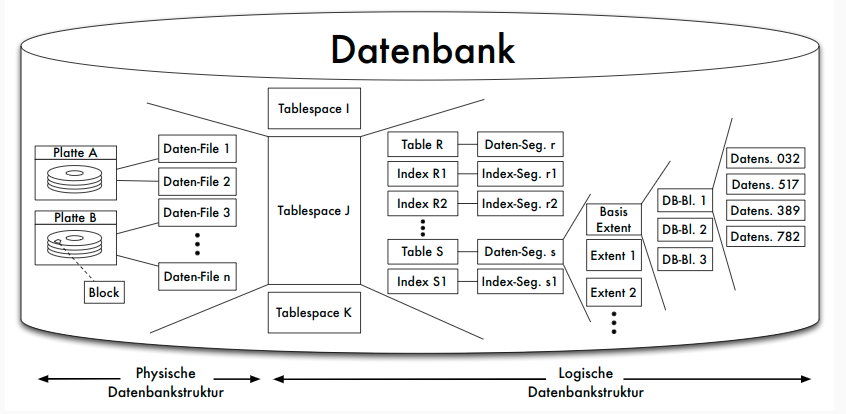
Oracle: Blöcke
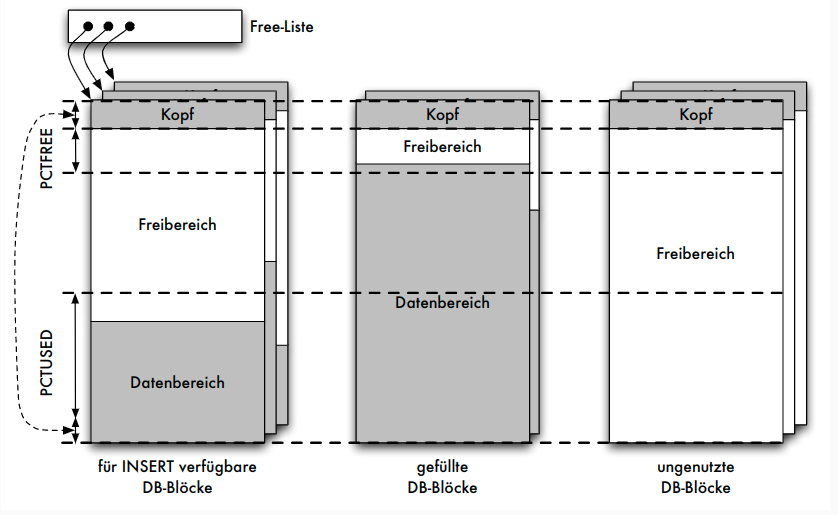
Oracle: Aufbau von Datensätzen
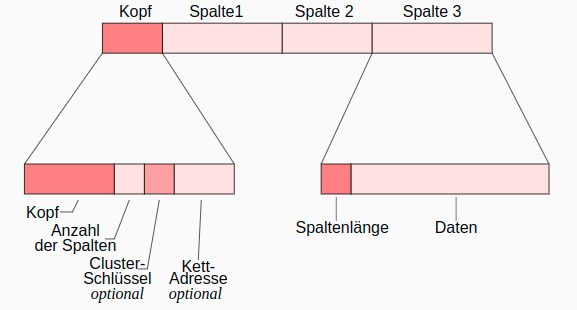
- Kettadresse für Row Chaining : Verteilung und Verkettung zu großer Datensätze (> 255 Spalten) über mehrere Blöcke
- row id = (data object identifier, data file identifier, block identifier, row identifier)
Zusammenfassung
- Speicherhierarchie und Zugriffslücke
- Speicher- und Sicherungsmedien
- Hintergrundspeicher: Blockmodell
- Einpassen von Sätzen in Seiten
- Satzadressierung: TID-Konzept
Caching und Pufferverwaltung
Aufgaben
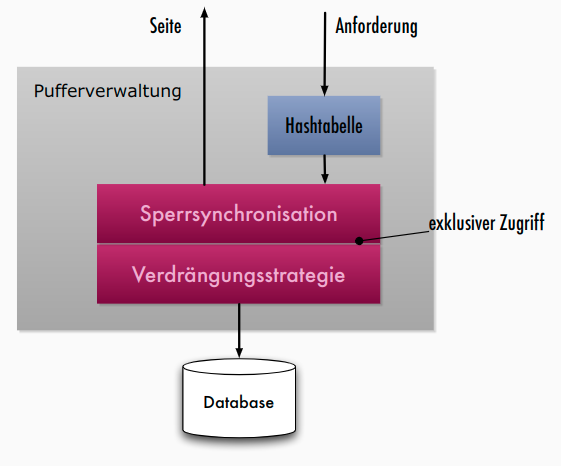
Aufgaben der Pufferverwaltung
- Puffer: ausgezeichneter Bereich des Hauptspeichers
- in Pufferrahmen gegliedert, jeder Pufferrahmen kann Seite der Platte aufnehmen
- Aufgaben:
- Pufferverwaltung muss angeforderte Seiten im Puffer suchen => effizienteSuchverfahren
- parallele Datenbanktransaktionen: geschickte Speicherzuteilung im Puffer
- Puffer gefüllt: adäquate Seitenersetzungsstrategien
- Unterschiede zwischen einem Betriebssystem-Puffer und einem Datenbank-Puffer
- spezielle Anwendung der Pufferverwaltung: Schattenspeicherkonzept
Mangelnde Eignung des BS-Puffers
- Natürlicher Verbund von Relationen
aundb(zugehörige Folge von Seiten: Ai bzw. Bj ) - Implementierung: Nested-Loop
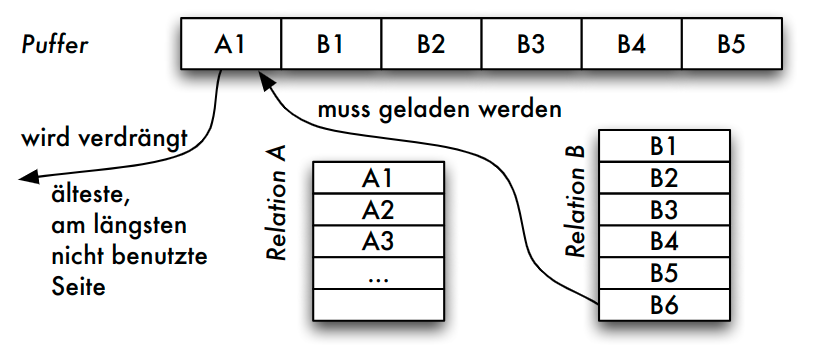
- Ablauf
- FIFO:
A_1verdrängt, da älteste Seite im Puffer - LRU:
A_1verdrängt, da diese Seite nur im ersten Schritt beim Auslesen des ersten Vergleichstupels benötigt wurde
- FIFO:
- Problem
- im nächsten Schritt wird das zweite Tupel von
A_1benötigt - weiteres "Aufschaukeln": um
A_1laden zu können, mussB_1entfernt werden (im nächsten Schritt benötigt) usw.
- im nächsten Schritt wird das zweite Tupel von
Suche von Seiten und Speicherzuteilung
Suchen einer Seite
- Direkte Suche:
- ohne Hilfsmittel linear im Puffer suchen
- Indirekte Suche:
- Suche nur noch auf einer kleineren Hilfsstruktur
- unsortierte und sortierte Tabelle : alle Seiten im Puffer vermerkt
- verkettete Liste : schnelleres sortiertes Einfügen möglich
- Hashtabelle : bei geschickt gewählter Hashfunktion günstigster Such- und Änderungsaufwand
Speicherzuteilung im Puffer
- bei mehreren parallel anstehenden Transaktionen
- Lokale Strategien: Jeder Transaktion bestimmte disjunkte Pufferteile verfügbar machen (Größe statisch vor Ablauf der Transaktionen oder dynamisch zur Programmlaufzeit entscheiden)
- Globale Strategien: Zugriffsverhalten aller Transaktionen insgesamt bestimmt Speicherzuteilung (gemeinsam von mehreren Transaktionen referenzierte Seiten können so besser berücksichtigt werden)
- Seitentypbezogene Strategien: Partition des Puffers: Pufferrahmen für Datenseiten, Zugriffspfadseiten, Data-Dictionary-Seiten, usw. - eigene Ersetzungstrategien für die jeweiligen Teile möglich
Seitenersetzungsstrategien
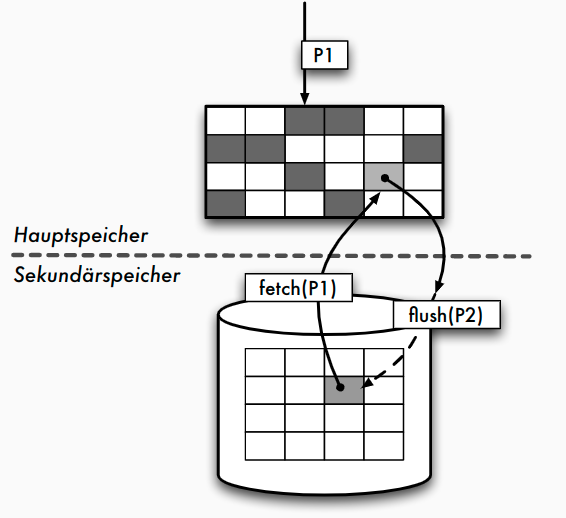
- Speichersystem fordert Seite
E_2an, die nicht im Puffer vorhanden ist - Sämtliche Pufferrahmen sind belegt
- vor dem Laden von E 2 Pufferrahmen freimachen
- nach den unten beschriebenen Strategien Seite aussuchen
- Ist Seite in der Zwischenzeit im Puffer verändert worden, so wird sie nun auf Platte zurückgeschrieben
- Ist Seite seit Einlagerung in den Puffer nur gelesen worden, so kann sie überschrieben werden (verdrängt)
Seitenersetzung in DBMS
- Fixieren von Seiten (Pin oder Fix):
- Fixieren von Seiten im Puffer verhindert das Verdrängen
- speziell für Seiten, die in Kürze wieder benötigt werden
- Freigeben von Seiten (Unpin oder Unfix):
- Freigeben zum Verdrängen
- speziell für Seiten, die nicht mehr benötigt werden
- Zurückschreiben einer Seite:
- Auslösen des Zurückschreibens für geänderte Seiten bei Transaktionsende
Seitenersetzung: Verfahren
- grundsätzliches Vorgehen beim Laden einer Seite:
- Demand-paging-Verfahren: genau eine Seite im Puffer durch angeforderte Seite ersetzen
- Prepaging-Verfahren: neben der angeforderten Seite auch weitere Seiten in den Puffer einlesen, die eventuell in der Zukunft benötigt werden (z.B. bei BLOBs sinnvoll)
- Ersetzen einer Seite im Puffer:
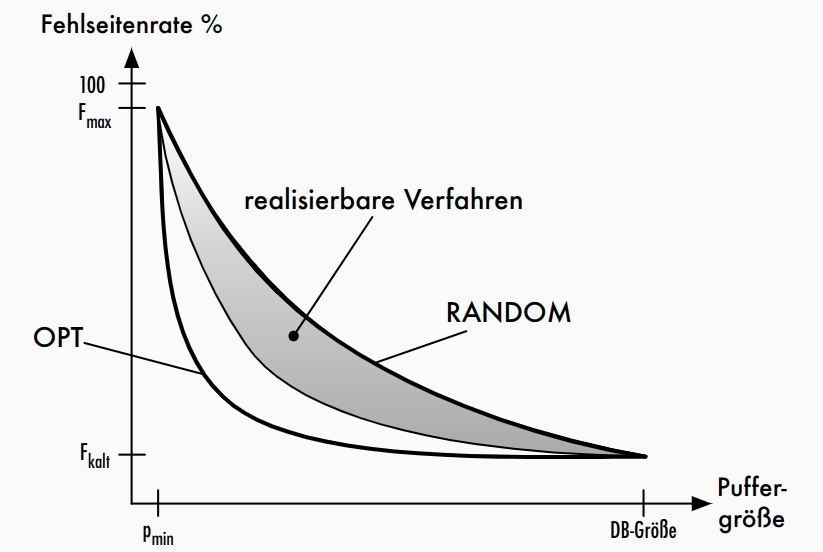
- optimale Strategie: Welche Seite hat maximale Distanz zu ihrem nächsten Gebrauch? (nicht realisierbar, zukünftiges Referenzverhalten nicht vorhersehbar) -> Realisierbare Verfahren besitzen keine Kenntnisse über das zukünftige Referenzverhalten
- Zufallsstrategie: jeder Seite gleiche Wiederbenutzungswahrscheinlichkeit zuordnen
Fehlseitenrate
F=1-p(\frac{1-F_{kalt}}{p_{DB}}) * 100%-
p: Puffergröße -
p_{DB}: Puffergröße, die gesamte Datenbank umfasst -
F_{kalt}: Fehlseitenrate beim Kaltstart (d.h. leerer Puffer) -> Verhältnis von Anzahl der in den Puffer geladenen Seiten zur Anzahl der Referenzierungen -
Gute, realisierbare Verfahren sollen vergangenes Referenzverhalten auf Seiten nutzen, um Erwartungswerte für Wiederbenutzung schätzen zu können - besser als Zufallsstrategie - Annäherung an optimale Strategie
Merkmale gängiger Strategien
- Alter der Seite im Puffer:
- Alter einer Seite nach Einlagerung (die globale Strategie (G))
- Alter einer Seite nach dem letztem Referenzzeitpunkt (die Strategie des jüngsten Verhaltens (J))
- Alter einer Seite wird nicht berücksichtigt (-)
- Anzahl der Referenzen auf Seite im Puffer:
- Anzahl aller Referenzen auf eine Seite (die globale Strategie (G))
- Anzahl nur der letzten Referenzen auf eine Seite (die Strategie des jüngsten Verhaltens (J))
- Anzahl der Referenzen wird nicht berücksichtigt (-)
Gängige Strategien
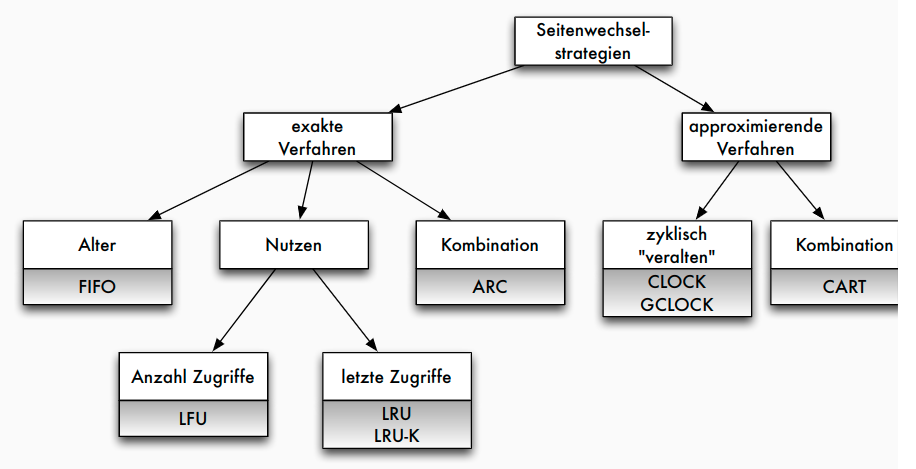
Klassifikation gängiger Strategien | Verfahren | Prinzip | Alter | Anzahl | | -------------------------------- | ------------------------------------------------------------------- | ----- | | FIFO | älteste Seite ersetzt | G | - | | LFU (least fre-quently used) | Seite mit geringster Häufigkeit ersetzen | - | G | | LRU (least recently used) | Seite ersetzen, die am längsten nicht referenziert wurde (System R) | J | J | | DGCLOCK (dyn. generalized clock) | Protokollierung der Ersetzungshäufigkeiten wichtiger Seiten | G | JG | | LRD (least reference density) | Ersetzung der Seite mit geringster Referenzdichte | JG | G |
Beispiel
- Folge von Seitenanforderungen #1, #2 ...
- Puffer der Größe 6

- Ablauf mit
- FIFO ...
- LFU ...
