106 KiB
| title | date | author |
|---|---|---|
| Betriebssysteme | Wintersemester 20/21 | Robert Jeutter |
- Einführung
- Prozessormanagement: Prozesse und Threads
- Grundsätzliches
- Prozesserzeugung
- Was geschieht bei der Prozesserzeugung
- Prozesserzeugung: notwenige Vorraussetzungen
- Prozesserzeugung: Namensvergabe
- Prozesserzeugung: Stammbaumpflege
- Prozesserzeugung: Allokation (Zuordnung) von Ressourcen
- Prozesserzeugung: Management Datenstrukturen
- Aktionen des Prozessmanagements
- Prozessterminierung
- Threads
- Scheduling
- Privilegierungsebenen
- Kommunikation und Synchronisation
- Speichermanagement
- Dateisystem
- Netzwerkmanagement
- E/A Systeme
- High-End-Betriebssysteme
- Abschließende Zusammenfassung und Schwerpunkte
Einführung
worauf es ankommt:
- Korrektheit
- Sicherheit
- Verfügbarkeit
- Skalierbarkeit
- Echtzeitfähigkeit
- Robustheit
- Sparsamkeit
Extrem breites Anwendungsspektrum
- funktionale Eigenschaften
- Authentisierung, Verschlüsselung
- Fahrzeug/Verkehrsmanagement
- Informationsmanagement
- Kommunikationsmanagement
- nichtfunktionale Eigenschaften
- Sicherheit
- Korrektheit
- Echtzeitfähigkeit
- Skalierbarkeit
- Offenheit
- Sparsamkeit
- Verfügbarkeit
- Robustheit
mit vielen Gemeinsamkeiten
- Architekturprinzipien
- Programmierparadigmen
voller individueller Strategien mit teils konfligierenden Zielen
- Performanz
\leftrightarrowRobustheit - Echtzeitfähigkeit
\leftrightarrowEffizienz
\Rightarrow spezialisierte Betriebssystem-Familien1. Einführung
Funktionale und nicht-Funktionale Eigenschaften
Beispiel Essen:
- funktionale Eigenschaft: es soll satt machen
- nichtfunktional: Geschmack, Aussehen,...
Funktionale Eigenschaften (= Funktionen, Aufgaben)
- Betriebssysteme: sehr komplexe Softwareprodukte
- Ein Grund für diese Komplexität: besitzen Reihe von Aufgaben - also funktionale Eigenschaften
- Hauptaufgaben dabei:
- Verwalten der Resourcen des Systems (Hard-u. Software-Ressourcen)
- Transformation der „hässlichen“ Hardwareschnittstellen in angenehme nutzerfreundliche Schnittstelle (Betriebssystem als „Erweiterung“ der Maschine, auch Hardware + BS = „virtuelle Maschine“)
- Dabei für beide Aufgaben: Schaffung sinnvoller Abstraktionen(Prozess, Datei,...
\rightarrowSoftwareressourcen)
Nichtfunktionale Eigenschaften
Wie - mit welchen speziellen weiteren Eigenschaften sollen die funktionalen Eigenschaften realisiert werden. Z.B. schon genannt:
- Echtzeitfähigkeit: Betriebssystem-Komponenten, -Algorithmen usw. mit solchen Eigenschaften realisieren, dass Betriebssystem insgesamt echtzeitfähig ist
- Robustheit: Betriebssystem-Komponenten, -Algorithmen usw. mit solchen Eigenschaften realisieren, dass Betriebssystem insgesamt robust ist
- usw
Blick in Betriebssystem-Zoo
- Mainframe Betriebssystem
- performante E/A
- Massendatenverarbeitung
- Server Betriebssystem
- viele Klienten, permanente Kommunikation
- Web Server, Fileshare
- Parallelrechner Betriebssystem
- Number Crunching, parallele Algorithmen mit hohem Rechenbedarf
- schnelle IPC
- Desktop/Laptop Betriebssystem
- Interaktivität/Responsivität
- Echtzeit Betriebssystem
- Einhaltung zeitlicher Garantien, Safety
- Fahrzeug-, Anlagensteuerung
- Eingebettete Systeme
- in Fahrzeugen, Kaffeemaschinen, Telefonen...
- z.T. Spezialaufgaben
Prozessormanagement: Prozesse und Threads
Grundsätzliches
- Computer bearbeiten Aufgaben in wohldefinierten Arbeitsabläufen (beschrieben durch Programme/Algorithmen)
- bei abarbeitung von Programmen entstehen oft Wartesituationen
- Wartezeiten sind ~ relativ zur Prozessorgeschwindigkeit ~ gigantisch (1 Sek ~ 10 Milliarden Prozessorzyklen)
- statt zu warten, lässt sich besseres tun (parallele Ausführung mehrerer Aufgaben)
- Parallelität geht nicht immer (vorraussetzung Nebenläufigkeit)
Begriffe
- Aktivitäten heißen nebenläufig, wenn zwischen ihnen keine kausalen abhängigkeiten bestehen
- Aktivitäten heißen parallel, wenn sie zeitlich überlappend druchgeführt werden
Definition Prozess: Ein Prozess ist eine Abstraktion zur vollständigen Beschreibung einer sequenziell ablaufenden Aktivität
parallele Aktivitäten werden repräsentiert durch parallele Prozesse
Prozess = betriebssystem-Abstraktion zur Ausführung von programmen
Prozessmodelle: definieren konkrete Prozesseigenschaften
Prozessmanagement: Komponente eines Betriebssystems, die Prozessmodell dieses Betriebssystems implementiert
Aufgabe: präzise Definition der Betriebssystem-Abstraktion "Prozess" (definiert durch Semantik und nichtfunktionale Eigenschaften; implementiert durch Datenstrukturen/Algorithmen)
Prozesserzeugung: Erzeugen einer Programmablaufumgebung
Prozesserzeugung
Was geschieht bei der Prozesserzeugung
- Prüfen notwendiger Vorraussetzungen (Rechte, Ressoucenverfügbarkeit,...)
- Namensvergabe und "Stammbaumpflege"
- Allokation von Ressourcen (Arbeitsspeicher, Prozessorzeit)
- Anlegen von Managementstrukturen (belegte Ressourcen, Laufzetmanagement)
Prozesserzeugung: notwenige Vorraussetzungen
- Rechte: zur Prozesserzeugung und Ressourcenallokation (Kontingente)
- Ressourcenverfügbarkeit (Arbeitsspeicher, Rechenzeit, Kommunikation)
- Sicherheit (Authentizität und Integrität des auszuführenden Programms)
- bei Echtzeitbetriebssystem
- Erfüllung von Ressourcenanforderung
- Einhaltung gegebener Garantien
- Fairness (Quoten)
- robustheit/Überlastvermeidung (Lastsituation)
Prozesserzeugung: Namensvergabe
Identifikation ist positive ganze Zahl durch Vergabe Algorithmus. Kann nach Terminierung eines Prozesses erneut vergeben werden
- eindeutig: zu einem Zeitpunkt bzgl aller existierenden Prozesse
- nicht unbedingt eindeutig: für zeitlich nicht überlappende Prozesse
- erst recht nicht eindeutig: über Systemgrenze hinweg
Prozesserzeugung: Stammbaumpflege
Abstammungsbeziehung: definieren Eltern/Kind Hierarchie
- Prozess erzeugt weitere Prozesse: Kinder
- diese wiederum erzeugen weitere Prozesse usw -> baumartige Abstammungshierarchie Nutzung: Rechte und Verantwortlichkeiten
Verwaiste Prozesse -> Adoption (durch Urprozess)
Prozesserzeugung: Allokation (Zuordnung) von Ressourcen
- Arbeitsspeicher
- Größe: Wie viel Arbeitsspeicher benötigt der Prozess?
- Zeitpunkt: zu welchem Zeitpunkt? Echtzeiteigenschaften (Planbarkeit) oder Performanz (proaktivität)?
- Isolation: wie ist er geschützt? (Robustheit, Sicherheit, Korrektheit)
- Prozessorzeit
- in Prozessmodellen echtzeitfähiger Systeme: Größe und Zeitpunkt
- in Prozessmodellen ohne diese Eigenschaften: dynamisches ad-hoc-Scheduling
für richtige Initialisierung: präzise Formatvereinbarung zwischen
- Linker (Programmdatei-Produzent)
- Prozessmanagement des BS (Programmdatei Nutzer)
- das a.out-Format (veraltet; ursprünglich Unix Format)
- das Mach Object File Format (Mach-O; heutiger Standard für OS X, iOS)
- das Executable and Link(age/able) Format (ELF; heutiger Linux standard)
Prozesserzeugung: Management Datenstrukturen
Buchführung über sämtliche zum management notwendigen Informationen
- Prozessidentifikation
- Rechtemanagement
- Speichermanagement
- Prozessormanagement
- Kommunikationsmanagement
a. Prozessdeskriptor (process control block ~ PCB) b. Prozessdeskriptortabelle: Deskriptioren sämtlicher Prozesse
| Prozessormanagement (Prozessdeskriptor) | | | Identifikation | eindeutige Prozessbezeichnung; einordnung in Abstammungshierarchie | | Scheduling | Informationen für Schedulingalgorithmen | | Prozessorkontext | gesichert bei Verdrängung des Prozesses, restauriert bei Reaktivierung | | Ereignismanagement | what if... | | Accounting (Kontoführung) | zur Prioritätsbestimmung, Statisik, kostenberechnung | | Virtueller Adressraum | Beschreibung des Speicherlayouts | | Kernel Stack | Prozedurmanagement innerhalb des BS | | Rechtemanagement | | | Allgemeines Ressourcenmanagement | Filedeskriptoren, Socketdeskriptoren,... |
Aktionen des Prozessmanagements
- Prüfen notweniger Vorraussetzungen
- Namensvergabe und Stammbaum
- Allokation von Ressourcen
- Anlegen von Managementdatenstrukturen (Prozessdeskriptor)
Prozessterminierung
durch
- Aufgabe erledigt
- Fehler aufgetreten
- durch Nutzer/Eigentümer geschlossen
- ...