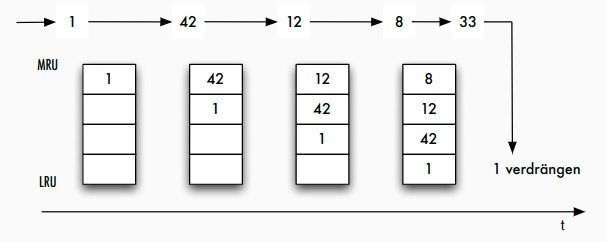
LRU: Least Recently Used
- Idee: Seite im Puffer ersetzen, die am längsten nicht mehr referenziert wurde
- Implementierung:
- Liste oder Stack von Seiten
- Puffer-Hit bewegt Seite zur MRU-Position (Most Recently Used)
- Seite am Ende wird verdrängt
- Varianten:
- durch Interpretation der Pin-Operation: Least Recently Referenced bzw. Least Recently Unfixed
- durch Berücksichtigung der letzten
kReferenzierungen (d.h. auch Häufigkeit): LRU-K
LRU: Probleme
- Lock Contention in Multitasking-Umgebungen
- Zugriff auf LRU-Liste/Stack und Bewegung der Seite erfordert exklusiven Zugriff auf Datenstruktur
- aufwendige Operation
- berücksichtigt nur Alter jedoch nicht Häufigkeit
- oft gelesene Seiten mit langen Pausen zwischen den Zugriffen werden nicht adäquat berücksichtigt
- "Zerstörung" des Puffers durch Scan-Operator
- Seiten werden nur einmalig gelesen, verdrängen jedoch andere (ältere) Seiten
Lock Contention bei der Pufferverwaltung
- Sperren = Latches: leichtgewichtige (wenige CPU-Instruktionen) Objekte für kurzzeitige Sperren
Approximierende Verfahren
- Idee:
- Vereinfachung der benötigten Datenstruktur durch Approximation
- Effektivität (Trefferrate) vs. Skalierbarkeit (Anzahl der Threads)
- CLOCK: Approximation der Historie durch Bit-Schieberegister der Länge $k$
-
k= 0: FIFO -k\rightarrow\infty: LRU - typisch:k = 1
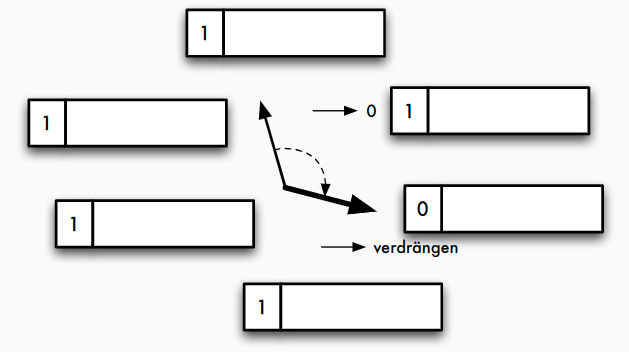
CLOCK
- Seite mit Benutzt-Bit; bei Referenzierung auf "1" setzen
- bei Seitenfehler:
- zyklische Suche
- Seite mit "0" verdrängen
- sonst Setzen auf "0"
GCLOCK
- Verbesserung: Benutzt-Bit durch Referenzzähler RC ersetzen; Dekrementierung bei Suche
- weitere Verbesserungen:
- Initialisierung des Referenzzählers
- Inkrementierung des Zählers
- seitentypspezifische Maßnahmen (für Typ i : Seitengewicht
E_ibei Erstreferenzierung,W_ibei weiterer Referenzierung) - Altern
- Varianten: Seite j von Typ i
GCLOCK(V1): RC_j := E_i ; RC_j := RC_j + W_iGCLOCK(V2): RC_j := E_i ; RC_j := W_i(speziell fürW_i\geq E_i)
DGCLOCK
- weitere Verbesserung: globaler Zähler
GCund Normierung der aktuellen ReferenzzählerRC- Initialisierung:
RC_j := GC - Referenzierung von Seite
j : GC := GC + 1 ; RC_j := RC_j + GC - bei Überschreiten
GC > MIN : \forall j : RC_j := RC_j / C
- Initialisierung:
ARC
- Adaptive Replacement Cache: neues Verfahren, das Nachteile von LRU vermeidet
- Prinzip:
- Puffergröße c
- Pufferverzeichnis für 2 c Seiten: c Pufferseiten + c History-Seiten
- Liste L 1 : "recency" = kurzfristiger Nutzen-> Seiten, die kürzlich einmal gelesen wurden
- Liste L 2 : "frequency" = langfristiger Nutzen -> Seiten, die kürzlich mehrmals gelesen wurden
- Ausgangspunkt: einfache Verdrängungsstrategie DBL(2 c )
- Ersetze die LRU-Seite in
L_1, wenn|L_1| = c, sonst ersetze LRU-Seite inL_2 - Ziel: Größenausgleich zwischen
L_1undL_2 - Zugriff Seite
p: wenn Treffer ->pwird MRU inL_2, sonst inL_1
- Ersetze die LRU-Seite in
Von DBL(2c) zu ARC

- Parameter
pmit0\leq p \leq cT_1enthältpSeiten,T_2enthältc-pSeiten
- Wahl von
p?
ARC: Algorithmus
- Seitenanforderungen:
x_1,x_2 ,..., x_t ,... p = 0, T_1 , B_1 , T_2 ,B_2sind initial leer- Fall 1:
x_t \in T_1 \cup T_2/* Puffer-Hit */- Bewege
x_tzu MRU vonT_2
- Bewege
- Fall 2:
x_t \in B_1- Anpassung:
p = min\{ p +\delta_1,c\}mit\delta_1 = \begin{cases} 1\quad\text{ wenn } |B_1|\geq |B_2| \\ \frac{|B_2|}{|B_1|} \quad\text{ sonst}\end{cases} REPLACE(x_t,p)- Bewege
x_tvonB_1zu MRU vonT_2
- Anpassung:
- Fall 3:
x_t \in B_2- Anpassung:
p = max\{ p - \delta_2, 0 \}mit\delta_2 = \begin{cases} 1\quad\text{ wenn } |B_2|\geq |B_1| \\ \frac{|B_1|}{|B_2|} \quad\text{ sonst}\end{cases} REPLACE(x_t,p)- Bewege
x_tvonB_2zu MRU vonT_2
- Anpassung:
- Fall 4:
x_t \not\in T_1 \cup B_1 \cup T_2 \cup B_2- 4.A:
|L_1| = c- Wenn
|T_1|<c, lösche LRU inB_1,REPLACE(x_t,p) - sonst /*
B_1 = \varnothing*/ lösche LRU inT_1
- Wenn
- 4.B:
|L_1|<c- Wenn
|L_1|+|L_2|\geq c, lösche LRU inB_2,REPLACE(x_t,p)
- Wenn
- Bewege
x_tzu MRU inT_1
- 4.A:
- Fall 1:
ARC: REPLACE(x_t, p)
if $|T_1|>p$ oder ($x_t\in B_2$ und $|T_1|=p$)
Lösche LRU-Seite in $T_1$ und bewege sie zu MRU in $B_1$
else
Lösche LRU-Seite in $T_2$ und bewege sie zu MRU in $B_2$
endif
ARC: Beispiel
- erstmalige Anforderung der Seiten
#1und#2: Aufnahme in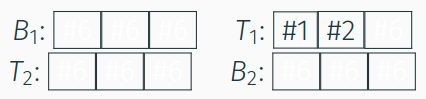
- nächsten Referenzierung von
#1: Übernahme in $T_2$-Liste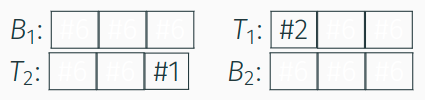
- Seitenanforderungen
#3,#4,#1; mit#2wird diese inT_2bewegt; Platz für Seite#5: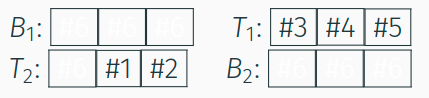
- Beantwortung der Seitenanforderungen
#1und#2ausT_2 - neu angeforderten Seiten
#5und#6in $T_1$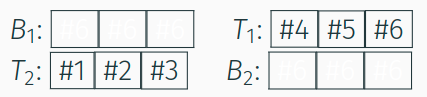
- Seitenanforderung
#7: Verdrängen von#4ausT_1in $B_1$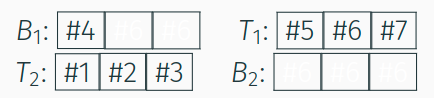
ARC: Eigenschaften
- kontinuierliche Anpassung von Parameter
p- Lernraten
\delta_1und\delta_2 - "Investieren in Liste mit dem meisten Profit"
- Lernraten
- Berücksichtigung von Alter und Häufigkeit
- durch zwei Listen
L_1undL_2
- durch zwei Listen
- Scan-Resistenz
- einmalig gelesene Seiten nur in
L_1, niemals inL_2
- einmalig gelesene Seiten nur in
- Vermeidung von Lock Contention durch approximierende Varianten (CAR, CART, ...)
Fazit
- Pufferverwaltungsstrategie mit großem Einfluss auf Performance
- in kommerziellen Systemen meist LRU mit Variationen
- besondere Behandlung von Full-Table-Scans
- weiterer Einflussfaktor: Puffergröße
- Indikator: Trefferrate (engl. hit ratio )
$$hit\_ratio = \frac{\text{Anz. log. Zugriffe} - \text{Anz. phys. Zugriffe}}{\text{Anz. log. Zugriffe - 5-Minuten-Regel (Gray, Putzolu 1997): Daten, die in den nächsten 5 Min. wieder referenziert werden, sollten im Hauptspeicher gehalten werden
Indexierung von Daten
Klassifikation der Speichertechniken
Einordnung in 5-Schichten-Architektur
- Speichersystem fordert über Systempufferschnittstelle Seiten an
- interpretiert diese als interne Datensätze
- interne Realisierung der logischen Datensätze mit Hilfe von Zeigern, speziellen Indexeinträgen und weiteren Hilfsstrukturen
- Zugriffssystem abstrahiert von der konkreten Realisierung
Klassifikation der Speichertechniken
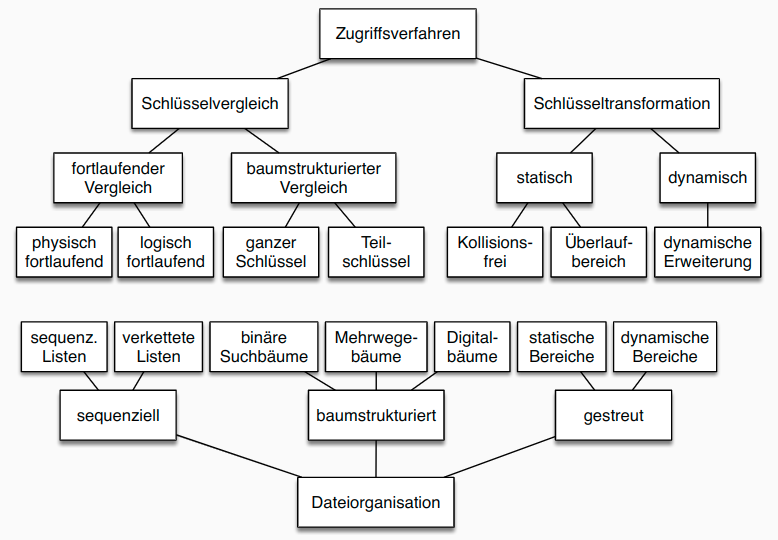
- Kriterien für Zugriffsstrukturen oder Zugriffsverfahren:
- organisiert interne Relation selbst (Dateiorganisationsform) oder zusätzliche Zugriffsmöglichkeit auf bestehende interne Relation (Zugriffspfad)
- Art der Zuordnung von gegebenen Attributwerten zu Datensatz-Adressen: Schlüsselvergleich = Zuordnung von Schlüsselwert zu Adresse über Hilfsstruktur; Schlüsseltransformation = Berechnung der Adresse aus Schlüsselwert (z.B. über Hashfunktion)
- Arten von Anfragen, die durch Dateiorganisationsformen und Zugriffspfade effizient unterstützt werden können
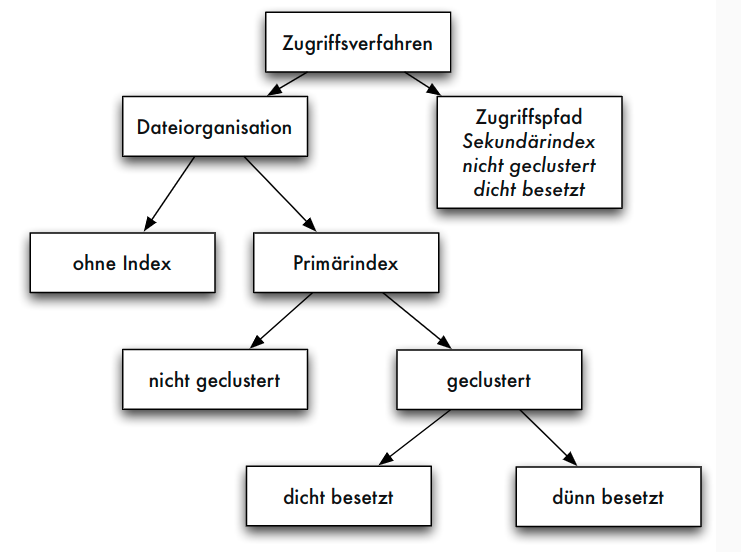
Dünn- vs. dichtbesetzter Index
- dünnbesetzter Index: nicht für jeden Zugriffsattributwert
kein Eintrag in Indexdatei sondern z.B. nur für Seitenanführer einer sortierten Relation - dichtbesetzter Index: für jeden Datensatz der internen Relation ein Eintrag in Indexdatei
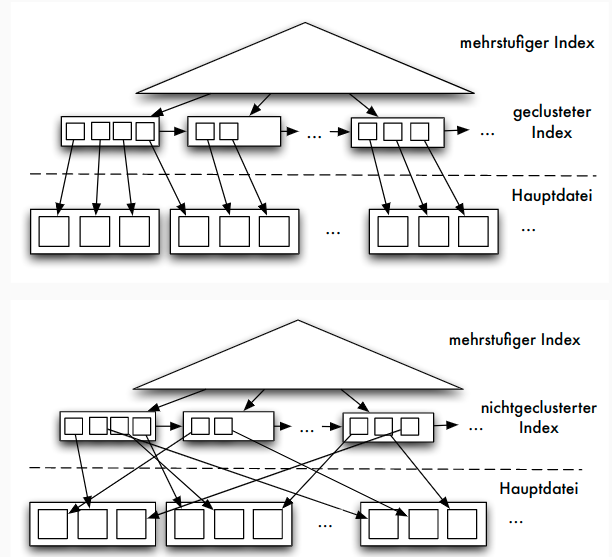
Geclusterter vs. nicht-geclusterter Index
- geclusterter Index: in der gleichen Form sortiert wie interne Relation
- nicht-geclusterter Index: anders organisiert als interne Relation
- Primärindex oft dünnbesetzt und geclustert
- jeder dünnbesetzte Index ist auch geclusterter Index, aber nicht umgekehrt
- Sekundärindex kann nur dichtbesetzter, nicht-geclusterter Index sein (auch: invertierte Datei)
Statische vs. dynamische Struktur
- statische Zugriffsstruktur: optimal nur bei bestimmter (fester) Anzahl von verwaltenden Datensätzen
- dynamische Zugriffsstruktur: unabhängig von der Anzahl der Datensätze optimal - dynamische Adresstransformationsverfahren verändern dynamisch Bildbereich der Transformation - dynamische Indexverfahren verändern dynamisch Anzahl der Indexstufen => in DBS üblich
Klassifikation
Statische Verfahren
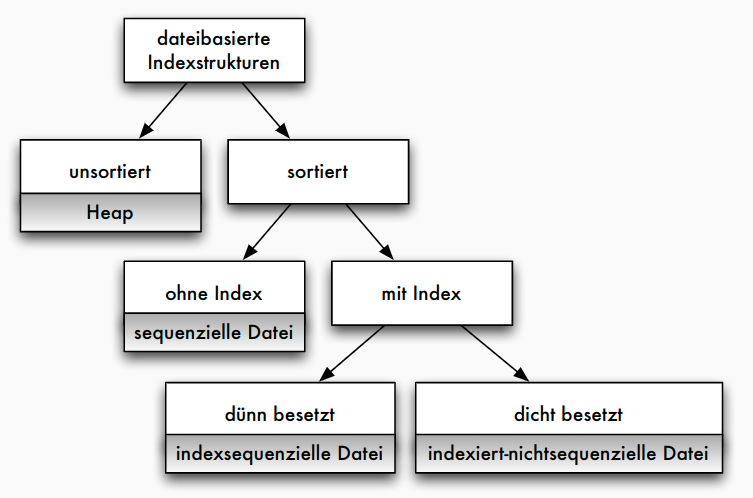
- Heap, indexsequenziell, indiziert-nichtsequenziell
- oft grundlegende Speichertechnik in RDBS
- direkte Organisationsformen: keine Hilfsstruktur, keine Adressberechnung (Heap, sequenziell)
- statische Indexverfahren für Primärindex und Sekundärindex
Statische Verfahren: Überblick
Heap
Organisation
- völlig unsortiert speichern
- physische Reihenfolge der Datensätze ist zeitliche Reihenfolge der Aufnahme von Datensätzen
8832 Max Mustermann ... 9.1.2003 5588 Beta Alpha ... 7.3.1978 4711 Gamma Delta ... 2.5.1945
Operationen
- insert: Zugriff auf letzte Seite der Datei. Genügend freier Platz => Satz anhängen. Sonst nächste freie Seite holen
- delete: lookup, dann Löschbit auf 0 gesetzt
- lookup: sequenzielles Durchsuchen der Gesamtdatei, maximaler Aufwand (Heap-Datei meist zusammen mit Sekundärindex eingesetzt; oder für sehr kleine Relationen)
- Komplexitäten:
- Neuaufnahme von Daten
O(1) - Suchen
O(n)
- Neuaufnahme von Daten
Sequenzielle Speicherung
- sortiertes Speichern der Datensätze
4711 Gamma Delta ... 2.5.1945 5588 Beta Alpha ... 7.3.1978 8832 Max Mustermann ... 9.1.2003
Sequenzielle Datei: Operationen
- insert: Seite suchen, Datensatz einsortieren => beim Anlegen oder sequenziellen Füllen einer Datei jede Seite nur bis zu gewissem Grad (etwa 66%) füllen
- delete: Aufwand bleibt
- Folgende Dateiorganisationsformen:
- schnelleres lookup
- mehr Platzbedarf (durch Hilfsstrukturen wie Indexdateien)
- mehr Zeitbedarf bei insert und delete
- klassische Indexform: indexsequenzielle Dateiorganisation
Indexsequenzielle Dateiorganisation
- Kombination von sequenzieller Hauptdatei und Indexdatei: indexsequenzielle Dateiorganisationsform
- Indexdatei kann geclusterter, dünnbesetzter Index sein
- mindestens zweistufiger Baum
- Blattebene ist Hauptdatei (Datensätze)
- jede andere Stufe ist Indexdatei
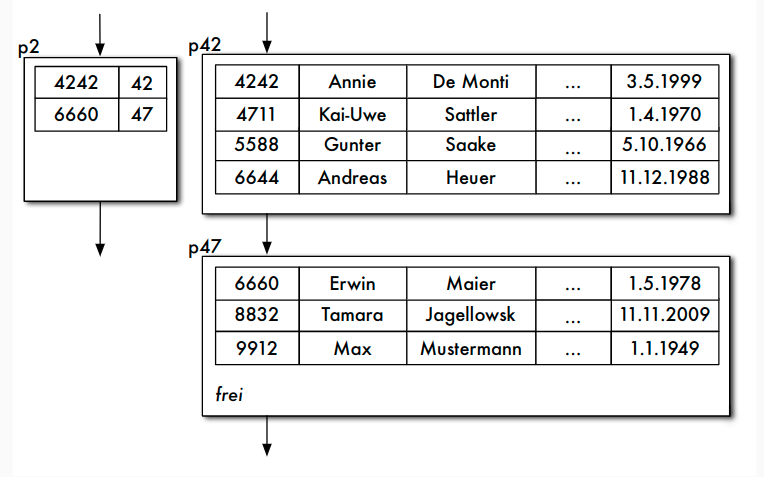
Aufbau der Indexdatei
- Datensätze in Indexdatei: (Primärschlüsselwert, Seitennummer) zu jeder Seite der Hauptdatei genau ein Index-Datensatz in Indexdatei
- Problem: "Wurzel" des Baumes bei einem einstufigen Index nicht nur eine Seite
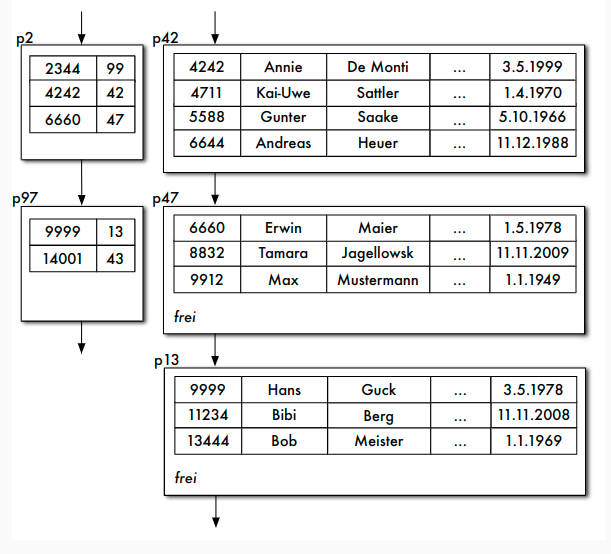
Mehrstufiger Index
- Optional: Indexdatei wieder indexsequenziell verwalten
- Idealerweise: Index höchster Stufe nur noch eine Seite
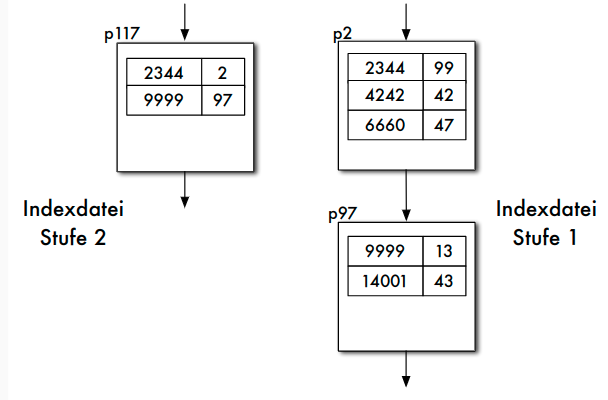
lookup bei indexsequenziellen Dateien
- lookup-Operation sucht Datensatz zum Zugriffsattributwert w
- Indexdatei sequenziell durchlaufen, dabei
(v_1,s)im Index gesucht mitv_1\leq w:(v_1,s)ist letzter Satz der Indexdatei, dann kann Datensatz zu w höchstens auf dieser Seite gespeichert sein (wenn er existiert)- nächster Satz
(v_2,s′)im Index hatv_2 > w, also muss Datensatz zu w, wenn vorhanden, auf Seite s gespeichert sein
(v_1,s)überdeckt Zugriffsattributwert w
insert bei indexsequenziellen Dateien
- insert: zunächst mit lookup Seite finden
- Falls Platz, Satz sortiert in gefundener Seite speichern; Index anpassen, falls neuer Satz der erste Satz in der Seite
- Falls kein Platz, neue Seite von Freispeicherverwaltung holen; Sätze der "zu vollen" Seite gleichmäßig auf alte und neue Seite verteilen; für neue Seite Indexeintrag anlegen
- Alternativ neuen Datensatz auf Überlaufseite zur gefundenen Seite
delete bei indexsequenziellen Dateien
- delete: zunächst mit lookup Seite finden
- Satz auf Seite löschen (Löschbit auf 0)
- erster Satz auf Seite: Index anpassen
- Falls Seite nach Löschen leer: Index anpassen, Seite an Freispeicherverwaltung zurück
Probleme indexsequenzieller Dateien
- stark wachsende Dateien: Zahl der linear verketteten Indexseiten wächst; automatische Anpassung der Stufenanzahl nicht vorgesehen
- stark schrumpfende Dateien: nur zögernde Verringerung der Index- und Hauptdatei-Seiten
- unausgeglichene Seiten in der Hauptdatei (unnötig hoher Speicherplatzbedarf, zu lange Zugriffszeit)
Indiziert-nichtsequenzieller Zugriffspfad
- zur Unterstützung von Sekundärschlüsseln
- mehrere Zugriffpfade dieser Form pro Datei möglich
- einstufig oder mehrstufig: höhere Indexstufen wieder indexsequenziell organisiert
Aufbau der Indexdatei
- Sekundärindex, dichtbesetzter und nicht-geclusteter Index
- zu jedem Satz der Hauptdatei Satz
(w,s)in der Indexdatei - w Sekundärschlüsselwert, s zugeordnete Seite
- entweder für ein w mehrere Sätze in die Indexdatei aufnehmen
- oder für ein w Liste von Adresse in der Hauptdatei angeben
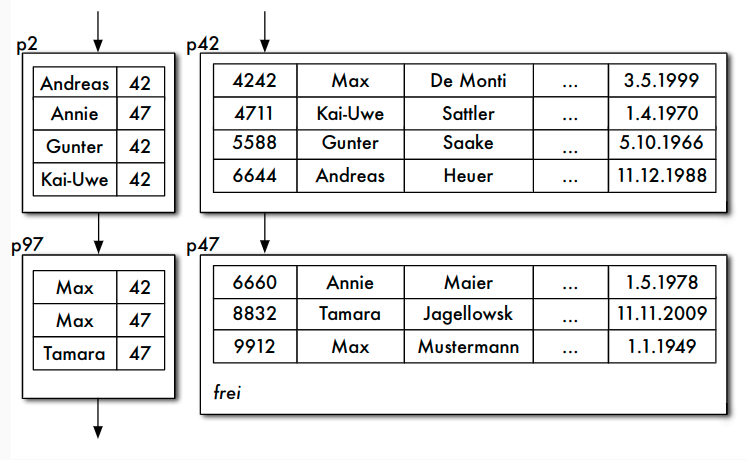
Operationen
- lookup: w kann mehrfach auftreten, Überdeckungstechnik nicht benötigt
- insert: Anpassen der Indexdateien
- delete: Indexeintrag entfernen
Probleme statischer Verfahren
- unzureichende Anpassung an wachsende/schrumpfende Datenmengen
- schlechte Ausnutzung von Speicher nach Seitensplits
- Bevorzugung bestimmter Attribute (Schlüssel)
- daher in den folgenden Kapiteln:
- bessere Datenstrukturen zur Schlüsselsuche als zusätzlicher Zugriffspfad = Approximation einer Funktion Schlüssel -> Speicheradresse, z.B. über Baumverfahren
- Erweiterung von Hashverfahren um Anpassung des Bildbereichs = dynamische Hashverfahren
- Behandlung von zusammengesetzten Schlüsseln = multidimensionale Zugriffsverfahren, z.B. multidimensionale Bäume oder raumfüllende Kurven
Baumbasierte Indexstrukturen
Baumverfahren
- Stufenanzahl dynamisch verändern
- wichtigste Baumverfahren: B-Bäume und ihre Varianten
- B-Baum-Varianten sind noch "allgegenwärtiger" in heutigen Datenbanksystemen als SQL
- SQL nur in der relationalen und objektrelationalen Datenbanktechnologie verbreitet; B-Bäume überall als Grundtechnik eingesetzt
Baumverfahren: Überblick
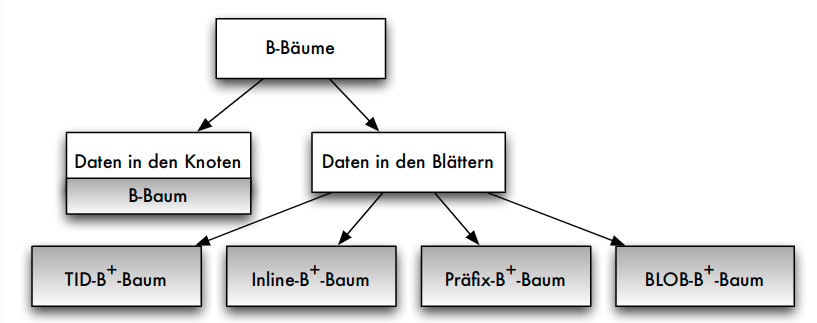
B-Bäume
- Ausgangspunkt: ausgeglichener, balancierter Suchbaum
- Ausgeglichen oder balanciert: alle Pfade von der Wurzel zu den Blättern des Baumes gleich lang
- Hauptspeicher-Implementierungsstruktur: binäre Suchbäume, beispielsweise AVL-Bäume von Adelson-Velskii und Landis
- Datenbankbereich: Knoten der Suchbäume zugeschnitten auf Seitenstruktur des Datenbanksystems
- mehrere Zugriffsattributwerte auf einer Seite
- Mehrwegebäume
Prinzip des B-Baumes
- B-Baum von Bayer (B für balanciert, breit, buschig, Bayer, NICHT: binär)
- dynamischer, balancierter Indexbaum, bei dem jeder Indexeintrag auf eine Seite der Hauptdatei zeigt
- Mehrwegebaum völlig ausgeglichen, wenn
- alle Wege von Wurzel bis zu Blättern gleich lang
- jeder Knoten gleich viele Indexeinträge
- vollständiges Ausgleichen zu teuer, deshalb B-Baum-Kriterium:
Jede Seite außer der Wurzelseite enthält zwischen
mund2mEinträge.
Definition B-Baum
- Ordnung eines B-Baumes ist minimale Anzahl der Einträge auf den Indexseiten außer der Wurzelseite
- Bsp.: B-Baum der Ordnung 8 fasst auf jeder inneren Indexseite zwischen 8 und 16 Einträgen
- Def.: Ein Indexbaum ist ein B-Baum der Ordnung
m, wenn er die folgenden Eigenschaften erfüllt:- Jede Seite enthält höchstens
2mElemente. - Jede Seite, außer der Wurzelseite, enthält mindestens
mElemente. - Jede Seite ist entweder eine Blattseite ohne Nachfolger oder hat
i+1Nachfolger, fallsidie Anzahl ihrer Elemente ist. - Alle Blattseiten liegen auf der gleichen Stufe.
- Jede Seite enthält höchstens
Eigenschaften des B-Baumes
nDatensätze in der Hauptdatei => inlog_m(n)Seitenzugriffen von der Wurzel zum Blatt- Durch Balancierungskriterium wird Eigenschaft nahe an der vollständigen Ausgeglichenheit erreicht (1. Kriterium vollständig erfüllt, 2. Kriterium näherungsweise)
- Kriterium garantiert 50% Speicherplatzausnutzung
- einfache, schnelle Algorithmen zum Suchen, Einfügen und Löschen von Datensätzen (Komplexität von
O(log_m(n)))
Suchen in B-Bäumen
- lookup wie in statischen Indexverfahren
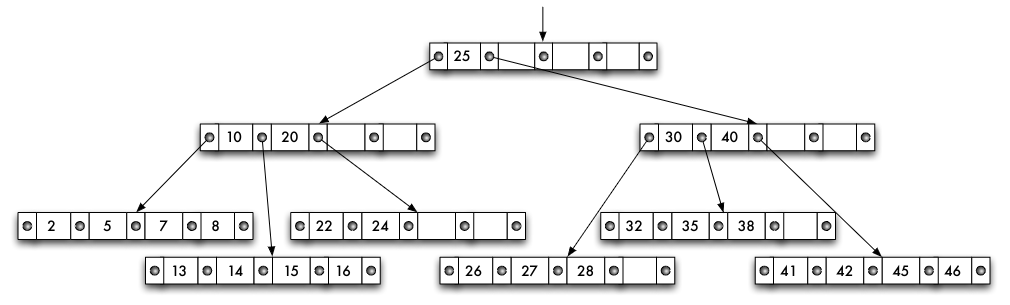
- Startend auf Wurzelseite Eintrag im B-Baum ermitteln, der den gesuchten Zugriffsattributwert
wüberdeckt => Zeiger verfolgen, Seite nächster Stufe laden - Suchen: 38, 20, 6
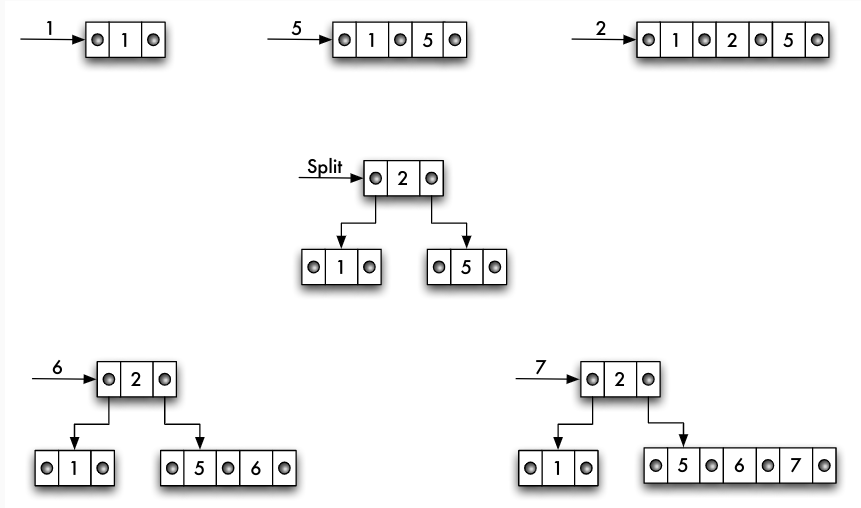
Einfügen in B-Bäumen
- Einfügen eines Wertes w
- mit lookup entsprechende Blattseite suchen
- passende Seite
n<2mElemente, w einsortieren - passende Seite
n=2mElemente, neue Seite erzeugen,- ersten m Werte auf Originalseite
- letzten m Werte auf neue Seite
- mittleres Element auf entsprechende Indexseite nach oben
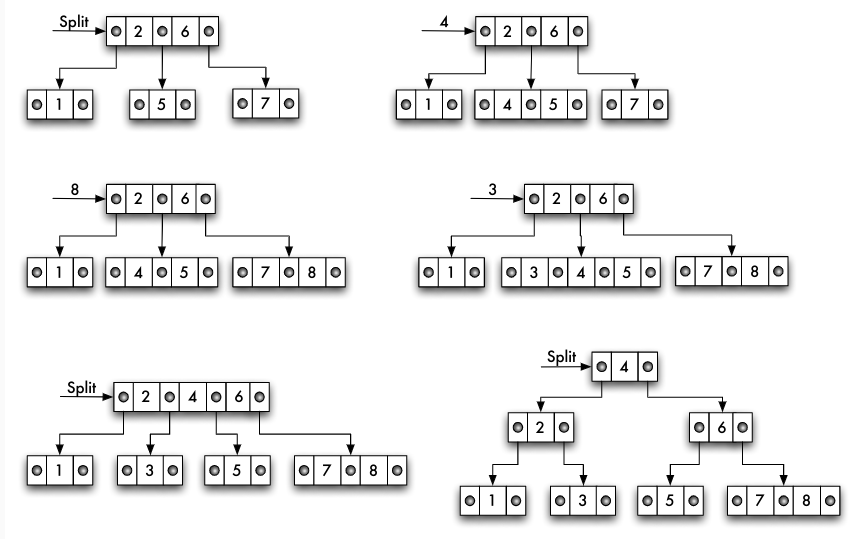
- eventuell dieser Prozess rekursiv bis zur Wurzel
Einfügen in einen B-Baum: Beispiel
Löschen in B-Bäumen
- bei weniger als
mElementen auf Seite: Unterlauf - Löschen eines Wertes
w: Bsp.: 24; 28, 38, 35- mit lookup entsprechende Seite suchen
wauf Blattseite gespeichert => Wert löschen, eventuell Unterlauf behandelnwnicht auf Blattseite gespeichert => Wert löschen, durch lexikographisch nächstkleineres Element von einer Blattseite ersetzen, eventuell auf Blattseite => Unterlauf
- Unterlaufbehandlung
- Ausgleichen mit der benachbarten Seite (benachbarte Seite
nElemente mitn>m) - oder Zusammenlegen zweier Seiten zu einer (Nachbarseite
n=mElemente), das "mittlere" Element von Indexseite darüber dazu, auf Indexseite eventuell => Unterlauf
- Ausgleichen mit der benachbarten Seite (benachbarte Seite
- Einfügen des Elementes 22; Löschen von 22
Komplexität der Operationen
- Aufwand beim Einfügen, Suchen und Löschen im B-Baum immer
O(log_m(n))Operationen - entspricht genau der "Höhe" des Baumes
- Konkret: Seiten der Größe 4 KB, Zugriffsattributwert 32 Bytes, 8-Byte-Zeiger: zwischen 50 und 100 Indexeinträge pro Seite; Ordnung dieses B-Baumes 50
- 1.000.000 Datensätze:
log_{50}(1000000) = 4Seitenzugriffe im schlechtesten Fall - Wurzelseite jedes B-Baumes normalerweise im Puffer: 3 Seitenzugriffe
B+-Baum
Varianten
- B+-Bäume: nur Blattebene enthält Daten -> Baum ist hohl
- B∗-Bäume: Aufteilen von Seiten vermeiden durch "Shuffle"
- Präfix-B-Bäume: Zeichenketten als Zugriffsattributwerte, nur Präfix indexieren
B+-Baum: Motivation
- B-Baum: Wie/wo werden Nicht-Schlüsseldaten (Tupel, TIDs) gespeichert?