- Freigabe der Ressourcen
- Benachrichtigung der "Eltern"
- Adoption der "Kinder"
Threads
Naive Lösung: für jede nebenläufige Aktivität einen Prozess erstellen. Jedoch hat ein Prozess:
- Kosten des Managements
- kosten der isolation
- Kosten der Kommunikation
\rightarrow Parallelität mittels Prozessen ist teuer (revidiertes Prozessmodell)
Daher suche nach kostengünstigerem Modell zur Parallelisierung nebenläufiger Aktivitäten
Definition Prozess: Ein (Multithread-) Prozess ist eine vollständige Beschreibung einer ablaufenden Aktivität. Dazu gehört insbesondere
- Das ablaufende Programm
- zugeordnete Betriebsmittel
- Rechte
- prozessinterne parallele Aktivitäten (Threads) und ihre Bearbeitungszustände
Definition Thread: ist eine sequenzielle Aktivität im Betriebsmittelkontext (d.h. innerhalb) eines Prozesses
parallele Aktivitäten innerhalb eines Prozesses werden durch parallele Threads repräsentiert.
Anmerkung:
- Eigentümer von Ressourcen und Rechten sind immer noch prozesse
- das Programm eines Prozesses kann nun Code für mehr als eine sequenzielle Aktivität enthalten
- Gegenstand der Prozesszuteilung sind nun Threads
- das ursprüngliche Prozessmodell ist eine Spezialisierung dieses Modells (ein Prozess mit genau einem Thread)
- ein Prozessdescriptor (PCB) eines Multithread-Prozessmodells enhält alle Informationen des PCBs eines Single-Thread-Prozessmodells plus Informationen über alle seine Threads
- ein TCB enthält lediglich den Threadszustand und den Ablaufkontext
Threads werden daher oft als Leichtgewichtprozesse bezeichnet
Threads treten in verschiedenen Varianten auf
- komfortabel (integriert in Programmiersprache)
- "zu Fuß" (durch Bibiliotheken oder API)
Implementierungsebenen
- Prozessmodell des Betriebssystems ist Multithread Modell
- Thread Implementierung im Betriebssystem
- das Betriebssystem hat Kenntnis über Threads
- Kernel Level Threads (KLTs)
- Prozessmodell des Betriebssystems ist Single-Thread-Modell
- Thread Implementierung auf Anwendungsebene
- nur auf Endbenutzer-Ebene ist Kenntnis über Threads
- User Level Thread (ULTs)
| Pro KLT | Pro ULT | | Performanz durch Parallelität | Performanz durch geringen Overhead | | Nutzung von Mehrprozessor/Mehrkernarchitektur | Thread Management ohne Systemaufrufe | | ein blockierender Systemaufruf in einem Thread blockiert nicht auch gleichzeitig alle anderen Threads des gleichen Prozesses | Thread Umschaltung ohne Mitwirkung des Betriebssystems | | | Individualität: anwendungsindividuelle Thread Schedulingstrategien möglich | | | Portabilität |
es gibt Work-Arounds: alle gefährlichen Systemaufrufe einpacken (in Pakete)
Wahl zwischen ULT- und KLT hängt ab von:
- Vorraussetzung: Prozessmodell des Betriebssystems Multithread Modell?
- Anwendungsprofil: E/A-Profil, Parallelität, Portabilität, Individualität
Scheduling
Das Problem
Anzahl der Aktivitäten >> Anzahl der Prozessoren
- nicht alle können gleichzeitig arbeiten
- eine Auswahl muss getroffen werden
- Auswahlstrategie: Schedunling-Strategie/Algorithmus
- die Betriebssystem Komponente Scheduler
- Ziel: Effizientes Ressourcenmanagement
Threads können
- aktiv sein (besitzt einen Prozessor)
- rechenbereit sein (Bsp. hätte gerne einen Prozessor)
- kurzfristig warten (Bsp. benötigt keinen Prozesoor aber Arbeitsspeicher)
- langfristig warten (Bsp. benötigt länger keinen Prozessor/Arbeitsspeicher)
Threadzustände im 3/5-Zustandsmodell
- bereit: kann aktiv werden, sobald Prozessor frei wird
- aktiv: besitzt einen Prozessor, arbeitet
- blockiert: wartet auf Ereignis (Timer Ablauf,...)
- frisch: erzeugt, Betriebsmittel/Rechte zum Ablauf fehlen noch
- beendet: Betriebsmittel in der Freigabephase
Folge: effizientes Ressourcenmanagement benötigt präzise Informationen über Threadzustände.
Aufgabe der Zustandsmodelle
Beschreibung:
- des Ablaufzustands von Threads (aktiv/bereit/wartend)
- der mögliche Zustandsübergänge (z.B. bereit->aktiv)
Nutzung
- jeder Thread ist zu jedem Zeitpunkt in genau einem dieser Zustände
- jeder Thread wechselt seinen Zustand gemäß der im Modell definierten Zustandsübergänge, hervorgerufen durch z.B. Zuteilung eines Prozessors
- Ressourcenmanagement: nutz Zustand als Informationsquelle für Entscheidungen
Beschreibungsmittel: endliche deterministische Automaten
- Menge der annehmbaren Zustände ist endlich
- Folgezustand ist immer eindeutig bestimmt
Scheduleraktivierung
Wann wird die letzte Scheduling-Entscheidung überprüft?
- Prozess/Thread erzeugung (neuer, rechenbereiter Thread)
- Threadterminierung, Threadblockierung (ein Prozessor wird frei)
- Ereigniseintritt (Thread wird rechenbereit)
- Wechsel von Prioritäten (in prioritätenbastierten Schedulingalgorithmen)
- periodisch (in zeitscheibenbasierten Schedulingalgorithmen)
Ein Kontextwechsel umfasst:
- bei Wechsel zwischen Threads desselben Prozesses
- Stackkontext
- Prozessorregister
- floating point unit (hohe Kosten) (FPU)
- zusätzlicher Wechsel zwischen Threads verschiedener Prozesse
- Speicherlayout (sehr hohe Kosten)
- starke Auswirkungen auf
- Gesamtperformanz
- Reaktivität
- Echtzeiteigenschaften
Kostenfaktor FPU
- Kopieren des FPU-Kontexts: sehr viele Register (sofortkosten)
- Realisierung: "faul"
- Hardware hilft: FPU Protection
- Auswirkung
- nur ein Thread benutzt FPU: tatsächliches Sichern erfolgt nie
- wenige Threads benutzen FPU: tatsächliches Sichern minimiert
Scheduling Strategien
Strategische Ziele
- abhängig vom Einsatzfeld eines Betriebssystems
- Echtzeitsysteme: Einhaltung von Fristen
- interaktive Systeme: Reaktivität
- Serversysteme: Reaktivität, E/A-Performanz
- Batch-Verarbeitungssysteme: Durchsatz
- ergänzt durch allgemeine Ziele
- Fairness: Threads bekommen einen fairen Anteil an Rechenzeit
- Lastbalancierung: alle Systemkomponenten (CPUs, Speicher, E/A-Peripherie) sind gleichmäßig ausgelastet
- Overhead: z.B. wenig Prozesswechsel
- Ausbalancierung mehrerer Ziele
- multikriterielle Optimierungsaufgabe, i.d.R. NP-vollständig
- heuristische Scheduling-Algorithmen
Typische Muster aktiver Threadphasen:
- CPU lastig (mathematische Berechnung, Verschlüsselung,...)
- E/A lastig (interaktiver Prozess, ...)
- periodische Last (Echtzeitvideoverarbeitung, ...)
- chaotische Last (server mit inhomogenen Diensten)
Differenzierte Scheduling-Strategien
- nutzen Wissen über Lastmuster zur Optimierung, z.B.
- Einhaltung von Fristen
- Minimierung der Thread/Prozesswechsel
Batch-System („Stapelverarbeitungs“-System)
- Aufträge: in Gruppen („Stapel“) eingeteilt u. so verarbeitet
- Abarbeitung: ohne aktive Mitwirkung eines Benutzers (Gegensatz: interaktiv)
- ursprünglich: frühe Entwicklungsstufe von Betriebssystemen
Ziele hier
- Auslastung teurer Betriebsmittel (i.d.R. Maximierung der CPU-Auslastung)
- Minimierung der Scheduling-Kosten (wenig Prozesswechsel, kurze Laufzeit des Scheduling-Algorithmus)
- Maximierung des Durchsatzes (erledigte Arbeit / Zeit)
zwei der bekannteren:
- First Come, First Served (FCFS)
- in Reihenfolge, in der Threads rechenbereit werden
- extrem einfache Strategie, guter Durchsatz
- nicht immer sehr klug
- Shortest Remaining Time Next (SRTN)
- Prozessor erhält Thread mit voraussichtlich kürzester Restrechenzeit
- preemptiv* ) , d.h. Threads können von konkurrierenden Threads verdrängt werden
- (Schätzwert über) Restlaufzeit muss vorliegen
Interaktives System
- Benutzer: kann bei Programmabarbeitung in Aktivitäten des Computers eingreifen
- Abarbeitung: mit aktiver Mitwirkung eines Benutzers (Gegensatz: batch processing)
- fortgeschrittenere Betriebssystem-Technik
Ziele hier
- Minimierung von Reaktionszeiten (subjektiver Eindruck von Performanz)
- Fairness (mehrere Benutzer/Klienten)
Algorithmen: Round Robin Varianten
- jeder Thread: bekommt ein gleich großes Teil „des Kuchens“: die Zeitscheibe
- einfach zu implementieren (1 Warteschlange, Uhr)
- geringe Algorithmuskosten (O(1): FIFO-Warteschlange, Ring)
- schnelle Entscheidungen (O(1): Nr. 1 aus Warteschlange)
- notwendiges Wissen gering (CPU-Nutzungsdauer des aktiven Threads)
Einbeziehung von Prioritäten
Ziel: Ausdrucksmöglichkeit der Wichtigkeit von Threads
- niedrig: z.B.