- Zusammen mit Schlüsseln in allen Knoten?
- Problem beim Traversieren des Baumes, z.B. bei Bereichsanfragen
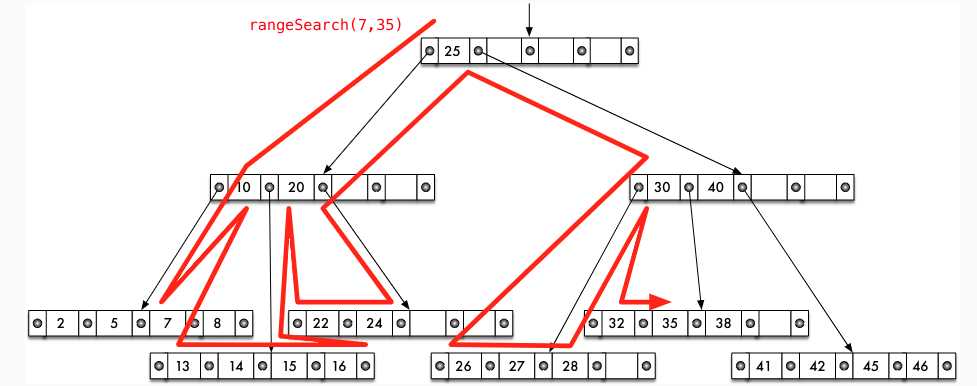
B+-Baum
- in der Praxis am häufigsten eingesetzte Variante des B-Baumes: - effizientere Änderungsoperationen, insb. Löschen - Verringerung der Baumhöhe
- Änderungen gegenüber B-Baum
- in inneren Knoten nur noch Zugriffsattributwert und Zeiger auf nachfolgenden Seite der nächsten Stufe; nur Blattknoten enthalten neben Zugriffsattributwert die Daten (Datensätze bzw. Verweise auf Datensätze in der Hauptdatei)
- Knoten der Blattebene sind untereinander verkettet für effiziente Unterstützung von Bereichsanfragen
B+-Baum: Aufbau
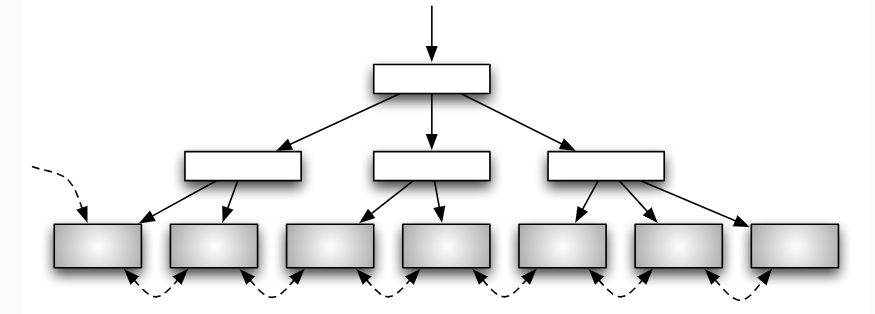
Ordnung; Operationen
- Ordnung für B+-Baum:
(x,y), xMindestbelegung der Indexseiten,yMindestbelegung der Blattseiten - delete gegenüber B-Baum effizienter ("Ausleihen" eines Elementes von der Blattseite entfällt)
- Zugriffsattributwerte in inneren Knoten können sogar stehenbleiben
- häufig als Primärindex eingesetzt
- B+-Baum ist dynamische, mehrstufige, indexsequenziellen Datei
B+-Baum: Blattebene mit Verweisen
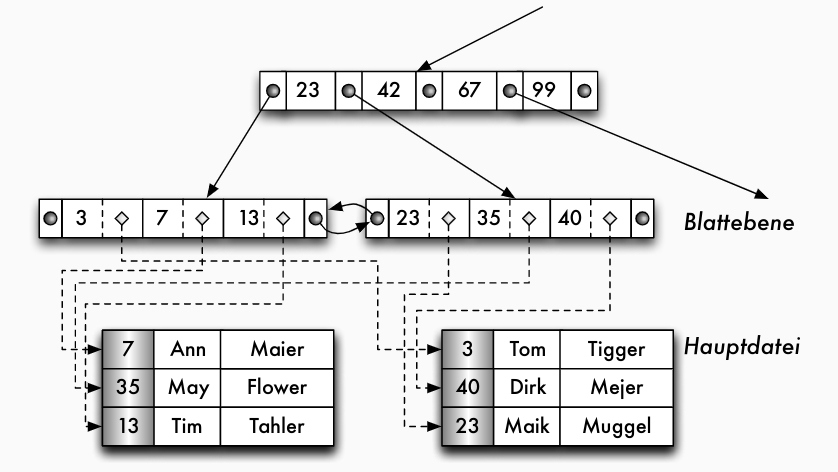
B+-Baum: Datenstrukturen
BPlusBranchNode =record of
nkeys: int;
ptrs: array[0 .. nkeys ] of PageNum;
keys: array[1 .. nkeys ]of KeyType;
level: int;
/* Level= 1 zeigt an, dass die ptrs auf Blätter zeigen */
end;
BPlusLeafNode = record of
nkeys: int;
keys: array[1 .. nkeys ]of KeyType;
payload: array[1 .. nkeys ]of LoadType ; /* Daten bzw. TIDs */
nextleaf: PageNum;
end;
Operationen im B+-Baum
- lookup: wie im B-Baum jedoch immer bis zur Blattebene
search(u,o): Lookup für unteren Wertu, Traversieren auf der Blattebene bis zum oberen Wertoinsert: ähnlich zum B-Baum- im Fall des Split bei Überlaufbehandlung wird nur ein Separatorschlüssel im Elternknoten eingefügt
- z.B. Kopie des kleinsten Schlüsselwertes des "rechten" Kindknotens oder geeigneter Wert zwischen beiden Knoten
delete: ähnlich zum B-Baum, jedoch- Löschen der Daten zunächst nur auf Blattebene
- bei Unterlauf: entweder Ausgleich mit Nachbarknoten oder Vereinigen mit Nachbarknoten; ggf. Anpassen (Ausgleich) oder Löschen (Vereinigen) des Separatorschlüssels
- alternativ: Unterlauf akzeptieren und durch spätere inserts oder Reorganisation auflösen
Weitere Entwurfsentscheidungen für B+-Baum
- Schlüsselsuche im Knoten: sequenzielle Suche vs. binäre Suche vs. Interpolation Search
- Knotengröße: Maximieren der Anzahl der Vergleiche (Knotennutzen) pro I/O-Zeiteinheit
| Seitengröße (KB) | Sätze/Seite | Knotennutzen | I/O-Zeit (ms) | Nutzen/Zeit |
|---|---|---|---|---|
| 4 | 143 | ≈7 | 5,020 | 1,427 |
| 16 | 573 | ≈ 9 | 5,080 | 1,804 |
| 64 | 2.294 | ≈ 11 | 5,320 | 2,098 |
| 128 | 4.588 | ≈ 12 | 5,640 | 2,157 |
| 256 | 9.175 | ≈ 13 | 6,280 | 2,096 |
| 1024 | 36.700 | ≈ 15 | 10,120 | 1,498 |
| 4096 | 146.801 | ≈ 17 | 25,480 | 0,674 |
| [Literatur](G. Graefe: Modern B-Tree Techniques, Foundations and Trends in Databases, 2010) |
- Konsistenzprüfung während der Traversierung
- mögliche Inkonsistenzen durch Speicherfehler, konkurrierende Änderungen + Implementierungsfehler, ...
- Cache-Optimierung: Knotenstruktur, Kompression (Präfix-/Suffix Truncation)
- Pointer Swizzling: zur Ersetzung der logischen Seitennummern durch physische Adressen
- Knotengröße: bei großen Puffern kann großer Teil der inneren Knoten im Puffer gehalten werden -> größere Knoten (im MB-Bereich) sinnvoll
- Verzögern des Splits bei Überlaufbehandlung: Ausgleichen mit Nachbarknoten soweit möglich; verbessert Auslastung der Knoten
- zusätzliche Verweise zwischen Knoten
- z.B. zwischen inneren Knoten der gleichen Ebene, zu Elternknoten, etc.
- ermöglichen Konsistenzchecks, aber erschweren Sperren für Nebenläufigkeitskontrolle
Weitere Varianten
Präfix-B-Baum
- B-Baum über Zeichenkettenattribut
- lange Schlüssel in inneren Knoten -> hoher Speicherplatzbedarf
- vollständige Schlüssel eigentlich nicht notwendig, da nur "Wegweiser"
- Idee: Verwaltung von Trennwerten -> Präfix-B-Baum
- in inneren Knoten nur Trennwerte, die lexikographisch zwischen den Werten liegen
- möglichst kurze Trennwerte, z.B. kürzester eindeutiger Präfix
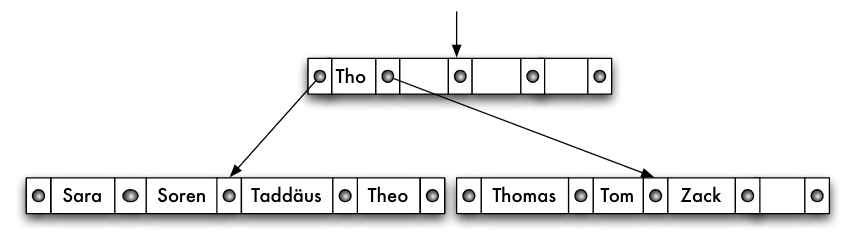
- aber: Beispiel "Vandenberg" und "Vandenbergh"
Mehr-Attribut-B-Baum
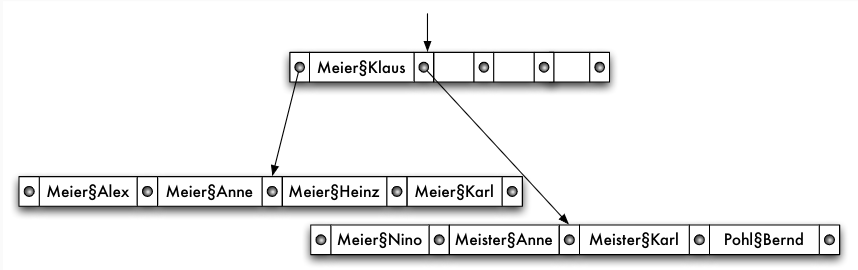
- B-Baum ist eindimensionale Struktur, jedoch können mehrere Attribute als kompositer Schlüssel indexiert werden
create index NameIdx on KUNDE(Name, Vorname) - allerdings: Attribute werden bei partial-match-Anfragen nicht gleich behandelt!
- Alternative: raumfüllende Kurven -> multidimensionale Indexstrukturen
Optimierungen für moderne Hardware
Optimierungspotential
- Verbesserung der Cache-Trefferrate
- Organisation der Datenstruktur entsprechend Cacheline (Größe, Anordnung der Daten)
- In-Place-Update im Hauptspeicher -> Cache-Invalidierung: verändertes Update Handling
- Pointer Swizzling
- Berücksichtigung der Storage-Eigenschaften
- SSD vs. HDD
- Bevorzugung sequentieller Schreiboperationen
- spezielle Berücksichtigung für Main-Memory-Indexe
- Synchronisation in Multicore-Umgebungen
- Lock/Latch-freie Operationen
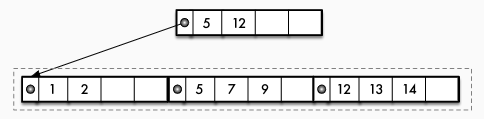
CSB+-Baum
- =Cache Sensitive B+ Tree (Rao, Ross: Making B+-Trees Cache Conscious in Main Memory, SIGMOD 2000)
- "Cache-Freundlichkeit" durch
- Platzsparen im Knoten -> mehr relevante Daten im Cache
- Eliminieren von Zeigern für 1. und Reduzierung von Zeigerarithmetik
- Ansatz: veränderte Struktur der inneren Knoten
- Zeiger auf ersten Kindknoten
- alle Kindknoten eines Knotens sind in einem zusammenhängenden Speicherbereich (Knotengruppe) allokiert und werden über einenOffsetadressiert
Bw-Baum
- = Buzzword Tree (Levandoski, Lomet, Sengupta: The Bw-Tree: A B-tree for New Hardware Platforms, ICDE 2013)
- Ziele: Cache-Freundlichkeit, Multicore-CPUs, Flash-Speichereigenschaften
- Techniken
- überwiegend Latch-freie Operationen, stattdessen atomare CAS-Instruktionen
- spezifische Struktur-Modifikationsoperationen: Folge von atomaren Modifikationen, Blink-ähnliche Struktur
- Delta-Updates und Log Structured Storage (LSS)
- Änderungen an Seiten/Knoten werden nicht direkt ausgeführt, sondern in Delta-Records pro Knoten erfasst
- keine Synchronisation für Zugriff auf Seiten notwendig
- Seite kann auch nach Änderung im Cache verbleiben
- Seiten + Delta Records werden periodisch konsolidiert
- Log Structured Storage -> später!
- Mapping-Tabelle: logische Seitennummern in
- (a) Offset im Flash-Speicher
- (b) Zeiger im Hauptspeicher
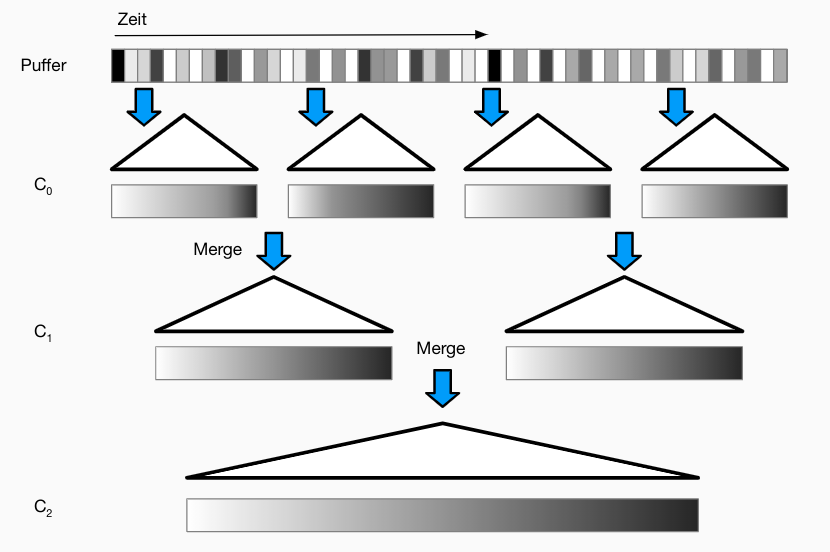
LSM-Baum
- = Log Structured Merge Tree (O’Neil, Cheng, Gawlick, O’Neil: The log-structured merge-tree (LSM-tree). Acta Informatica. 33 (4): 351-385, 1996)
- Ziel: höherer Schreibdurchsatz durch Eliminierung verstreuter In-Place-Updates
- Einsatz in diversen NoSQL-Systemen: HBase, Cassandra, BigTable, LevelDB, RocksDB, ...
- Grundidee
- Batches von Schreiboperationen werden sequentiell in Indexdateien gespeichert, d.h. Sortieren vor Schreiben auf Externspeicher (Log Structured)
- Neue Updates werden in neuen Indexdateien gespeichert
- Indexdateien werden periodisch zusammengefügt (Merge)
- Leseoperationen müssen alle Indexdateien konsultieren
LSM-Baum: Realisierung
- Main-Memory-Baum
C_0als Puffer, sortiert nach Schlüsseln, z.B. als AVL- oder RB-Baum- bei Erreichen eines gegebenen Füllgrads -> Herausschreiben auf Disk (siehe unten)
- ergänzt um Write Ahead Logging auf Disk für Wiederherstellung nach Systemfehler
- mehrere Append-only, disk-basierte Indexe
C_1, C_2,...,ebenfalls sortiert nach Schlüssel (z.B. als B-Baum)- effiziente Unterstützung von Scans (Schlüsselsuche)
- Merge in einem Schritt
- Aktualität der Indexe:
C_0,C_1,...,C_n
LSM-Baum: Verdichtung
- wenn bestimmte Anzahl von Dateien erzeugt wurden (z.B. 5 Dateien je 100 Datensätze), werden diese in eine Datei gemischt (1 Datei mit 500 Sätzen)
- sobald 5 Dateien mit 500 Sätzen vorliegen, dann Mischen in eine Datei
- usw.
- Nachteil: große Anzahl von Dateien, die alle durchsucht werden müssen
LSM-Baum: Ebenenweise Verdichtung
- pro Ebene wird eine bestimmte Zahl von Dateien verwaltet, partitioniert nach Schlüsseln (keine Überlappung der Schlüssel) -> Suche nur in einer Datei notwendig
- Ausnahme: erste Ebene (Überlappung erlaubt)
- Mischen der Dateien jeweils in die nächsthöhere Ebene: Auswahl einer Datei und Aufteilen der Sätze -> Platz für neue Daten schaffen
LSM-Baum: Lesezugriffe
- grundsätzlich: Verbesserung der Schreibperformance zulasten der Leseperformance
- Suche in allen Indexen
C_0,C_1,...,C_nnotwendig
- Suche in allen Indexen
- Vermeiden unnötiger Lesevorgänge durch Bloom-Filter pro Index oder pro Run
- (probabilistische) Datenstruktur zum Feststellen, ob Objekt in einer Menge enthalten ist
- Bit-Feld: Objekt wird über
kHashfunktionen aufkBits abgebildet, die auf 1 gesetzt werden - Prüfen auf Enthaltensein: Hashfunktionen anwenden -> Wenn alle
kBits= 1, dann ist Objekt enthalten - aber falsch-positive Werte möglich!
- können ebenfalls durch Mischen kombiniert werden
- [Quelle](Bloom: Space/Time Trade-offs in Hash Coding with Allowable Errors. CACM, 13(7):422-426, 1970)
Zusammenfassung
- B+-Baum als "Arbeitspferd" für Indexing
- Standardoperationen: Suche, Einfügen, Löschen
- noch nicht betrachtet: Nebenläufigkeitskontrolle und Wiederherstellung im Fehlerfall
- diverse Varianten und Optimierungen
- LSM-Baum für schreibintensive Workloads
Hashing
Hashing
- Zugriff über Adressberechnung aus Schlüssel
- linearer Adressraum der Grösse
n- Adressierung in einem Array
- Ziel: direkter Zugriff in
O(1)statt logarithmisch wie bei Bäumen
Hashverfahren
- Schlüsseltransformation und Überlaufbehandlung
- DB-Technik:
- Disk-basiert: Bildbereich entspricht Seiten-Adressraum
- Hauptspeicher: Adresse in einem Array (Hauptspeicheradresse plus Offset)
- Dynamik: dynamische Hashfunktionen oder Re-Hashen
Grundprinzipien
- Basis-Hashfunktion:
h(k)= k mod mmoft Primzahl da besseres Verhalten bei Kollisionen- oder
m=2^kaufgrund einfacher Berechnungen
- Überlauf-Behandlung
- Überlaufseiten als verkettete Liste
- lineares Sondieren
- quadratisches Sondieren
- doppeltes Hashen
- ...
Hashverfahren für blockorientierte Datenhaltung
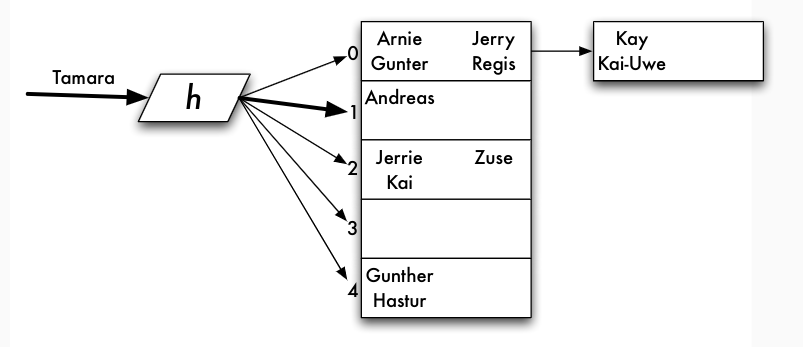
Operationen und Zeitkomplexität
- lookup, modify, insert, delete
- lookup benötigt maximal
1+ #B(h(w))Seitenzugriffe #B(h(w))Anzahl der Seiten (inklusive der Überlaufseiten) des Buckets für Hash-Werth(w)- Untere Schranke 2 (Zugriff auf Hashverzeichnis plus Zugriff auf erste Seite)
Statisches Hashen: Probleme
- mangelnde Dynamik
- Vergrößerung des Bildbereichs erfordert komplettes Neu-Hashen
- Wahl der Hashfunktion entscheidend;
- Bsp.: Hash-Index aus 100 Buckets, Studenten über 6-stellige MATRNR (wird fortlaufend vergeben) hashen
- ersten beiden Stellen: Datensätze auf wenigen Seiten quasi sequenziell abgespeichert
- letzten beiden Stellen: verteilen die Datensätze gleichmäßig auf alle Seiten
- Sortiertes Ausgeben einer Relation nicht unterstützt
Hash-Funktionen
- klassisch, etwa Divisions-Rest-Methode
h() = x mod m - zusammengesetzt, etwa
h(k)= h_2 (h_1 (k))(siehe später Spriralhashen) - ordnungserhaltend
k_1 < k_2 => ( h(k_1) = h(k_2) \vee h(k_1) < h(k_2)) - dynamisch (siehe später)
- mehrdimensional (siehe später)
- materialisiert (etwa Dictionary Encoding, siehe später)
Ordnungserhaltenes Hashen
- Schlüsselwerte werden als 8-Bit-Integer-Werte ohne Vorzeichen kodiert und sind gleichmässig im Bereich
0...2^8-1verteilt. - Die Extraktion der ersten drei Bits ergibt eine ordnungserhaltende Hashfunktion für den Bereich
0...2^3-1. - Sind die Schlüsselwerte nicht gleichverteilt, etwa weil es sich um fortlaufend vergebene Nummern handelt, ist das Ergebnis zwar weiterhin ordnungserhaltend, aber die Hash-Tabelle ist sehr ungleichmäßig gefüllt.
Hardware-sensitives Hashen
Neue Hardware und Hash-Funktionen
- Beobachtung: Hashen mit klassischem Sondieren ungünstig für neue Hardware
- schwer parallelisierbar
- Clustern von Werten verletzt Nähe der Werte (bei Cache Lines)
- Varianten versuchen beide Punkte anzugehen
- Cuckoo-Hashing
- optimiertes lineares Sondieren
- Hopscotch-Hashing
- Robin-Hood-Hashing
Cuckoo-Hashen
- Kuckucks-Hashen
- soll Parallelität erhöhen im Vergleich zu linearem Sondieren
- Idee: Zwei Tabellen mit zwei Hash-Funktionen
- im Fall einer Kollision in einer Tabelle wird in der zweiten Tabelle gesucht
- ist dort der Platz belegt, wird der dortige Eintrag verdrängt in die jeweils andere Tabelle - Kuckuck wirft Ei aus dem Nest
- dies wird solange gemacht bis ein freier Platz gefunden wird
- Beispiel
- zwei einfache Hash-Funktionen, die jeweils die letzte beziehungsweise vorletzte Dezimalstelle einer Zahl extrahieren
$h_1(k) = k mod 10$
h_2(k) = (k/10) mod 10 - Bei einer Suche muss immer in beiden Tabellen nachgeschaut werden, also
T_1[h_1(k)] = k\vee T_2[h_2(k)] = k. - Wir fügen die Zahlen
433, 129und555in die TabelleT_1ein. Beim Einfügen von783ist der Platz in TabelleT_1belegt, so dass diese Zahl inT_2gespeichert werden muss. Wird nun mit103eine weitere Zahl eingefügt, die mit433unterh_1kollidiert, ist dies mith_2weiterhin möglich.
- zwei einfache Hash-Funktionen, die jeweils die letzte beziehungsweise vorletzte Dezimalstelle einer Zahl extrahieren
$h_1(k) = k mod 10$
Cuckoo Beispiel
- Ergebnis des Einfügens von 433, 129 , 555 , 783 , 103
| | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 |
| ----- | --- | --- | --- | --- | --- | --- | --- | --- | --- |
|
T_1| | | | 433 | | 555 | | | | 129 | |T_2| 103 | | | | | | | | 783 | - Wird nun die Zahl
889eingefügt, so sind beide möglichen Positionen belegt.889kann inT_1die dort stehende Zahl129verdrängen, die inT_2an der PositionT_2[2]gespeichert werden kann. | | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | ----- | --- | --- | --- | --- | --- | --- | --- | --- | --- | |T_1| | | | 433 | | 555 | | | | 129 | |T_2| 103 | | 129 | | | | | | 783 | - Wird nun
789eingefügt, sind wiederum beide Positionen belegt. Das Verdrängen von889ausT_1würde zu einem kaskadierenden Verdrängen führen:889würde inT_2dann783verdrängen, das wiederum433inT_1verdrängen würde. Dies würde gehen da433an der StelleT_2[3]Platz hätte | | 0 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | | ----- | --- | --- | --- | --- | --- | --- | --- | --- | --- | |T_1| | | | 783 | | 555 | | | | 129 | |T_2| 103 | | 129 | 433 | | | | | 783 |
Weitere Prinzipien der Optimierung
- Lokalität von Datenzugriffen verringert die Wahrscheinlichkeit von Cache Misses
- Blockung von Daten kann an die Grösse von Cache-Lines (64 Bytes) angepasst werden, und erhöht den Durchsatz
- Parallelisierung für SIMD basierend auf einer Vektorisierung der Daten kann insbesondere SIMD-basierte Co-Prozessoren gut ausnutzen, aber greift auch bei MICs
Optimiertes lineares Sondieren
- Lineares Sondieren ist gut geeignet, um den Sondierungsvorgang auf Vektoren zu parallelisieren
- Suchschlüssel kann in einen Vektor der Länge
nan alle Positionen kopiert werden - beginnend ab derem initialen Sondierungspunkt
h(k)können dann Vektoren jeweils mit Vektoren aus der Hash-Tabelle verglichen werden, also zuerst mitH[h)k),...,h(k)+n - 1], dann mitH[h(k) + n,...,h(k) + 2n-1 ], etc. - Vergleich kann parallel erfolgen; muss sowohl auf Vorhandensein von
kals auch auf Existenz einer leeren Position prüfen
- Suchschlüssel kann in einen Vektor der Länge
Hopscotch-Hashen
- Hopscotch: Himmel und Hölle beziehungsweise wild herumhopsen
- Begrenzung des Sondierungsraum auf eine (konstante) Länge
- Idee:
- beim Einfügen erfolgt die Suche (parallel) in der festen Nachbarschaft
- wird Schlüssel
knicht gefunden und existiert kein freier Slot in der festen Nachbarschaft, dann wird versucht,kmit einem anderen Schlüssel aus der festen Nachbarschaft zu tauschen - dafür wird die nächste freie Stelle gesucht; von dieser wird rückwärts in Richtung
h(k)gesucht und jeder Eintragk′untersucht - wenn die aktuelle freie Stelle noch in der festen Nachbarschaft von
k′liegt, wird getauscht:k′springt auf die freie Stelle
Robin-Hood-Hashen
- Robin-Hood: Nimm von den Reichen gib es den Armen
- Basisidee: in der Situation, dass beim Sondieren für
kein Platz bereits mit einem Elementk′besetzt ist, wird der nächste Sondierungsschritt mit demjenigen Element weitergeführt, das die kleinere Distanz zum eigentlichen Hash-Werth(k)bzw.h(k′)hat
Dynamische Hash-Verfahren
Lineares Hashen
- Folge von Hash-Funktionen, die wie folgt charakterisiert sind:
h_i: dom(Primärschlüssel) ->\{0,..., 2^i \times N\}ist eine Folge von Hash-Funktionen miti\in\{0,1,2,...\}undNals Anfangsgröße des Hash-Verzeichnisses- Wert von
iwird auch als Level der Hash-Funktion bezeichnet dom(Primärschlüssel)wird im folgenden alsdom(Prim)abgekürzt
- Für diese Hash-Funktionen gelten die folgenden Bedingungen:
h_{i+1}(w) = h_i(w)für etwa die Hälfte allerw\in dom(Prim)h_{i+1}(w) = h_i(w) + 2^i\times Nfür die andere Hälfte- Bedingungen sind zum Beispiel erfüllt, wenn
h_i(w)alsw mod(2^i\times N)gewählt wird - Darstellung durch Bit-Strings, Hinzunahme eines Bits verdoppelt Bildbereich
Prinzip lineares Hashen
- für ein
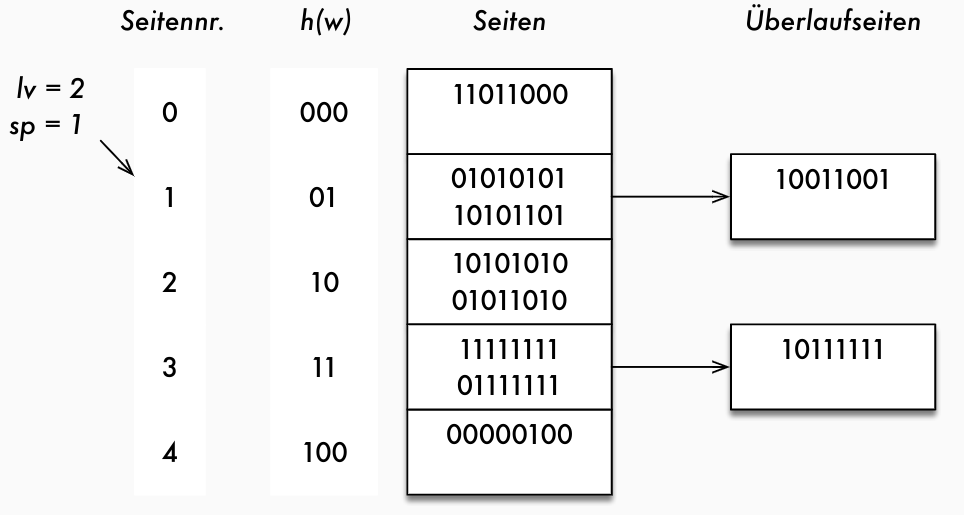
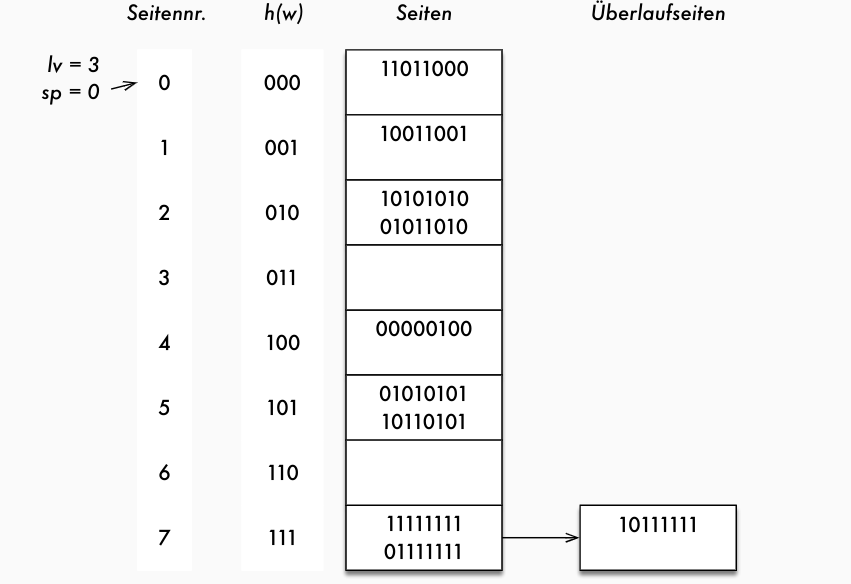
whöchstens zwei Hash-Funktionen zuständig, deren Level nur um 1 differiert, Entscheidung zwischen diesen beiden durch Split-ZeigerspSplit-Zeiger (gibt an, welche Seite als nächstes geteilt wird)lvLevel (gibt an, welche Hash-Funktionen benutzt werden)
- Aus Split-Zeiger und Level läßt sich die Gesamtanzahl
Anzder belegten Seiten wie folgt berechnen:Anz = 2^{lv} + sp
- Beide Werte werden am Anfang mit 0 initialisiert.