- Dämonen (die z.B. im Hintergrund Emails abrufen)
- Putzarbeiten (z.B. Defragmentierung)
- hoch: z.B.
- auf Aufträge reagierende Threads (z.B. in Servern)
- auf Benutzereingaben reagierende Threads (z.B. aktives Fenster einer GUI)
- unter Echtzeitbedingungen arbeitende Threads (z.B. Motormanagement, DVD-Spieler)
Idee(n)
- jeder Thread: erhält individuelle Priorität
- Threads der höchsten Prioritäten: erhalten einen Prozessor
- zwischen Threads gleicher Priorität: Round-Robin
viele Varianten dieses Schemas
- statische Prioritäten, z.B. in
- planbaren Echtzeitsystemen (Autoradio: Reaktion auf Stationswechseltaste hat Vorrang vor Senderfeldstärkenüberwachung)
- kommerziellen Rechenzentren (wer mehr zahlt, ist eher an der Reihe)
- dynamische Prioritäten, abhängig z.B. von
- verbrauchter CPU-Zeit (Verhinderung der Dominanz)
- E/A-Intensität
- Wartegrund
Schedulingziele in Echtzeitsystemen
Finden einer Bearbeitungsreihenfolge (ein „Schedule“),
- die Fristen einhält
- deren Berechnung ökonomisch ist (Kosten des Scheduling-Algorithmus)
- die selbst ökonomisch ist (Minimierung der Threadwechsel)
- die sich (evtl.) an wechselnde Lastmuster anpasst
Verbreitete Algorithmen
- EDF: früheste Frist zuerst (earliest deadline first)
- für dynamische Lasten
- wird ein Thread rechenbereit, so „nennt“ er seine nächste Deadline (Frist)
- von allen bereiten Threads ist immer derjenige mit der frühesten Deadline aktiv (dringend=wichtig)
- Folglich
- arbeitet der Algorithmus mit dynamischen Prioritäten → adaptiv
- ist die Thread-Priorität um so höher, je näher dessen Frist liegt
- ist er preemptiv
- Voraussetzung: kausale und zeitliche Unabhängigkeit der Threads (keine wechselseitige Blockierung)
- RMS: Raten-monotones Scheduling (rate-monotonic scheduling)
- für periodische Lasten (z.B. Mischpult, DVD-Spieler, technische Prozesse)
- wird ein Thread rechenbereit, so „nennt“ er seine Periodendauer
- von allen bereiten Threads ist immer derjenige mit der kürzesten Periodendauer aktiv
- Folglich:
- arbeitet der Algorithmus mit statischen Prioritäten
- ist die Thread-Priorität um so höher, je kürzer die Periodendauer ist
- ist er preemptiv
- Voraussetzung: periodische Threads; kausale und zeitliche Unabhängigkeit der Threads
Zusammenfassung
Anzahl der Threads >> Anzahl der Prozessoren
- nicht alle können gleichzeitig rechnen
- eine Auswahl muss getroffen werden
- → Auswahlstrategie: Schedulingalgorithmen
Privilegierungsebenen
Problematik: Anwendungsprozesse und Betriebssystem nutzen gemeinsame (Hardware-)Ressourcen
Schutz vor fehlerbedingten oder bösartigen räumlichen/zeitlichen Wechselwirkungen
2 Konzepte
- private Adressräume
- Zugriffsschutz auf Arbeitsspeicherbereiche
Verhinderung zeitlicher Wechselwirkungen
- Ursache: Prozesse geben freiwillig keine Prozessoren auf
- Umgang damit
- periodische Aktivierungen preemptiver Scheduler (Uhr)
- Scheduler-Aktivierungen durch asynchrone Ereignisse
- kritisch also: Operationen zum Abschalten von
- Uhr
- Ereignismanagement
- weitere kritische Operationen
- Veränderung des Speicherlayouts
- Veränderung kritischer Prozessorkontrollregister
- Zugriff auf E/A-Geräte
- notwendig: Schutz kritischer Operationen des Instruktionssatzes
Lösungskonzept: Privilegierungsebenen ablaufender Aktivitäten, z.B.
- „kernel mode“ (≈ Betriebssystem-Modus)
- „user mode“ (Nutzer-Modus)
- ermöglichen: Durchsetzung von Regeln:
- „Nur eine im „kernel mode“ ablaufende Aktivität hat Zugriff auf ...“
- Privilegierungsebenen steuern Rechte ...
- zur Ausführung privilegierter Prozessorinstruktionen
- zur Konfiguration des Arbeitsspeicher-Layouts
- zum Zugriff auf Arbeitsspeicherbereiche
- zum Zugriff auf E/A-Geräte
Realisierung: abhängig von Prozessorarchitektur
- in Ringen 0 (höchste Priorität) bis 3 (niedrigste Priorität)
Implementierung: Hardware-Unterstützung
- aktuelle Privilegierungsebene ist
- Teil des Prozessor-Statusregisters: „Current Privilege Level“ (CPL)
- Grundlage der Hardware-Schutzmechanismen; permanente Überwachung
- der ausgeführten Instruktionen
- der Arbeitsspeicherzugriffe
- der E/A-Peripheriezugriffe
- Modifikation des CPLs nur
- durch privilegierte Instruktionen
- bei Beginn und Abschluss
- des Aufrufs von Systemdiensten
- einer Ereignisbehandlung
Botschaften
- jede auf Privilegierungsebene < 3 ablaufende Aktivität hat Zugriff auf kritische Ressourcen
- jede auf Privilegierungsebene 0 ablaufende Aktivität hat Zugriff auf
- sämtliche Ressourcen eines Prozessors
- sämtliche Instruktionen (z.B. HALT)
- sämtliche Prozessorregister (z.B. Prozessor-Status-Register (PSR) )
- MMU-Register zur Arbeitsspeicherkonfiguration
- sämtliche Register der E/A-Peripherie
Sämtliche Schutz- und Sicherheitsmechanismen von
- Anwendungsprozessen
- Betriebssystem beruhen elementar auf 2 Bits: „Current Privilege Level“ (CPL) im Prozessor-Status-Register (PSR)
Kommunikation und Synchronisation
Elementare Konzepte
Beispiele:
- Aufträge an Geräte und (Dienstleistungs-)Prozesse, z.B.
- Kooperative Arbeit von Betriebssystem-Komponenten
- Arbeit verschiedener Betriebssystemkomponenten mit (gemeinsamen) Management-Datenstrukturen
- Interaktionen zwischen Anwendungsprozessen
Die Auftragstabelle ist eine (Software-)Ressource.
- Problem: ein Fehler entsteht dadurch, dass zwei (oder mehr) Prozesse oder Threads „durcheinander“ auf der Ressource arbeiten
- Lösung: Unkoordiniertes Arbeiten mit der Ressource muss verhindert werden! Erst wenn ein Prozess (oder Thread) seine Arbeit mit der Ressource vollständig abgeschlossen hat, darf der nächste aktiv werden. Die Befehlsfolge innerhalb der Prozesse, während deren Abarbeitung auf die Ressource zugegriffen wird, ist ein kritischer Abschnitt.
- Außerdem: genauere Betrachtung eines einzelnen Auftrags; kann aus mehreren Komponenten bestehen
- Problem: durch „unkoordiniertes“ Arbeiten mehrerer Threads kann es auch bei den Auftrags-Einträgen zu Inkonsistenzen kommen
Fazit:
- Gesamte Arbeit an Auftragstabelle ist kritischer Abschnitt.
- Nur 1 Thread darf zu einem Zeitpunkt mit Auftragstabelle arbeiten.
- Erst wenn dieser Arbeit beendet hat, darf ein neuer Thread mit der Auftragstabelle arbeiten.
Definitionen:\ Es gibt Ressourcen, die als ganzes oder bzgl. einzelner Operationen nur exklusiv, d.h. zu einem Zeitpunkt nur durch einen einzigen Thread nutzbar sind.
- Eine Phase, in der ein Thread eine exklusive Operation auf einer Ressource ausführt, heißt kritischer Abschnitt.
- Kritische Abschnitte erfordern den wechselseitigen Ausschluss (die Isolation) konkurrierender Threads bzw. Prozesse.
Beispiel 2: Kommunikation von 2 Prozessen über gemeinsamen Speicherbereich („Erzeuger-Verbraucher-Problem“)
- Problembeschreibung:
- Ein Prozess schreibt Daten in den Speicherbereich ...
- Der zweite Prozess liest diese Daten ...
- Die Datenmenge ist so umfangreich, dass dieser Vorgang mehrmals (abstrahiert: unendlich oft) wiederholt werden muss.
-
- Problem (Puffer voll, Puffer leer); unterschiedliche Geschwindigkeiten von Erzeuger und Verbraucher
-
- Problem (Puffer wird gerade benutzt); gleichzeitiges Lesen und Schreiben des selben Pufferelements
Algorithmen zum wechselseitigen Ausschluss
Genauere Definition des Problems (Annahmen)
- konkurrierende Threads arbeiten asynchron, z.B. in einer unendlichen Schleife
- dabei betreten und verlassen sie irgendwann einen kritischen Abschnitt
- Betreten und Verlassen dieses Abschnitts: wird durch Algorithmen organisiert, die den kritischen Abschnitt umgeben (Entry/Exit-Code)
Grundsätzliche Anforderungen
- Korrektheit: In einem kritischen Abschnitt befindet sich zu jedem Zeitpunkt höchstens ein Thread (wechselseitiger Ausschluss).
- Lebendigkeit: Falls ein Thread einen kritischen Abschnitt betreten möchte, dann betritt (irgendwann) (irgend-) ein Thread diesen Abschnitt. [Folglich kann irgendwann auch der erstgenannte Thread den kritischen Abschnitt betreten.]
- Verhungerungsfreiheit: Kein Thread wartet für immer vor einem kritischen Abschnitt.
Wechselseitiger Ausschluss: ein erster (naiver) Versuch
- Ideen
- während Benutzung des Puffers: wird dieser als „busy“ markiert
- bei Vorfinden eines so markierten Puffers: wird gewartet
- Verhungern: z.B. bei Pseudoparallelität (fortwährende Unterbrechung des Writers im kritischen Abschnitt)
Synchronisations- & Kommunikationsmechanismen
- Austausch von Daten zwischen Prozessen
\rightarrowKommunikation (Inter-Prozess-Kommunikation, IPC) - Abweichende Geschwindigkeiten von Sender und Empfänger
\rightarrowSynchronisation
Betrachtete Mechanismen:
- Semaphore
- Hoare ́sche Monitore
- Transaktionalen Speicher
- Botschaften
- Fernaufrufe
(binäre) Semaphore
Idee: Flagge
- mit 2 Zuständen
- frei
- belegt
- mit 2 atomaren Operationen
- belegen: P( Semaphorname ) („Passeren“)
- freigeben: V (Semaphorname) („Vriegeven“)
- Sämtliche Nutzer dieses kritischen Abschnitts müssen diese semaphore verwenden (Entry-/Exit-Code, Türwächter)
- besser: kein aktives Warten
// pic ← codePicFromCamStream();
if bufferBusy.zustand = frei then
bufferBusy.zustand ← belegt
else
bufferBusy.warteliste ← aufrufer
fi
//write(buffer, pic);
if bufferBusy.warteliste = leer then
bufferBusy.zustand ← frei
else
bufferBusy.warteliste.vorne.continue
fi
Implementierung von Semaphoren z.B. als Klasse (Objekt-Orientiert),
- die die Methoden P und V exportiert
- mit einer lokalen Thread-Warteliste
- mit (aus dem Maschinenraum) importierten Operationen atomicBegin und atomicEnd, die Atomarität herstellen
P(semaphore s) {
atomicBegin(s);
if (s.zustand = frei)
s.zustand ← belegt;
else
s.warteliste ← aufrufer;
scheduler.suspend(aufrufer);
fi
atomicEnd(s);
}
V(semaphore s) {
atomicBegin(s);
if (s.warteliste = leer)
s.zustand ← frei;
else
scheduler.continue
(s.warteliste.vorne)
fi
atomicEnd(s);
}
Unterstützung durch Hardware: die TSL-Operation
- Atomarität
- Ausschluss paralleler Ausführung → TestAndSetLock („TSL“) im Instruktionssatz eines Prozessors
atomicBegin(s):
TSL s.state, callingThread.Id // try to get lock
CMP s.state, callingThread.Id // did I get it?
JZE gotIt // yes
CALL scheduler.yield // optional in manycores, mandatory
// in monocores: yield processor
JMP atomicBegin // try again
gotIt: RET // got it, may enter critical region
Nutzung von Semaphoren:
- Multi-Thread-Anwendungen (Webserver, PowerPoint, etc.)
- auf Betriebssystem Ebene von allen nebenläufigen Aktivitäten
Implementierung
- im Ressourcenmanagement des Betriebssystems
- mit Hilfe des „Maschinenraums“: atomicBegin(s), atomicEnd(s)
!ungelöst: Geschwindigkeitsdifferenz
//Writer-Thread:
forever do {
codePicFromCamStream(pic);
P(bufferEmpty);
P(bufferBusy);
write(buffer,pic);
V(bufferBusy);
V(bufferFull);
}
- bufferBusy: verhindert gleichzeitigen Zugriff
- bufferEmpty: gibt Weg frei, wenn der Puffer leer ist
- bufferFull: gibt Weg frei, wenn er gefüllt ist
Mehrwertiger Semaphor (oder Zählsemaphor) mit mehreren Semaphoren; maximaler Sem-Wert = n, bestimmt maximale Anzahl von Threads, die gleichzeitig aktiv sein können
Zusammenfassend:
| bei Eintritt in kritischen Abschnitt | Bei Verlassen eines kritischen Abschnitts |
|---|---|
| P(Sem) - binärer Semaphor | V(Sem) - binärer Semaphor |
| Down(Sem) - Zählsemaphor | Up(Sem) - Zählsemaphor |
| Wait(Sem) - allgemein | Signal(Sem) - allgemein |
| Haben die gleiche Wirkung auf den Wert des Semaphors: | Haben die gleiche Wirkung auf den Wert des Semaphors: |
| - Dekrementieren, bis Wert „Null“ erreicht | - Inkrementieren des Semaphorwertes |
| - Trifft ein Thread auf den Wert „Null“, wird dieser blockiert (und in eine Warteliste eingefügt) | |
| - Nimmt der Semaphor wieder einen Wert > 0 an, setzt (normalerweise) erster Thread in Warteliste fort |
Hoare'sche Monitore
- Problem bei Anwendung von Semaphoren: Softwarequalität
- Problematisch in größeren Systemen:
- Synchronisationsoperationen (P und V)
- umgeben kritische Operationen (z.B. read/write)
- müssen explizit gesetzt werden
- Synchronisationsoperationen (P und V)
Korrektheitsproblem. Die unabdingbare
-
Vollständigkeit
-
Symmetrie der P- und V-Operationen ist schwierig erreichbar und nachweisbar.
-
Die Idee: implizite/automatische Synchronisation kritischer Operationen
-
Der Weg: Nutzung des Prinzips der Datenabstraktion
- Zusammenfassung von Daten, darauf definierten Operationen und der Zugriffssynchronisation zu einem abstrakten Datentyp, dessen Operationen wechselseitigen Ausschluss garantieren
- Zugriff auf Daten: über implizit synchronisierende Operationen („Inseln der Ruhe“ in turbulenten Multithread-Umgebungen)
- Die kritischen Abschnitte und die zugehörigen Daten liegen jetzt in einem durch einen Monitor geschütztem Bereich
Aufrufer muss nicht wissen
- ob Synchronisation nötig ist
- mit welchen Mechanismen dies erfolgen muss
- welche Regeln dabei gelten
Ziel der Regeln\ Wechselseitiger Ausschlusses der Monitoroperationen ⟺ zu jedem Zeitpunkt ist höchstens ein Thread in einem Monitor aktiv
- Jede Monitoroperation ist am Eingang und an den Ausgängen durch einen Türsteher gesichert
- Das Betreten des Monitors erfolgt nur mit dessen Zustimmung („Anklopfen“)
- Falls ein anderer Thread im Monitor aktiv ist, wird die Zustimmung verweigert und der anklopfende Thread suspendiert (
\approxP-Operation) - Wenn ein Thread den Monitor verlässt, wird ein wartender Thread eingelassen (fortgesetzt), (
\approxV-Operation) - Gerät ein Thread innerhalb einer Monitoroperation in eine Wartesituation (Warten auf Bedingungsvariable), so verlässt er den Monitor
- Bevor ein auf eine Bedingung wartender Thread fortgesetzt wird, muss er wieder am Türsteher vorbei
Implementierung der Regeln basierend auf Semaphoren
- je Monitor: ein Semaphor
- jede Operation eines Monitors enthält
- am Eingang: eine P-Operation
- an jedem (!) Ausgang: eine V-Operation
\rightarrowwechselseitiger Ausschluss
Bedingungsvariable „Puffer nicht voll“, „Puffer nicht leer“ mit 2 Operationen:
- Warten auf das Vorliegen der Bedingung
- Signalisieren des Vorliegens der Bedingung
\rightarrowMonitore mit Bedingungsvariablen
Monitore: komfortabler Mantel für Semaphore
Allgemeines Erzeuger/Verbraucher-Problem Lösung 2er Aspekte der Synchronisation
- wechselseitiger Ausschluss der Zugriffe auf gemeinsame Daten („buffer“)
- durch wechselseitigen Ausschluss von Monitoroperationen
- kurzzeitiges Ausbremsen
- Anpassung unterschiedlicher Geschwindigkeiten von Erzeuger und Verbraucher
- durch Warten auf und Signalisieren von Bedingungen (nonFull, nonMt)
- längerfristiges Ausbremsen
Methoden und Mechanismen verwendbar für
- Threads und Prozesse innerhalb eines Betriebssysteme
- Threads innerhalb eines Anwendungsprozesses
- Anwendungsprozesse untereinander (notwendig: gemeinsamer Speicher!)