Lookup
-
s := h_{lv}(w)$; - if
s < sp - then
s := h_{lv + 1}(w); - zuerst Hash-Wert mit der "kleineren" Hash-Funktion bestimmen
- liegt dieser unter dem Wert des Split-Zeigers => größere Hash-Funktion verwenden
Splitten einer Seite
- Die Sätze der Seite (Bucket), auf die
spzeigt, werden mittelsh_{lv+1}neu verteilt (ca. die Hälfte der Sätze wird auf Seite (Bucket) unter Hash-Nummer2^{lv}*N +spverschoben) - Der Split-Zeiger wird weitergesetzt:
sp:=sp +1; - Nach Abarbeiten eines Levels wird wieder bei Seite 0 begonnen; der Level wird um 1 erhöht:
if sp = 2^{lv} * N then
begin
lv := lv + 1 ;
sp := 0
end;

Problem lineares Hashen
Erweiterbares Hashen
- Problem: Split erfolgt an fester Position, nicht dort wo Seiten überlaufen
- Idee: binärer Trie zum Zugriff auf Indexseiten
- Blätter unterschiedlicher Tiefe
- Indexseiten haben Tiefenwert
- Split erfolgt bei Überlauf
- aber: Speicherung nicht als Trie, sondern als Array
- entspricht vollständigem Trie mit maximaler Tiefe
- "shared" Seiten als Blätter
- Array der Grösse 2 d für maximale Tiefe d
- erfordert nun nur einen Speicherzugriff!
- bei Überlauf: Indexgrösse muss möglicherweise verdoppelt werden!
- entspricht vollständigem Trie mit maximaler Tiefe
- Ausgangslage:
- Einfügen von 00111111 würde Überlauf bei erreichter maximaler Tiefe erzeugen
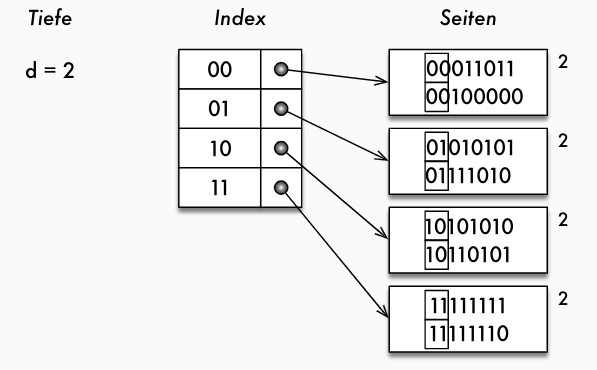
- Verdopplung der Indexgrösse
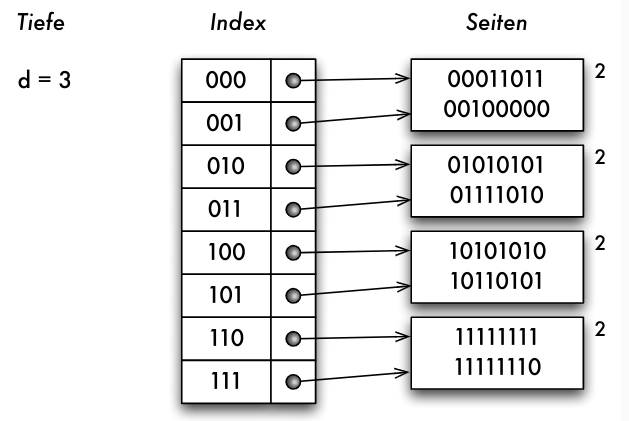
- nun möglich: Split der Seite
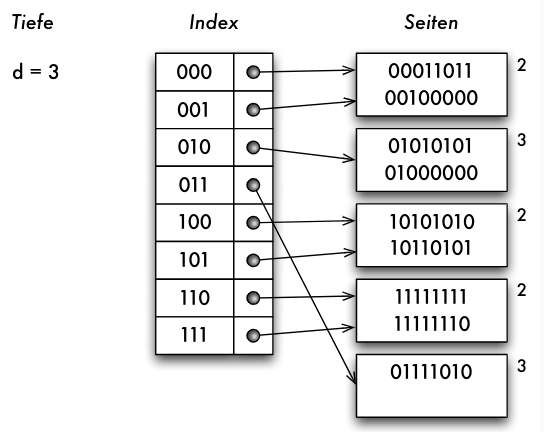
- Einfügen von 00111111 würde Überlauf bei erreichter maximaler Tiefe erzeugen
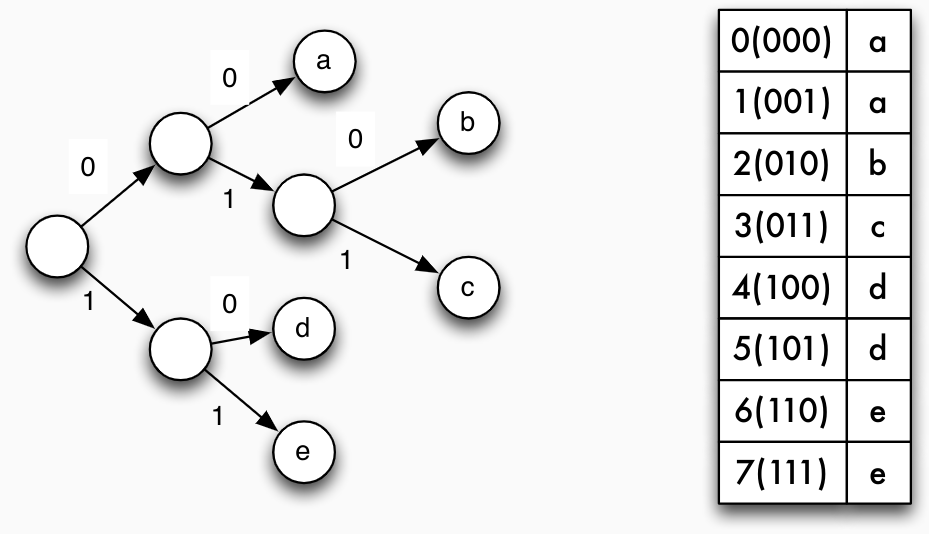
Variante: Array als Trie gespeichert
Spiral-Hashen
- Problem: zyklisch erhöhte Wahrscheinlichkeit des Splittens
- Lösung: unterschiedliche Dichte der Hashwerte
- Interpretation der Bit-Strings als binäre Nachkommadarstellung einer Zahl zwischen
0.0und1.0 - Funktion von
[0.0,1.0] -> [0.0,1.0]so dass Dichte gleichmässig verteilter Werte nahe1.0doppelt so gross ist wie nahe0.0
- Interpretation der Bit-Strings als binäre Nachkommadarstellung einer Zahl zwischen
- Umverteilung mittels Exponentialfunktion
- Funktion
exp(n)exp(n) = 2^n - 1erfüllt die Bedingungen - insbesondere gilt
2^0 - 1 = 0und2^1 - 1 = 1 - Hashfunktion exhash
exhash(k) = exp(h(k)) = 2^{h(k)} - 1 - Wirkung der verwendeten Hashfunktion im Intervall
0.0bis1.0n2^n-10.00.00.10.07177350.20.14869840.30.23114440.40.31950790.50.41421360.60.51571660.70.62450480.80.74110110.90.8660661.01.0 - Spiralförmiges Ausbreiten
- Ausgangslage: 4 Seiten der Tiefe 2
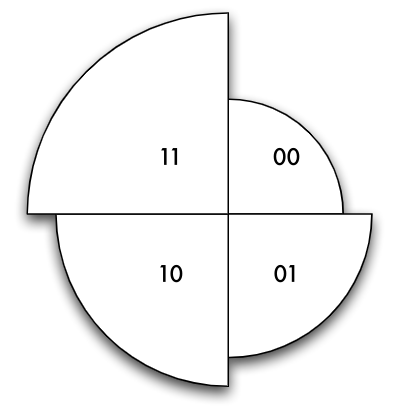
- Ausgangslage: 4 Seiten der Tiefe 2
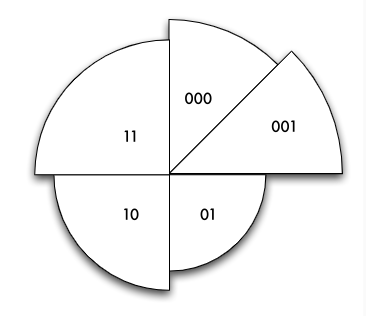
- Spiralförmiges Ausbreiten
- Split der Seite mit der höchsten Dichte
- Ergebnis: 5 Seiten, davon 3 der Tiefe 2 und 2 der Tiefe 3
Grid-File
Grid-Files
- bekannteste und von der Technik her attraktive mehrdimensionale Dateiorganisationsform
- eigene Kategorie: Elemente der Schlüsseltransformation wie bei Hashverfahren und Indexdateien wie bei Baumverfahren kombiniert
- deshalb hier bei Hash-Verfahren betrachtet
Grid-File: Zielsetzungen
- Prinzip der 2 Plattenzugriffe: Jeder Datensatz soll bei einer exact-match -Anfrage in 2 Zugriffen erreichbar sein
- Zerlegung des Datenraums in Quader: n -dimensionale Quader bilden die Suchregionen im Grid-File
- Prinzip der Nachbarschaftserhaltung: Ähnliche Objekte sollten auf der gleichen Seite gespeichert werden
- Symmetrische Behandlung aller Raum-Dimensionen: partial-match -Anfragen ermöglicht
- Dynamische Anpassung der Grid-Struktur beim Löschen und Einfügen
Prinzip der zwei Plattenzugriffe
- bei exact-match
- gesuchtes
k-Tupel auf Intervalle der Skalen abbilden; als Kombination der ermittelten Intervalle werden Indexwerte errechnet; Skalen im Hauptspeicher => noch kein Plattenzugriff - über errechnete Indexwerte Zugriff auf das Grid-Directory ; dort Adressen der Datensatz-Seiten gespeichert; erster Plattenzugriff.
- Der Datensatz-Zugriff: zweiter Plattenzugriff.