weitere Konzepte
Transaktionaler Speicher
Problem: Semaphore/ Hoare‘sche Monitore lösen das Problem wechselseitigen Ausschlusses durch Sperren. damit: Verhinderung paralleler Abläufe (da in einem kritischen Abschnitt jeweils nur ein Thread aktiv sein kann, werden gegebenenfalls weitere Threads blockiert, und somit für bestimmte Zeit von der Bearbeitung ausgeschlossen, d.h. also zeitweilig gestoppt)
Lange Zeit war Performanz sehr bequem/ Wachsende Leistung der Hardware durch:
- Erhöhung der Taktfrequenz
- Erhöhung der Transistorzahl
- Pipelining: Zerlegung und fließbandartige parallele Abarbeitung einzelner Instruktionen
- Hyperthreading: Lückenfüllung in den Pipelines durch Füttern aus verschiedenen Threads
- spekulative Ausführung von Instruktionsfolgen
- Arbeitsspeichercaches
- TLBs
- für Software weitgehend unsichtbar
- vertraute sequenzielle Programmierparadigmen ausreichend
Diese Ära ist beendet
- physikalische Aspekte der Energieverteilung/Wärmeableitung auf Chip; Limitierung der Steigerung der Taktfrequenz
- logische Aspekte der Instruktionsausführung; Limitierung spekulativer Ausführung und Instruktionsparallelität Weitere Leistungssteigerung
- durch Paradigmenwechsel der Prozessorarchitektur: Multicore-Prozessoren
- dadurch bedingt: Paradigmenwechsel der Software: Parallele (und verteilte) Algorithmen
Parallele Algorithmen
- erfordern:
- hochparallele, sperrenfreie Synchronisationsmodelle
- Konzept: transaktionaler Speicher
- Beobachtung:
- nicht jede konkurrente Benutzung kritischer Abschnitte durch mehr als 1 Thread verursacht Fehler
- Pessimistische Herangehensweise:
- „Aussperren“ weiterer Threads (z.B. durch Semaphore u. Monitore)
- Dadurch: ausgesperrte Threads werden am Weiterkommen gehindert (Performanzverluste besonders bei intensiver Parallelarbeit)
- Optimistische Herangehensweise:
- Kein „Aussperren“ von Threads (z.B. durch Semaphore u. Monitore)
- Hinterher: Untersuchung auf Fehler und Korrektur, z.B. durch erneuten Versuch
- Geeignete Verfahrensweise:
- Kombination mit Transaktionen (-> transaktionaler Speicher)
- Transaktionen:
- stammen aus der Datenbanktechnik
- ermöglichen u.a.: Zurückfahren fehlerhaft ausgeführter Programmabschnitte (genannt Transaktionen) u. Wiederholung von deren Ausführung auf elegante Weise
Botschaften
Problem: Semaphore/Hoare‘sche Monitore/Transaktionaler Speicher erfordern zu ihrer Implementierung gemeinsamen Speicher der Beteiligten
Gibt es nicht
- falls die Beteiligten auf unterschiedlichen Rechnern ablaufen
- falls die Beteiligten disjunkte Adressräume besitzen
- in lose gekoppelten Multiprozessor-Architekturen Hierfür: muss ein anderes Kommunikationsparadigma her
2 elementare Operationen
- Senden einer Botschaft an einen Empfänger
send(IN Empfänger, IN Botschaft) - Empfangen einer Botschaft von einem Absender
receive(OUT Absender, OUT Botschaft)
Anmerkungen
- genutzt: für Kommunikation zwischen
- Prozessen innerhalb eines (Mikrokern-) Betriebssystems
- Anwendungsprozesse untereinander (Klienten, Server)
- Betriebssysteme: implementieren send/receive-IPC
- Anwendungsprozesse: nutzen Bibliotheken oder Betriebssystem-Dienste,
Fernaufrufe (Remote Procedure Calls, RPCs)
- Problem
- Datenmodell des send/receive-Modells: Zeichenfolge
\rightarrowsehr primitiv - gewohnte Datenmodelle z.B. aus Programmiersprachen
\rightarrowSignaturen (Methodenaufruf, typisierte Parameterlisten)
- Datenmodell des send/receive-Modells: Zeichenfolge
- Idee: Anpassung eines
- anwendungsnahen,
- unkomplizierten und
- vertrauten
- Kommunikationsmodells an die Eigenschaften verteilter Systeme:
- Prozedurfernaufruf (Remote Procedure Call, RPC)
- Methodenfernaufruf (Remote Method Invocation, RMI
\rightarrowObjekt-orientiert)
Grundidee dieser Architekturform
- elementare Betriebssystem-Funktionalität:
- in sehr kleinem, hochprivilegiertem Betriebssystemkern ( Kern)
- typische Aufgaben: Threads, Adressräume, IPC
- weniger elementare Aufgaben: -schwächer privilegiert ( reguläre Anwendungssysteme = „Nutzerprozesse“)
- Folgen
- Isolation der Betriebssystem-Komponenten
- → Robustheit (Fehlerisolation)
- → IT-Sicherheit [Security] (TCB-Größe)
\rightarrowTCB: Trusted Computing Base - → Korrektheit (Verifizierbarkeit)
- → Adaptivität (Auf- und Abskalierung der Systemfunktionalität)
- → Kommunikationskosten
- Isolation der Betriebssystem-Komponenten
Kommunikationskosten
- Prozeduraufruf: monolithische Architektur: innerhalb eines Adressraums
- Prozedurfernaufruf: $\mu$-Kern-Architektur: über Adressraumgrenzen hinweg
Systemaufrufe
Problem: Kommunikation Anwendungsprozess ↔ BS
- BS stellt zahlreiche Dienste bereit (Linux 250, Apple OS X 500); z.B.
- Prozesserzeugung (fork)
- Programmausführung (exec∗)
- Dateimanagement (open, close, read, write)
- Kommunikation (msg∗, socket, shm∗)
- In diesem Abschnitt: Aufrufmethoden und -mechanismen
- Wünsche des Anwendungsentwicklers
- Bequemlichkeit
- Performanz (hohe Aufruffrequenz, tausende pro Sekunde)
- Wünsche des Betriebssystem-Entwicklers
- Sicherheit
- Robustheit
- reguläre Prozeduraufrufe: erfüllen Kriterien nicht (isolierte Adressräume, Privilegien, Programmiersprachen)
- Prozedurfernaufrufe:
- bequem, performant, sicher, robust
- teuer
- gesucht: leichtgewichtiges RPC-Modell
- Problem: Unterschiedliche Programmiersprachen
- kein einheitliches Format der Aufrufparameter (Reihenfolge, Format)
- Lösung: normierte Parameterstruktur und Datentyprepräsentation zwischen Anwendungsprogramm und Betriebssystem
- definiert durch: API-Spezifikation des Betriebssystems
- implementiert durch: zwischengeschaltete Bibliothek
- (z.B. libc; Stellvertreter-Prozeduren, Urform heutiger Middleware-Stubs)
- Problem: Separate Namensräume
- „do_sys_write“ liegt nicht im Namensraum des Anwendungsprozesses
- Lösung: Einigung auf Namenskonventionen („push(write_C)“)
- Problem: Separate Adressräume/Adressraumbereiche
- kein direkter Zugriff auf Parameter seitens der aufgerufenen Prozedur
- Lösung:
- Parameter-Datenstruktur auf User-Stack
- performante Alternative: in Registern
- Problem: Privilegienwechsel User→Kernel→User
- TRAP/RTT-Mechanismus (ReTurn from Trap)
Kosten: Systemaufruf = Prozeduraufruf+X X=
- Standardisierung der Parameterübergabe
- Kosten gering bei Übergabe in Registern ( reguläre Prozedur)
- Isolation
- Privilegienwechsel durch Interrupt ( TRAP/RTT )
- je 100 Taktzyklen (Kontextsicherung)
- Verlust der Sprungziel-Vorausberechnungen
- Verlust spekulativer Ausführungen
- sehr teuer
- Optimierung (seit Pentium 2): SysEnter/SysCall-Instruktionen
- Kosten gegenüber regulärem Prozeduraufruf: heute ca. Faktor 2
Ereignismanagement
Das Problem: Betriebssystemen laufen sehr viele Aktivitäten parallel ab
- Ausführung von Anwendungsprogrammen
- Management von Prozessor-, Speicher-, Kommunikations-Ressourcen
- Bedienung der E/A-Peripherie dabei: entstehen immer wieder Situationen, in denen auf unterschiedlichste Ereignisse reagiert werden muss, z.B.
-
Timerablauf
-
Benutzereingaben (Maus, Tastatur)
-
Eintreffen von Daten von Netzwerken, Festplatten, ...
-
Einlegen/stecken von Datenträgern
-
Aufruf von Systemdiensten
-
Fehlersituationen
-
Qualitativ
- Windows-System (Laptop), gestartete GUI
- Jederzeit: können ca. 400 verschiedene Ereignisse eintreten
-
Quantitativ
- MacOS MacBook Pro
- allein Systemaufruf-Ereignisse („SysEnter“) > 1.000.000/sek
-
\rightarrowUmgangsformen mit Ereignissen
Umgangsformen mit Ereignissen
- „busy waiting“
- spezialisierte Threads innerhalb des BS prüfen andauernd Ereigniseintritt
- sehr kurze Reaktionszeit
- ineffiziente Prozessornutzung
- hoher Energieverbrauch
- akzeptabel bei
- bekannt kurzen Wartezeiten
- Multiprozessormaschinen, falls
- ausreichend Prozessoren vorhanden sind
- ausreichend Energie vorhanden ist
- „periodic testing“
- spezialisierte Threads prüfen hin und wieder den Ereigniseintritt
- je nach Prüfperiode
- lang: fragliche Reaktionszeit
- kurz: fragliche Effizienz der Prozessornutzung
- akzeptabel bei: relaxten Reaktionszeitanforderungen
- Unterbrechungen („Interrupts“)
- Benachrichtigung über Ereignis
- Zur Wirksamkeit dieser Technik
- Verhältnis Anzahl Festplattenoperationen zu CPU-Operationen
- Laptop: ca. 1:10.000.000
Ereignisklassen
- E/A-Gerätemeldung („ich habe fertig“, „ich habe Fehler“)
- Timer-Ablauf
- Ausfall der Hardware (Stromausfall, Speicher-Paritätsfehler)
- Fehlverhalten ablaufender Programme , z.B.
- Ausführung privilegierter oder illegaler Instruktionen
- Zugriff auf geschützte Speicheradressen
- arithmetischer Überlauf (z.B. „
2^{40}* 2^{40}“ bei 64-Bit-Arithmetik) - Division durch 0
- Seitenfehler (bei virtueller Speicherverwaltung, s.u.)
- explizit per Programm ausgelöste Ereignisse („TRAP“)
Ereignisquellen
- Hardware: E/A-Geräte, Uhren, CPU, MMU, ALU, FPU
- Software: Instruktionen wie TRAP, SysCall Technisch: Signalisierung z.B. durch „5 Volt an Prozessorbeinchen“ Programmiermodell: HW/SW-Schnittstelle?
Programmiermodelle zur Unterbrechungsbehandlung
- Idee
- Verknüpfung von (HW-)Interrupts mit (SW-)Abstraktionen;
- Prozeduren (→ inline Prozeduraufrufmodell)
- IPC-Operationen (→ IPC-Modell)
- Threads (→ pop-up Thread Modell)
- Wirkung
- Interrupt ↷ Ausführung der assoziierten Abstraktion, z.B.
- Interrupt Nr. 42: ↷ rufe Prozedur „InterruptHandler_42()“ auf
- Interrupt Nr. 42: ↷ sende Botschaft „Interrupt 42“ an einen Thread
- Interrupt Nr. 42: ↷ erzeuge Thread „Interrupt_42_Thread“
Das inline-Prozeduraufrufmodell
- Interruptbehandlungen: besitzen syntaktisches Aussehen einer Prozedur:
- „Handlerprozeduren“ (interrupt service routines (ISRs))
- Ablauf der Interruptbehandlung: erzwungener Prozeduraufruf
- kein Threadwechsel, sondern
- Unterbrechung des Tuns des momentan ablaufenden Threads
- Sicherung seines Ablaufkontexts (Lesezeichen: IP, SP, PSR, ...)
- Versetzen des Threads in Ablaufkontext der Unterbrechungsbehandlung (z.B. andere Privilegierungsebene)
- Ausführung der Handlerprozedur (untergeschobener (inline-) Prozeduraufruf)
- Restauration des Threads in den unterbrochenen Ablaufkontext (beim Lesezeichen)
- Planung der Interruptbehandlung:
- Prozedurname mit Interruptquelle assoziieren
- Interruptvektortabelle
- es gibt: viele unterschiedliche Interruptquellen
- es gibt: entsprechend viele unterschiedliche Reaktionen auf Interrupts
- Aufruf der zugehörigen Handlerprozedur:
- wir haben: ein konkretes Interruptsignal: „5 Volt“ und eine Nummer
\rightarrowHardwareebene - wir möchten: die Ausführung der zugehörigen Handlerprozedur im Betriebssystem, z.B. im Timer-Management
\rightarrowSoftwareebene
- wir haben: ein konkretes Interruptsignal: „5 Volt“ und eine Nummer
Problem also: geeignete Hardware/Softwareschnittstelle
Lösung: Die Interruptvektor-Tabelle (IVT): Assoziationen („Interruptvektoren“) der Form
- Interruptquelle → Handlerprozedur (ISR)
- Interruptquelle: Nummer
- Handlerprozedur: Code oder Codeadresse
- Speicherort: BS und Interrupthardware bekannt; Varianten:
- fester Ort: z.B. im Arbeitsspeicher, beginnend bei Adresse 0
- variabel: lokalisiert über Adressregister (Interruptvektor Adressregister, IVA)
- Format: (HW-)architekturspezifisch, dem Betriebssystem bekannt
- erstellt:
- in früher Boot-Phase des Systems
- als Ergebnis einer Analyse möglicher Interrupt-Quellen (z.B. vorhandene E/A-Geräte) (BIOS, UEFI)
Fazit des inline-Prozeduraufrufmodells
- Unterbrechungsbehandlung: durch Interrupt Service Routinen
- Planung: in Interruptvektor-Tabelle
- Ablauf: erzwungener Prozeduraufruf
- Sicherung des Ablaufkontexts des momentan aktiven Threads
- Auswahl der Handlerprozedur gemäß IVT-Eintrag
- Ausführung der Handlerprozedur durch untergeschobenen Prozeduraufruf
- Restaurierung des unterbrochenen Tuns des Threads
IPC Modell
2-stufig
- Stufe der Interruptbehandlung: erzeugt IPC-Operation
- Stufe der Interruptbehandlung: Reaktion auf diese IPC-Operation
- Interrupts: abgebildet auf reguläre IPC-Operationen
- Interruptbehandlungen: sind reguläre Reaktionen der IPC-Adressaten
- zeitliche Kalkulierbarkeit und Kürze der primären Interruptbehandlung (Echtzeitsysteme!)
Planung
- IPC-Erzeugung mit Interruptquelle verknüpfen → Interruptvektor
- Beim Interrupt
- Stufe:
- I. Unterbrechung des momentan aktiven Threads
- II. Erzeugen der IPC-Operation, z.B. Senden einer Botschaft (klein – passt in IVT, sehr schnell)
- III. Fortsetzung des unterbrochenen Threads
- Stufe: IPC-Adressat, z.B. Thread eines Gerätemanagers, reagiert auf IPC
- Stufe:
pop-up-Thread-Modell
2-stufig
- Stufe der Interruptbehandlung: erzeugt Thread
- Stufe der Interruptbehandlung: erfolgt in diesem Thread
- Interruptsignale: abgebildet auf Thread-Erzeugungen
- Interruptbehandlungen: sind reguläre Thread-Abläufe
- zeitliche Kalkulierbarkeit und Kürze der primären Interruptbehandlung (Echtzeitsysteme!)
Planung
- Thread-Erzeugung mit Interruptquelle verknüpfen → Interruptvektor
- Beim Interrupt
- Stufe:
- I. Unterbrechung des momentan aktiven Threads
- II. Erzeugen des Threads (klein – passt in IVT, sehr schnell)
- III. Fortsetzung des unterbrochenen Threads
- Stufe:
- Thread (z.B. in Gerätemanager) wird (irgendwann) vom Scheduler aktiviert
- Stufe:
Implementierungstechniken
Ablauf
- Ereignis entsteht: z.B. auf E/A-Geräteplatine, in MMU, in SW ...
- Interruptsignal wird (evtl. über Kommunikationsbus) Prozessor zugestellt
- Prozessor schließt Ausführung der laufenden Instruktion ab (falls möglich)
- Prozessor sichert Ablaufkontext des aktiven Threads
- Prozessor stellt Ablaufkontext der Interruptbehandlung her
- dazu benötigt er minimal: Adresse der Interrupt-Behandlungsroutine
- dies: setzt vorherige Einplanung in der IVT voraus
- Fortsetzung des aktiven Threads im neuen Kontext der Interrupt-Behandlung; dabei u.U. Wechsel der Privilegierungsebene
- der neue Kontext
- führt Code in der IVT aus
- dies ist je nach Interrupt-Programmiermodell: Aufruf einer Prozedur, Erzeugung einer IPC-Operation, Erzeugung eines Threads
- bei Abschluss (RTI):
- Rückversetzen des aktiven Threads in den gesicherten Ablaufkontext; dabei u.U. Rückkehr zur vorherigen Privilegierungsebene
Was bleibt der Software?
- Definition der Interrupt-Behandlungsalgorithmen (in Form von Prozeduren, IPC-Reaktionen, Threads; oft Teil des BS-E/A-Systems)
- Vorausplanung der Interrupt-Behandlungen in der IVT
- Bootphase
- Nachladen von Gerätemanagern
Die Realität ist häufig komplexer
- Interruptquellen besitzen unterschiedliche Wichtigkeit
- Priorisierung (Eignung der 3 Modelle?)
- Echtzeiteigenschaften (zeitlich garantierte Reaktion auf Ereignisse)
- Unterbrechbarkeit der Interruptbehandlung durch höherpriore Interrupts
- geschachtelte Interruptbehandlung (Eignung der 3 Modelle?)
- moderne Prozessorarchitekturen (superskalare (intern parallele)
- Prozessoren) arbeiten mit spekulativer und paralleler Instruktionsausführung
- viele Instruktionen befinden sich zum Unterbrechungszeitpunkt in unterschiedlichen Bearbeitungszuständen
- Sicherung/Wiederaufsetzung des unterbrochenen Ablaufkontexts (HW) komplex und zeitaufwändig
Fazit soweit
- 100e von Ereignissen jede Sekunde
- erfordert: effizientes und ökonomisches Ereignismanagement
- die Hardware hilft
- Schnittstelle: IVT
- Unterbrechungsmanagement
- Software: 3 alternative Programmiermodelle
- eine Prozedur wird aufgerufen
- eine Botschaft wird gesendet
- ein Thread wird erzeugt
- Wahl abhängig von
- Echtzeiteigenschaften
- Performanzanforderungen
Asynchrone Signalisierungsmechanismen außerhalb von Betriebssystemen
- Meldung von Ereignissen (terminierte Kindprozesse, Ausführung illegaler Instruktionen, Speicherschutzverletzungen ...)