- gesuchtes
Aufbau eines Grid-Files
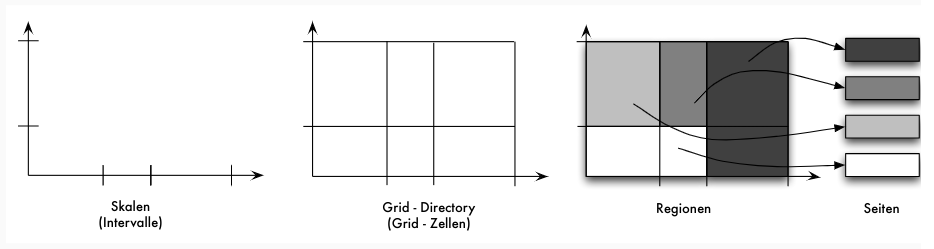
- Grid:
keindimensionale Felder (Skalen), jede Skala repräsentiert Attribut - Skalen bestehen aus Partition der zugeordneten Wertebereiche in Intervalle
- Grid-Directory besteht aus Grid-Zellen, die den Datenraum in Quader zerlegen
- Grid-Zellen bilden eine Grid-Region, der genau eine Datensatz-Seite zugeordnet wird
- Grid-Region: $k$-dimensionales, konvexes (Regionen sind paarweise disjunkt)
Operationen
- Zu Anfang: Zelle = Region = eine Datensatz-Seite
- Seitenüberlauf:
- Seite wird geteilt
- falls zugehörige Gridregion aus nur einer Gridzelle besteht, muss ein Intervall auf einer Skala in zwei Intervalle unterteilt werden
- besteht Region aus mehreren Zellen, so werden diese Zellen in einzelne Regionen zerlegt
- Seitenunterlauf:
- Zwei Regionen zu einer zusammenfassen, falls das Ergebnis eine neue, konvexe Region ergibt
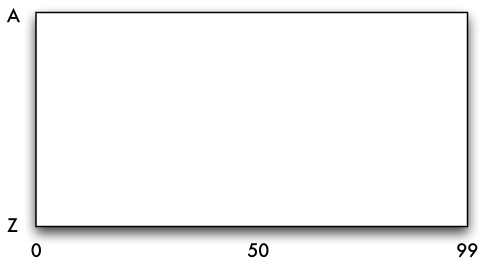
Beispiel
- Start-Grid-File
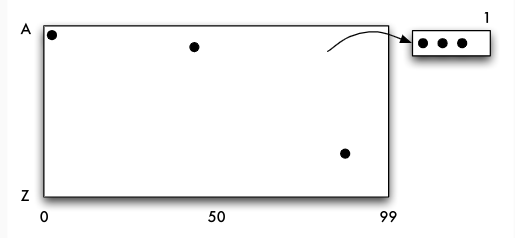
- Datensätze einfügen:
(45,D),(2,B),(87,S),(75,M),(55,K),(3,Y),(15,D),(25,K),(48,F) - jede Seite des Grid-Files fasst bis zu drei Datensätze
- Datensätze einfügen:
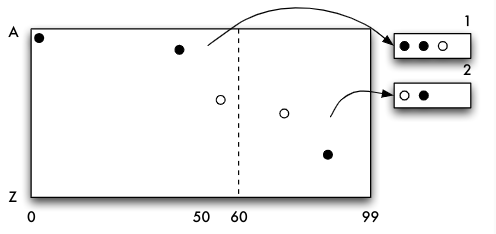
- Eingefügt: $(45, D), (2, B), (87, S)$
- Einfügen von
(75, M)erzwingt Split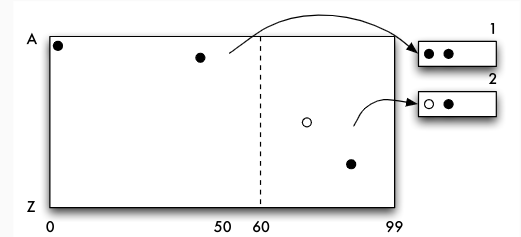
- Eingefügt: $(55, K)$
- Einfügen von
(3, Y)erzwingt wiederum einen Split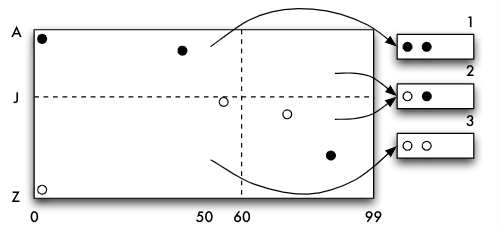
- Eingefügt: (15, D), (25, K),
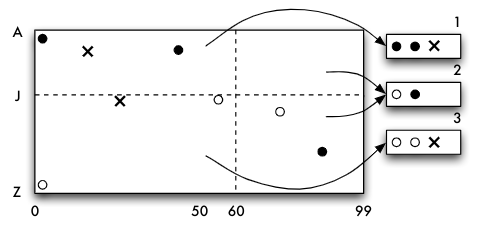
- Einfügen von (48, F) erzwingt wiederum einen Split
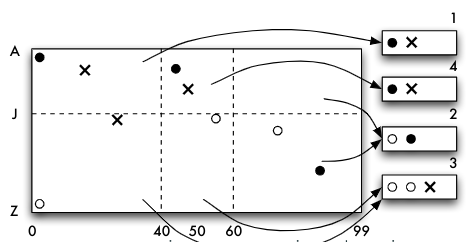
Buddy-System
- Beschriebenes Verfahren: Buddy-System (Zwillings-System)
- Die im gleichen Schritt entstandenen Zellen können zu Regionen zusammengefasst werden; Keine andere Zusammenfassung von Zellen ist im Buddy-System erlaubt
- Unflexibel beim Löschen: nur Zusammenfassungen von Regionen erlaubt, die vorher als Zwillinge entstanden waren
- Beispiel:
(15,D)löschen: Seiten 1 und 4 zusammenfassen;(87,S)löschen, Seite 2 zwar unterbelegt, kann aber mit keiner anderen Seite zusammengefasst werden
Weitere Indexstrukturen
Bitmap-Indexe
Bitmap-Indexe
- Idee: Bit-Vektor zur Kodierung der Tupel-Attributwert-Zuordnung
- Vergleich mit baumbasierten Indexstrukturen:
- vermeidet degenerierte B-Bäume
- unempfindlicher gegenüber höherer Zahl von Attributen
- einfachere Unterstützung von Anfragen, in denen nur einige (der indexierten) Attribute beschränkt werden
- dafür aber i.allg. höhere Aktualisierungskosten
- beispielsweise in Data Warehouses wegen des überwiegend lesenden Zugriffs unproblematisch
Bitmap-Index: Realisierung
- Prinzip: Ersetzung der TIDs (rowid) für einen Schlüsselwert im
b+-Baum durch Bitvektor - Knotenaufbau:
|B: 0 1001 0...0 1 | F: 1 01 000... 10 | O: 000 101 ...00 | - Vorteil: geringerer Speicherbedarf
- Beispiel: 150.000 Tupel, 3 verschiedene Schlüsselwerte, 4 Byte für TID
- B+-Baum: 600 KB
- Bitmap:
3*18750 Byte =56KB
- Beispiel: 150.000 Tupel, 3 verschiedene Schlüsselwerte, 4 Byte für TID
- B+-Baum: 600 KB
- Bitmap:
- Nachteil: Aktualisierungsaufwand
- Definition in Oracle
CREATE BITMAP INDEX bestellstatus_idx ON bestellung(status); - Speicherung in komprimierter Form
Standard-Bitmap-Index
- jedes Attribut wird getrennt abgespeichert
- für jede Ausprägung eines Attributs wird ein Bitmap-Vektor angelegt: - für jedes Tupel steht ein Bit, dieses wird auf 1 gesetzt, wenn das indexierte Attribut in dem Tupel den Referenzwert dieses Bitmap-Vektors enthält - die Anzahl der entstehenden Bitmap-Vektoren pro Dimension entspricht der Anzahl der unterschiedlichen Werte, die für das Attribut vorkommen
- Beispiel: Attribut Geschlecht
- 2 Wertausprägungen (m/w)
- 2 Bitmap-Vektoren
PersId Name Geschlecht Bitmap-w Bitmap-m 007 James Bond M 0 1 008 Amelie Lux W 1 0 010 Harald Schmidt M 0 1 011 Heike Drechsler W 1 0
- Selektion von Tupeln kann nun durch entsprechende Verknüpfung von Bitmap-Vektoren erfolgen
- Beispiel: Bitmap-Index über Attribute Geschlecht und Geburtsmonat
- (d.h. 2 Bitmap-Vektoren B-w und B-m für Geschlecht und 12 Bitmap-Vektoren B-1, ..., B-12 für die Monate, wenn alle Monate vorkommen)
- Anfrage: "alle im März geborenen Frauen"
- Berechnung:
B-w \wedge B-3(bitweise konjunktiv verknüpft) - Ergebnis: alle Tupel, an deren Position im Bitmap-Vektor des Ergebnis eine 1 steht
- Berechnung:
Mehrkomponenten-Bitmap-Index
- bei Standard-Bitmap-Indexe entstehen für Attribute mit vielen Ausprägungen sehr viele Bitmap-Vektoren
- $<n,m>$-Mehrkomponenten-Bitmap-Indexe erlauben
n*mmögliche Werte durchn+mBitmap-Vektoren zu indexieren - jeder Wert
x(0\leq x\leq n*m-1)kann durch zwei Werteyundzrepräsentiert werden:x=n*y+zmit0\leq y\leq m-1und0\leq z\leq n-1- dann nur noch maximal
mBitmap-Vektoren füryundnBitmap-Vektoren fürz - Speicheraufwand reduziert sich von
n*maufn+m - dafür müssen für eine Punktanfrage aber 2 Bitmap-Vektoren gelesen werden
- dann nur noch maximal
- Beispiel: Zweikomponenten-Bitmap-Index
- Für
M= 0 ..11etwax= 4*y + z - y-Werte:
B-2-1, B-1-1, B-0-1 - z-Werte:
B-3-0, B-2-0, B-1-0, B-0-0x y z M B-2-1 B-1-1 B-0-1 B-3-0 B-2-0 B-1-0 B-0-0 5 0 1 0 0 0 1 0 3 0 0 1 1 0 0 0 0 0 0 1 0 0 0 1 11 1 0 0 1 0 0 0
- Für
Beispiel: Postleitzahlen
- Kodierung von Postleitzahlen
- Werte 00000 bis 99999
- direkte Umsetzung: 100.000 Spalten
- Zweikomponenten-Bitmap-Index (erste 2 Ziffern + 3 letzte Ziffern): 1.100 Spalten
- Fünf Komponenten: 50 Spalten
- geeignet für Bereichsanfragen "PLZ 39***"
- Binärkodiert (bis
2^17): 34 Spalten- nur für Punktanfragen!
- Bemerkung: Kodierung zur Basis 3 ergibt sogar nur 33 Spalten...
Indexierung von Texten
Indexierung von Texten
- bisher vorgestellte Verfahren unterstützen prinzipiell auch die Indexierung von Zeichenketten
- Probleme bereitet folgendes:
- unterschiedliche Längen der Zeichenketten als Suchschlüssel
- bei Sätzen: Zugriff auf einzelne Wörter bevorzugt
- Ähnlichkeiten u.a. über gemeinsame Präfixe und Editierabstand
Digital- und Präfixbäume
- B-Bäume: Problem bei zu indexierenden Zeichenketten
- Lösung: Digital- oder Präfixbäume
- Digitalbäume indexieren (fest) die Buchstaben des zugrundeliegenden Alphabets
- können dafür unausgeglichen werden
- Beispiele: Tries, Patricia-Bäume
- Präfixbäume indexieren Präfix der Zeichenketten
Tries
- von "Information Retrieval", aber wie try gesprochen
- Abgrenzung vom tree für allgemeine Suchbäume

- Abgrenzung vom tree für allgemeine Suchbäume
- Knoten eines Tries
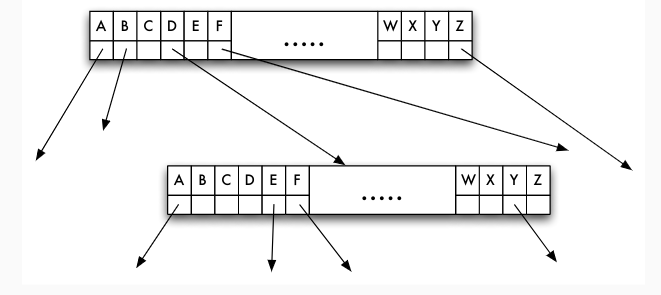
- Probleme: lange gemeinsame Teilworte, nicht vorhandenen Buchstaben und Buchstabenkombinationen, möglicherweise leere Knoten, sehr unausgeglichene Bäume
Patricia-Bäume
- Tries: Probleme bei Teilekennzahlen, Pfadnamen, URLs (lange gemeinsame Teilworte)
- Lösung: Practical Algorithm To Retrieve Information Coded In Alphanumeric (Patricia)
- Prinzip: Überspringen von Teilworten
- Problem: Datenbanksprache bei Suchbegriff Triebwerksperre
Patricia-Baum und Trie im Vergleich
- übersprungene Teilworte zusätzlich speichern: Präfix-Bäume
Präfix-Bäume
- Patricia-Baum plus Abspeicherung der übersprungenen Präfixe
Invertierte Listen
- indizierte Worte (Zeichenketten) bilden eine lexikographisch sortierte Liste
- einzelner Eintrag besteht aus einem Wort und einer Liste von Dokument-Identifikatoren derjenigen Dokumente, in denen das Wort vorkommt
- zusätzlich können weitere Informationen für die Wort-Dokument-Kombination abgespeichert werden:
- Position des (ersten Auftretens des) Wortes im Text
- Häufigkeit des Wortes im Text
Invertierte Listen
Mehrdimensionale Speichertechniken
Mehrdimensionale Speichertechniken
- bisher: eindimensional (keine partial-match-Anfragen, nur lineare Ordnung)
- jetzt: mehrdimensional (auch partial-match-Anfragen, Positionierung im mehrdimensionalen Datenraum)
kDimensionen =kAttribute können gleichberechtigt unterstützt werden- dieser Abschnitt
- mehrdimensionaler B-Baum
- mehrdimensionales Hashverfahren
Mehrdimensionale Baumverfahren
Mehrdimensionale Baumverfahren
- KdB-Baum ist B+-Baum, bei dem Indexseiten als binäre Bäume mit Zugriffsattributen, Zugriffsattributwerten und Zeigern realisiert werden
- Varianten von
k-dimensionalen Indexbäumen:- kd-Baum von Bentley und Friedman: für Hauptspeicheralgorithmen entwickelte, mehrdimensionale Grundstruktur (binärer Baum)
- KDB-Baum von Robinson: Kombination kd-Baum und B-Baum (
k-dimensionaler Indexbaum bekommt höheren Verzweigungsgrad) - KdB-Baum von Kuchen: Verbesserung des Robinson-Vorschlags, wird hier behandelt
- KdB-Baum kann Primär- und mehrere Sekundärschlüssel gleichzeitig unterstützen
- macht als Dateiorganisationsform zusätzliche Sekundärindexe überflüssig
Definition KdB-Baum
- Idee: auf jeder Indexseite einen Teilbaum darstellen, der nach mehreren Attributen hintereinander verzweigt
- KdB-Baum vom Typ (
b,t) besteht aus- inneren Knoten (Bereichsseiten) die einen kd-Baum mit maximal
binternen Knoten enthalten - Blättern (Satzseiten) die bis zu
tTupel der gespeicherten Relation speichern können
- inneren Knoten (Bereichsseiten) die einen kd-Baum mit maximal
- Bereichsseiten: kd-Baum enthalten mit Schnittelementen und zwei Zeigern
- Schnittelement enthält Zugriffsattribut und Zugriffsattributwert;
- linker Zeiger: kleinere Zugriffsattributwerte;
- rechter Zeiger: größere Zugriffsattributwerte
- KdB-Baum vom Typ (
Beispiel
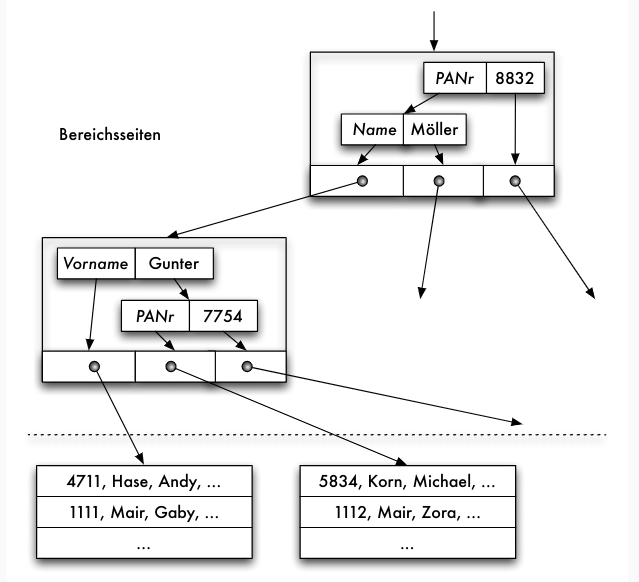
KdB-Baum: Struktur
- Bereichsseiten
- Anzahl der Schnitt- und Adressenelemente der Seite
- Zeiger auf Wurzel des in der Seite enthaltenen kd-Baumes
- Schnitt- und Adressenelemente.
- Schnittelement
- Zugriffsattribut
- Zugriffsattributwert
- zwei Zeiger auf Nachfolgerknoten des kd-Baumes dieser Seite (können Schnitt- oder Adressenelemente sein)
- Adressenelemente: Adresse eines Nachfolgers der Bereichsseite im KdB-Baum (Bereichs- oder Satzseite)
KdB-Baum: Operationen
- Komplexität
lookup,insertunddeletebei exact-matchO(log n) - bei partial-match besser als
O(n) - bei
tvonkAttributen in der Anfrage spezifiziert: Zugriffskomplexität vonO(n^{1-t/k})
KdB-Baum: Trennattribute
- Reihenfolge der Trennattribute
- entweder zyklisch festgelegt
- oder Selektivitäten einbeziehen: Zugriffsattribut mit hoher Selektivität sollte früher und häufiger als Schnittelement eingesetzt werden
- Trennattributwert: aufgrund von Informationen über Verteilung von Attributwerten eine geeignete "Mitte" eines aufzutrennenden Attributwertebereichs ermitteln
KdB-Baum: Brickwall
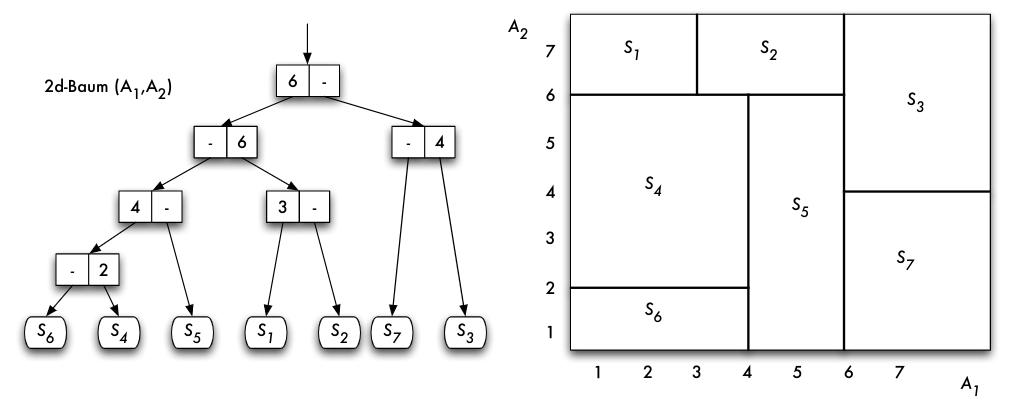
Mehrdimensionales Hashen
Mehrdimensionales Hashen
- Idee: Bit Interleaving
- abwechselnd von verschiedenen Zugriffsattributwerten die Bits der Adresse berechnen
- Beispiel: zwei Dimensionen
00 01 10 11 00 0000 0001 0100 0101 01 0010 0011 0110 0111 10 1000 1001 1100 1101 11 1010 1011 1110 1111
MDH von Kuchen
- MDH baut auf linearem Hashen auf
- Hash-Werte sind Bitfolgen, von denen jeweils ein Anfangsstück als aktueller Hashwert dient
- je ein Bitstring pro beteiligtem Attribut berechnen
- Anfangsstücke nun nach dem Prinzip des Bit-Interleaving zyklisch abarbeiten
- Hashwert reihum aus den Bits der Einzelwerte zusammensetzen
MDH formal
- mehrdimensionaler Wert
x := (x_1,..., x_k)\in D = D_1\times ...\times D_k - Folge von mit i indizierten Hashfunktionen konstruieren
- i-te Hashfunktion
h_i(x)wird mittels Kompositionsfunktion\bar{h}_iaus den jeweiligeni-ten Anfangsstücken der lokalen Hash-Werteh_{i_j}(x_j)zusammengesetzt:h_i(x)=\bar{h}_i(h_{i_1}(x_1),...,h_{i_k}(x_k)) - lokale Hashfunktionen
h_{i_j}ergeben jeweils Bitvektor der Längez_{i_j} +1:$h_{i_j} : D_j\rightarrow {0,..., z_{i_j}}, j\in{1 ,..., k}$ z_{i_j}sollten möglichst gleich groß sein, um die Dimensionen gleichmäßig zu berücksichtigen- Kompositionsfunktion
\bar{h}_isetzt lokale Bitvektoren zu einem Bitvektor der Längeizusammen:\bar{h}_i:\{0,...,z_{i1}\times ...\times\{0,..., z_{i_k}\}\rightarrow\{0,...,2^{i+1}-1\} - ausgeglichene Länge der
z_{i_j}wird durch folgende Festlegung bestimmt, die Längen zyklisch bei jedem Erweiterungsschritt an einer Stelle erhöht:$$z_{i_j} = \begin{cases} 2^{\lfloor \frac{i}{k}\rfloor +1} -1 \quad\text{ für } j-1\leq (i mod k)\\ 2^{\lfloor \frac{i}{k}\rfloor} -1 \quad\text{ für } j-1 > (i mod k) \end{case - Kompositionsfunktion:
$$\bar{h}_i(x)=\sum_{r=0}^i (\frac{(x_{(r mod k)+1} mod 2^{\lfloor \frac{r}{k}\rfloor +1}) - (x_{(r mod k)+1} mod 2^{\lfloor \frac{r}{k}\rfloor})}{2^{\lfloor \frac{r}{k}\rfloor})}) 2
MDH Veranschaulichung
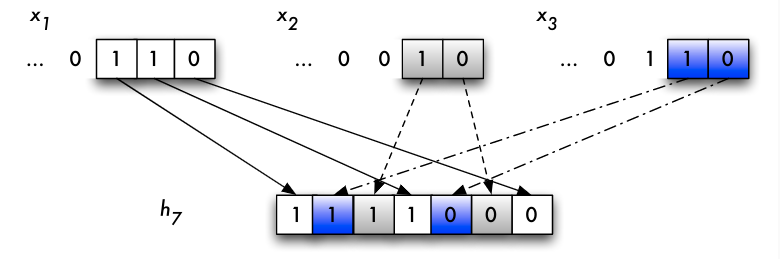
- verdeutlicht Komposition der Hashfunktion
h_ifür drei Dimensionen und den Werti=7 - graphisch unterlegte Teile der Bitstrings entsprechen den Werten
h_{7_1}(x_1),h_{7_2}(x_2)undh_{7_3}(x_3) - beim Schritt auf
i=8würde ein weiteres Bit vonx_2(genauer: vonh_{8_2}(x_2)) verwendet
MDH Komplexität
- Exact-Match-Anfragen:
O(1) - Partial-Match-Anfragen, bei
tvonkAttributen festgelegt, AufwandO(n^{1-\frac{t}{k}}) - ergibt sich aus der Zahl der Seiten, wenn bestimmte Bits "unknown"
- Spezialfälle:
O(1)fürt=k,O(n)fürt=0
Geometrische Zugriffsstrukturen
Geometrische Zugriffsstrukturen
- große Mengen geometrischer Objekte (
> 10^6) - Eigenschaften geometrischer Objekte
- Geometrie (etwa Polygonzug)
- zur Unterstützung bei Anfragen: zusätzlich $d$-dimensionales umschreibendes Rechteck (bounding box)
- nichtgeometrische Attribute
- Anwendungsszenarien: Geoinformationssysteme (Katasterdaten, Karten), CAx-Anwendungen (etwa VLSI Entwurf), ...