- Stoppen, Fortsetzen, Abbruch von Prozessen
Umgang damit
- Definition von ESRs (event service routines) in Anwendungssystemen; deren syntaktische Form z.B. in C: Prozeduren (inline-Modell)
- Planung der Ereignisreaktion
- Reaktionstyp festlegen
- a) ignorieren
- b) Prozessabbruch
- c) ESR-Aufruf
- im letzteren Fall: Verknüpfen einer ESR mit einem Ereignis per Systemaufruf (z.B. in Unix: signal( , ) )
- Betriebssystem: merkt sich Anbindung im Prozessdeskriptor (Ereignismanagement, „Handler-Vektor“; = Interruptvektortabelle) PD
- bei Ereigniseintritt: untergeschobener Prozeduraufruf (durch Modifikation des IP*-Registers (Anfang der ESR-Prozedur))
- nach Prozedurende: Fortsetzen an unterbrochener Stelle
- Reaktionstyp festlegen
Auslösung von Ereignissen durch
- Hardware (z.B. Speicherzugriffsfehler, arithmetischer Fehler)
- Betriebssystem (z.B. Prozessmanagement: Terminierung von Kindprozessen)
- andere Benutzerprozesse (API-Aufruf) (z.B. in Unix: kill( , ) )
bei Auftreten des Ereignisses; erfolgt gemäß obiger Planung
- a) ignorieren
- b) Prozessabbruch
- c) ESR-Aufruf
- inline-Prozeduraufruf der ESR-Prozedur
- Rückkehr zum unterbrochen Kontext nach dessen Ende
Zusammenfassung Ereignismanagement/Botschaften
- Ereignismanagement erlaubt:
- schnelle
- effiziente
- hardwareunterstützte
- Reaktionen auf synchrone und asynchrone Ereignisse
- Programmiermodelle: Abbildung von Ereignissen auf
- erzwungene Prozeduraufrufe
- IPC-Operationen
- Threaderzeugung
- Planung: durch Definition der ISR und Eintrag in IVT
- analoges Konzept auf Anwendungsebene , z.B.
- Unix-Signale
- Apple Events
Zusammenfassung
IPC: Kommunikation und Synchronisation
- Semaphore und Hoare‘sche Monitore: blockierend, pessimistisch
- transaktionaler Speicher: neu, optimistisch, transaktional
- Botschaften: kein gemeinsamer Speicher, Datentransport
- Fernaufrufe, Systemaufrufe: „Spezialisierungen“
- Ereignismanagement: Interrupts, Unterbrechungen auf Anwendungsebene
Speichermanagement
Ideale Speichermedien sind
- beliebig schnell und
- beliebig groß und
- beliebig billig und
- persistent (speichern Daten ohne andauernde Energiezufuhr)
Reale Speichermedien sind
- schnell, teuer, flüchtig oder
- langsam, preiswert, persistent oder
- eine Vielzahl von Schattierungen dazwischen
Fazit: Speicherhierarchie
- Speichermanagement: Management dieser Speicherhierarchie
Speichertechnologien und -klassen
- Prozessorregister, Cache-Speicher
- sehr schnell (Pikosek., 10 11 -10 12 Zugriffe/s)
- sehr teuer → klein (≈ KByte-MByte)
- flüchtig
- Arbeitsspeicher
- schnell (Nanosekunden, ≈ 10 10 Zugriffe/s)
- weniger teuer → mittelgroß (≈ GByte)
- flüchtig
- Flash-EEPROM (SSDs, USB-Sticks)
- langsam (Mikrosekunden, 10 8 Zugriffe/s)
- preiswert → groß (≈ GByte-TByte)
- persistent
- Magnetplatten, optische Medien, Archivierungsbänder
- langsam (Mikro-/Millisekunden, 10 6 -10 8 Zgr./s)
- mittel bis sehr groß (≈ GByte-PByte)
- persistent
Was muss Arbeitsspeicher können?
- Prozesse: Programmcode, statische Daten, dynamische Daten, Stack
- Struktur
- Typisierung
- große Prozesse -> Größe
- parallele, potentiell fehlerhafte/unfreundliche Prozesse -> Isolation
Layout des (physischen) Arbeitsspeichers: 50er Jahre
Merkmale:
- extrem einfaches Speichermanagement (fester Adressbereich für Anwendungsprogramm)
- keine Hardware-Unterstützung
- Betriebssystem: Bibliothek
- Problem: zu jedem Zeitpunkt nur ein Programm
Layout des physischen Arbeitsspeichers: 60er Jahre
Merkmale:
- einfaches Speichermanagement (Freiliste, first-fit oder best-fit-Vergabe)
- parallele Prozesse
Bezahlt mit
- Verletzbarkeit: Zugriff auf Speicherbereiche fremder Prozesse
- Enge: weniger Raum für einzelne Prozesse
- Komplexität:
- Wachsen von Prozessen problematisch
- keine feste Startadresse; Erzeugung von
- Codeadressen (Sprünge, Prozeduraufrufe)
- Datenadressen (Variablen
-> Relokation
Relokation
Ziele
- Platzieren eines Prozesses an beliebigen Speicheradressen
- Verschieben zwecks Vergrößerung/Speicherbereinigung
Idee
- sämtliche Speicheradressen in einem Programm werden
- vom Compiler/Linker relativ zur Speicheradresse „0“ berechnet
- als „Relativadressen“ markiert
- beim Anlegen/Verschieben eines Prozesses werden markierte Adressen aktualisiert (= Relokation):
tatsächliche Adresse = Relativadresse + Prozessanfangsadresse
Realisierung
- per Software → durch Betriebssystem beim Erzeugen/Verschieben
- per Hardware → durch Offset-Register zur Laufzeit: „my first MMU“
Erreicht
- Anlegen eines Prozesses an beliebiger Adresse
- Verschiebbarkeit ( gegen Enge und Verletzbarkeit hilft Relokation nicht)
Bezahlt mit
- entweder: verteuertem Programmstart (wenn Startadresse bekannt):
- Aktualisierung der Relativadressen per Software (Betriebssystem-Prozessmanagement)
- oder: höheren Hardware- und Laufzeitkosten:
- mini-MMU mit Offset-Register
- Adressumrechnung bei jedem Speicherzugriff
Swapping
Ziel: Beseitigung der Enge
- Schaffen von freiem Arbeitsspeicher durch Auslagerung von Prozessen
- Erstes Auftauchen einer Speicherhierarchie
Erreicht: mehr Platz (gegen Verletzbarkeit hilft Relokation nicht)
Bezahlt mit:
- Prozesswechsel werden teurer
- Aus/Einlagerungszeiten
- Relokation bei Wiedereinlagerung an neue Adresse
- fortschreitende Zerstückelung des Arbeitsspeichers
- Verluste durch Verschnitt
- der pro Prozess adressierbare Speicherbereich wird durch Swapping nicht größer (limitiert durch physische Arbeitsspeichergröße)
- virtueller Speicher
Virtueller Speicher
Idee: Jeder Prozess erhält einen privaten, sehr großen Arbeitsspeicher
Damit
- besitzt jeder Prozess einen riesigen Vorrat an Speicheradressen
- bei
2^{Adressenlänge}= Anzahl Speicheradressen gilt: sämtliche von einem Prozess erzeugbaren Speicheradressen (sein Adressraum)- gehören per Definition: zu seinem eigenen Arbeitsspeicher
- dadurch: keine Möglichkeit des Zugriffs auf Arbeitsspeicher anderer Prozesse
- ist keine Relokation mehr notwendig
Problem: so viel Speicher können wir physisch gar nicht bauen (es gibt nicht einmal 2^64 Atome im Sonnensystem!!)
Lösung:
- Betriebssysteme lügen (vermitteln Prozessen eine Illusion)
- virtuelle Adressräume
Virtuelles Speichermanagement (VMM)
ist die Realisierung dieser Idee durch
- Abstraktionen physischen Arbeitsspeichers:
- private virtuelle Adressräume
- Abbildungen
vm_p:- virtueller Adressraum → physischer Adressraum
- MMUs:
- Hardware, die diese Abbildungen effizient implementiert
Ausgangsidee: Jeder Prozess p besitzt einen privaten, großen virtuellen Adressraum VA_p (z.B. 2 64 adressierbare Speicherzellen).
Damit
- ist es nicht mehr eng
- können Prozesse sich gegenseitig nicht mehr verletzen
Begriffe
Adressraum: Ein Adressraum ist eine (endliche) Menge von Adressen
- Menge aller Postadressen einer Stadt
- Menge aller IP-Adressen
- die natürlichen Zahlen 0 ... 2 64 -1
Adressraum eines Prozesses: Der Adressraum eines Prozesses (im Kontext des VMMs) ist die Menge aller ihm zur Verfügung stehender Arbeitsspeicheradressen
physischer Adressraum: Ein physischer Adressraum (PA) ist die Menge aller Adressen eines physischen (realen) Speichers
virtueller Adressraum: Ein virtueller Adressraum (VA) ist die Menge aller Adressen eines virtuellen Speichers; im Allgemeinen gilt: |VA|>>|PA|
virtueller Speicher: ist eine Abstraktion physischen Speichers zwecks Vortäuschung großer physischer Adressräume
virtuelles Speichermanagement (besser: Management virtueller Speicher): befasst sich mit der Abbildung virtueller auf physische Adressräume
Abbildung vm_p
Realisierung: Jeder virtuelle Adressraum VA_p wird mittels einer individuellen Abbildung vm_p: VA_p \rightarrow PA auf den physischen Adressraum PA abgebildet (siehe: „Speicherlayout“).