- Zugriff primär über Geometriedaten: Suchfenster (Bildschirmausschnitt), Zugriff auf benachbarte Objekte
Typische Operationen
- exakte Suche
- Vorgabe: exakte geometrische Suchdaten
- Ergebnis: maximal ein Objekt
- Bereichsanfrage für vorgegebenes $n$-dimensionales Fenster
- Suchfenster: $d$-dimensionales Rechteck (entspricht mehrdimensionalem Intervall)
- Ergebnis sind alle geometrischen Objekte, die das Suchfenster schneiden
- Ergebnisgröße parameterabhängig
- Einfügen von geometrischen Objekten
- wünschenswert ohne globale Reorganisation!
- Löschen von geometrischen Objekten
- wünschenswert ohne globale Reorganisation!
Nachbarschaftserhaltende Suchbäume
- Aufteilung des geometrischen Bereichs in Regionen
- benachbarte Objekte wenn möglich der selben Region zuordnen
- falls dieses nicht geht, diese auf benachbarte Regionen aufteilen
- Baumstruktur entsteht durch Verfeinerung von Regionen in benachbarte Teilregionen
- Speicherung von Objekten erfolgt in den Blattregionen
- Freiheitsgrade
- Form der Regionen
- vollständige Partitionierung oder Überlappung durch die Regionen
- eindeutige Zuordnung von Objekten zu Regionen oder Mehrfachzuordnung
- Speicherung und Zugriff über Originalgeometrie oder über abgeleitete Geometrie für Objekte
- Grad des Baumes & Organisationsform
Mehrstufige Bearbeitung geom. Anfragen
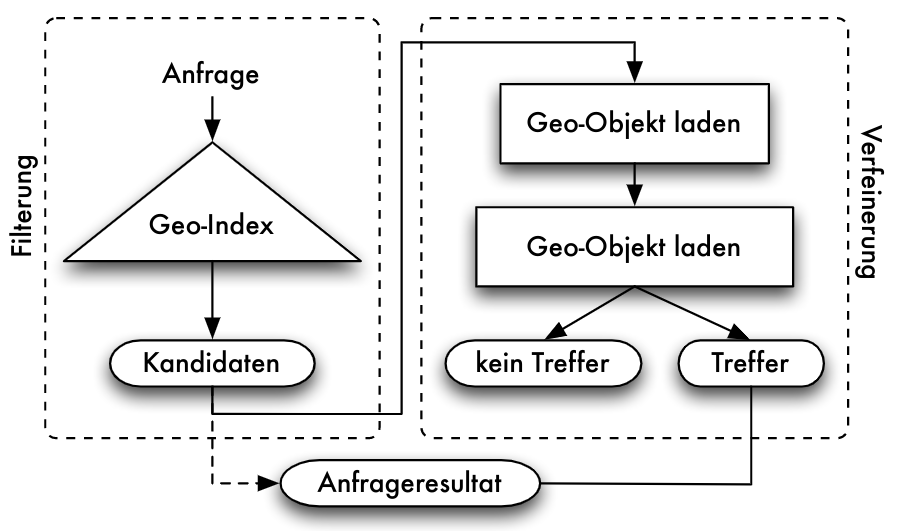
Geom. Baumstruktur: BSP-Baum
- Binary Space Partitioning: schrittweises binäres Teilen des Datenraums
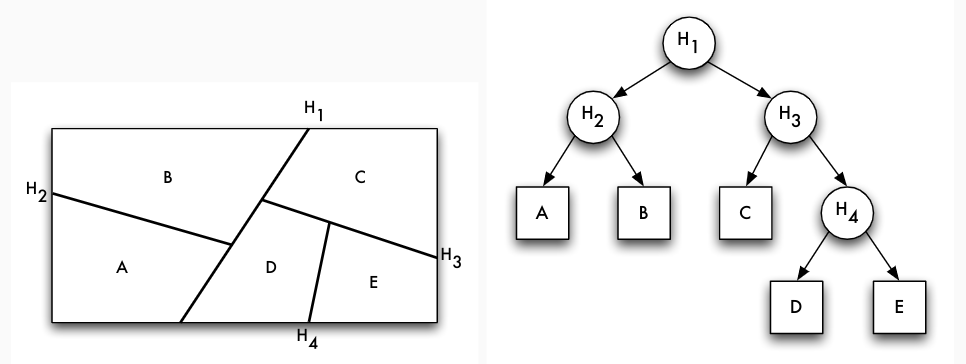
Realisierungsvarianten
| Alternative | Baumstrukturen | ||
|---|---|---|---|
| BSP-Baum | R-Baum | R+-Baum | |
| Regionenform | konvexe Polygone | Rechtecke | Rechtecke |
| Teilregionen | vollständig | unvollständig | unvollständig |
| Überlappung | nein | ja | nein |
| ausgeglichen | nein | ja | ja |
R-Bäume
- R-Baum: Verallgemeinerung des B-Baum-Prinzips auf mehrere Dimensionen
- Baumwurzel entspricht einem Rechteck, das alle geometrischen Objekte umfasst
- Geo-Objekte werden durch ihre umschließenden Rechtecke repräsentiert
- Aufteilung in Regionen erfolgt in nichtdisjunkte Rechtecke
- Jedes Geo-Objekt ist eindeutig einem Blatt zugeordnet
- Regionenaufteilung durch Rechtecke im R-Baum
- Baumstruktur für R-Baum

Probleme mit R-Bäumen
- gegebenes Rechteck kann von vielen Regionen überlappt werden, es ist aber genau in einer Region gespeichert
- auch Punktanfragen können eine Suche in sehr vielen Rechteckregionen bedeuten
- Ineffizient bei exakter Suche (exakte Suche auch bei Einfügen und Löschen notwendig!)
- Probleme beim Einfügen
- Einfügen erfordert oft Vergrößern von Regionen (aufwärts propagiert)
Vergrößern beim Einfügen
R+-Bäume
- R+-Bäume: Aufteilung in Teilregionen disjunkt
- Jedem gespeicherten Punkt des geometrischen Bereichs ist eindeutig ein Blatt zugeordnet
- In jeder Baumebene ist einem Punkt ebenfalls maximal ein Rechteck zugeordnet -> eindeutiger Pfad von der Wurzel zum speichernden Blatt
- ‘Clipping’ von Geo-Objekten notwendig!
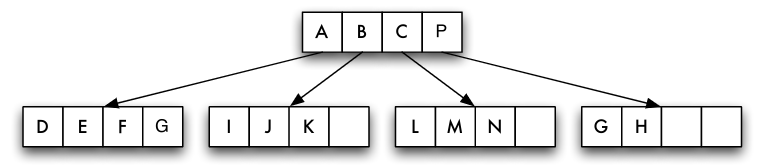
Probleme mit R+-Bäumen
- Objekte müssen in mehreren Rechteckregionen gespeichert werden (clipping) - erhöhter Speicher- & Modifikationsaufwand
- Einfügen von Objekten erfordert möglicherweise Modifikation mehrerer Rechteckregionen

- Einfügen kann in bestimmten Situationen unvermeidbar zu Regionenaufteilungen führen
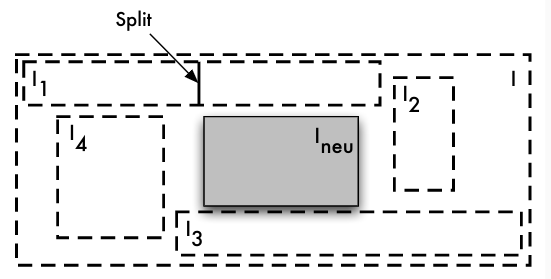
- Regionenmodifikationen haben Konsequenzen sowohl in Richtung Blätter als auch in Richtung Wurzel
- obere Grenze für Einträge in Blattknoten kann nicht mehr garantiert werden
Rechteckspeicherung durch Punktdatenstrukturen
- Probleme bei ausgedehnten Geometrien -> Entartung
- Nutzung "robuster" mehrdimensionaler Indexstrukturen (z.B. Grid-File) durch Abbildung von Rechtecken auf Punkte möglich?
Punktdatenstrukturen
- Rechteckspeicherung durch Punktdatenstrukturen
- Transformation von ausgedehnten Objekten (mehrdimensionale Rechtecke) in Punktdaten
- Transformation bildet $d$-dimensionale Rechtecke auf Punkte im $2d$-dimensionalen Raum
R^{2d}ab - $d$-dimensionale Rechteck:
r=[l_1, r_1]\times ...\times [l_d, r_d]
- Eckentransformation $p_r = (l_1, r_1,..., l_d, r_d) \in R^{2d}$ pro Intervall als Koordinaten: obere Schranke, untere Schranke
- Mittentransformation $p_r =(\frac{l_1+r_1}{2}, \frac{r_1-l_1}{2},...,\frac{l_d+l_r}{2},\frac{r_d-l_d}{2})\in\mathbb{R}^{2d}$ pro Intervall als Koordinaten: Mittelpunkt, halbe Breite
Eckentransformation
![]()
Mittentransformation
![]()
Suchfenster
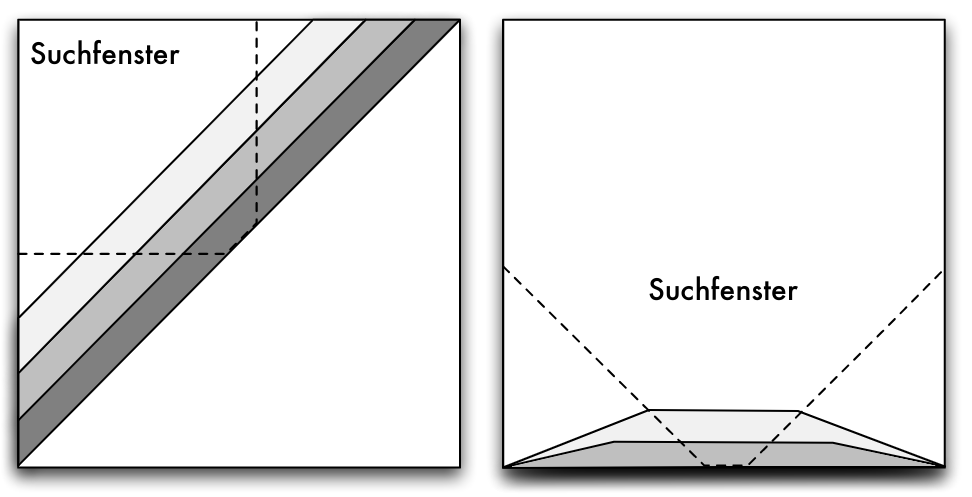
Grid-File-Degeneration
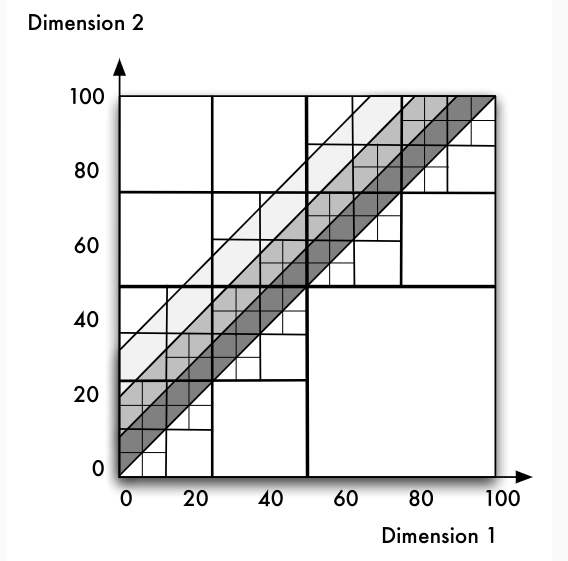
Approximierende Verfahren
Approximierende Verfahren
- insbesondere für hochdimensionale Daten
- pro Tupel einen approximierenden Bit-Code mit nur wenigen Bits pro Dimensionen
- beispielsweise ein Grid mit jeweils
2^kBit pro Dimension - ordnungserhaltend wenn die Bits geeignet gewählt werden - adressiert werden die Zellen in denen ein Punkt liegt - Nutzung zur Nachbarschaftssuche in hochdimensionalen Räumen - VA-File von Weber et al.
- ersetzt Durchlauf über alle Punkte durch Durchlauf über alle Approximationswerte zur Vorauswahl von Kandidaten
VA-File
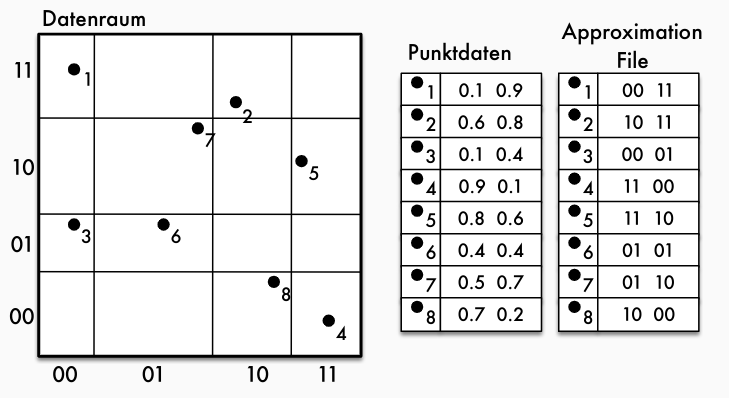
Zusammenfassung
- Bitmap-Indexe
- Digital- und Präfixbäume
- Mehrdimensionale Verfahren
- Geometrische Zugriffsstrukturen