Eigenschaften der Abbildung vm_p
- Definitionsbereich
VA_psehr groß\existsunbenutzte/undefinierte Adressbereichevm_ppartiell
- Realisierung
|VA_p | >> |PA|- Abwesenheit (Seitenfehler, s.u.)
vm_pnicht zu jedem Zeitpunkt vollständig gültig
- Isolation
- Adressen verschiedener virtueller Adressräume werden nie zum selben Zeitpunkt auf dieselbe Adresse des physischen Adressraums abgebildet
Aufgaben des virtuellen Memory Management (VMM): Realisierung der Abbildung vm_{pi}: VA_{pi} \rightarrow PA einschließlich
- Definitionsbereich: $vm_{pi} partiell
- Anwesenheitskontrolle: $vm_{pi} nicht immer gültig
- Isolation und Kommunikation: Injektivität
- Zugriffsschutz: lesen/schreiben/ausführen
... bei jedem einzelnen Speicherzugriff!
Effizienz
- massive Unterstützung durch Hardware (MMU)
- Mengenreduktion: sowohl
VA_{pi}\rightarrow PAals auch die Definition von Zugriffsrechten- erfolgen nicht für jede virtuelle Adresse individuell
- sondern in größeren Einheiten („Seiten“); typische Größe 4 oder 8 KByte
Memory Management Units (MMUs)
Integration in die Hardware-Architektur im Zugriffspfad: Prozessor (virtuelle Adressen) → Speicher (physische Adressen)
Abbildung vm_p: VA_p\rightarrow PA in der MMU
- Aufteilung jedes virtuellen Prozessadressraums in Seiten gleicher Größe (typisch 4 oder 8 KByte)
- Aufteilung des physischen Adressraums in Seitenrahmen gleicher Größe
- Seite eines virtuellen Prozessadressraums mit Seitenrahmen des physischen Adressraums assoziieren („Fliesen legen“): die Seiten(abbildungs)tabelle
\rightarrow Realisierung der Abbildung vm_p: VA_p\rightarrow PA seitenweise
Seitenabbildungstabellen
Beispiel (mit kleinen Zahlen)
- Seitengröße: 2 KByte
- Größe des VA: 2^14 =16 KByte (→ 8 Seiten, virtuelle Adressen haben 14 Bit)
- Größe des PA: 2^13 =8 KByte (→ 4 Seitenrahmen, phys. Adressen haben 13 Bit )
Prinzipieller Aufbau eines Seitentabelleneintrags (davon gibt es genau einen je Seite eines virtuellen Adressraums):
| Rahmennummer im Arbeitsspeicher (PA) | anwesend | benutzt | verändert | Schutz | Caching |
Seitenattribute
- anwesend: Indikator, ob Seite im Arbeitsspeicher liegt („present“-Bit)
- benutzt: Indikator, ob auf die Seite zugegriffen wurde („used/referenced“- Bit )
- verändert: Indikator, ob Seite „schmutzig“ ist („dirty/ modified “-Bit)
- Schutz: erlaubte Zugriffsart je Privilegierungsebene („access control list“)
- Caching: Indikator, ob Inhalt der Seite ge“cached“ werden darf
Von MMU und BS gemeinsam genutzte Datenstruktur: HW/SW Schnittstelle
- von MMU bei jedem Speicherzugriff genutzt zur
- Prüfung auf Präsenz der die Zugriffsadresse enthaltenden Seite
- Prüfung der Rechte des Zugreifers (Privilegierungsebene und Zugriffsart vs. Schutz)
- Umrechnung der virtuellen in die physische Adresse
- vom BS verändert
- bei jedem Adressraumwechsel (Prozesswechsel; Grundlage: Adressraum-Beschreibung im Prozessdeskriptor)
- beim Einlagern/Auslagern einer Seite (present-Bit, phys. (Seitenrahmen-)Adresse)
- bei Rechteänderungen
- von der MMU verändert: zur Lieferung statistischer Informationen
- bei einem Zugriff auf eine Seite (used-Bit)
- bei einem Schreibzugriff auf eine Seite (dirty-Bit)
- vom BS genutzt: zum effizienten Speichermanagement
- z.B. zum Finden selten genutzter Seiten bei Arbeitsspeicher-Engpässen (used-Bit)
- z.B. müssen nur veränderte Seiten bei Freigabe zurückgeschrieben werden (dirty-Bit)
Problem: VMM „is not for free“
- Speicher: Seitentabellen können sehr sehr groß werden
- Performanz: je Speicherzugriff (mehrere) Zugriff(e) auf Seitentabelle
- algorithmische Komplexität: Auftreten von Seitenfehlern (Zugriff auf abwesende Seiten) bei vollständig belegtem physischen Arbeitsspeicher:
- Untersuchung: Welche Seite soll verdrängt werden?
- Ausführen: Seitenaustauschalgorithmen
- viele Prozesse können gleichzeitig aktiv sein: jederzeit kann ein Seitenfehler („Page Fault“) auftreten
Lösungen
- mehrstufige Seitentabellen: basieren auf Beobachtung, dass Adressräume häufig nur dünn besetzt sind
- alternative Datenstrukturen
- gesehen: mehrstufige, baumstrukturierte Seitentabellen
- grundsätzlich beliebige Baumtiefe
- können selbst dem Paging unterliegen (belegen dann zwar Adressraum, jedoch physischen Speicher nur dann, wenn sie tatsächlich gebraucht werden)
- Nachteil: Performanz; mehrere Tabellenzugriffe zur Umrechnung einer virtuellen Adresse erforderlich, evtl. dabei erneut Seitenfehler
- invertierte Seitentabellen (1 Eintrag je physischer Seite)
- Nachteil: virtuelle Adresse kann nicht mehr als Index zum Finden des Tabelleneintrags verwendet werden → aufwendige Suchoperationen
- gehashte Seitentabellen
- guarded page tables
- gesehen: mehrstufige, baumstrukturierte Seitentabellen
- Seitentabelle in schnellem Register-Array (innerhalb der MMU)
- schnell (keine Speicherzugriffe für Adressumrechnung)
- teuer in der Realisierung (Hardware-Kosten)
- teuer bei Prozess-(Adressraum-)Wechsel (Umladen)
- sinnvoll daher nur für relativ kleine Tabellen
- Seitentabellen im Arbeitsspeicher, Ort in Adressregister
- schnelle Prozesswechsel (keine Rekonfigurierung der MMU, lediglich Aktualisieren des Adressregisters)
- skaliert für große Seitentabellen
- hohe Adressumrechnungskosten (Zugriff(e) auf Arbeitsspeicher)
- Seitentabellen im Arbeitsspeicher, Ort in Adressregister, plus Caching von Seitentabelleneinträgen
- „TLBs“ (Translation Look-aside Buffer)
- Aufbewahren benutzter Tabelleneinträge
- basiert auf Lokalität von Speicherzugriffen
- reduziert Adressumrechnungskosten speichergehaltener Seitentabellen
Translation Look-aside Buffer (TLB)
- schneller Cache-Speicher für Seitentabelleneinträge
- lokalisiert in der MMU
- Aufbau eines Cacheeintrags identisch dem eines Seitentabelleneintrags
- Cache-Management:
- Invalidierung bei Adressraumwechsel erforderlich!
- Sekundärkosten eines Adressraumwechsels durch „kalten“ TLB
- cache-refill bei TLB-miss aus Seitentabelle
- durch MMU-Hardware („Page Table Walker“, automatisch)
- durch Betriebssystem (nach Aufforderung durch MMU (Interrupt))
- Invalidierung bei Adressraumwechsel erforderlich!
Ablauf einer Seitenfehlerbehandlung
- Erkennung durch MMU (present-Bit in Seitentabelleneintrag)
- Anfertigungung einer Seitenfehlerbeschreibung
- Auslösung eines Seitenfehler-Interrupts; hierdurch:
- a) Unterbrechung der auslösenden Instruktion (mittendrin!)
- b) Aufruf der Seitenfehlerbehandlung (ISR des VMM); dort:
- Suche eines freien Seitenrahmens
- evtl. explizit freimachen (auslagern);
- Auswahl: strategische Entscheidung durch Seitenaustauschalgorithmus
- Einlagern der fehlenden Seite vom Hintergrundspeicher
- z.B. von lokaler Festplatte
- z.B. über LAN von Server
- Aktualisierung des Seitentabelleneintrags (physische Adresse, present-Bit)
- Suche eines freien Seitenrahmens
- Fortsetzung des unterbrochenen Prozesses
Seitenaustausch-Algorithmen
Problem: Seitenfehler bei vollständig belegtem physischen Arbeitsspeicher
Strategie: Welche Seite wird verdrängt?
Optimale Strategie: Auslagerung derjenigen Arbeitsspeicherseite, deren ...
- nächster Gebrauch am weitesten in der Zukunft liegt (dazu müsste man Hellseher sein)
- Auslagerung nichts kostet, dazu müsste man wissen, ob eine Seite seit ihrer Einlagerung verändert wurde
im Folgenden: einige Algorithmen, die sich diesem Optimum annähern
- First-In, First-Out (FIFO)
- Second-Chance
- Least Recently Used (LRU)
- Working Set / WSClock
First-In , First-Out (FIFO)
- Annahme: Je länger eine Seite eingelagert ist, desto weniger wahrscheinlich ist ihre zukünftige Nutzung
- Strategie: Auslagerung der ältesten Seite
- Realisierung
- Einlagerungsreihenfolge merken, z.B. durch FIFO-organisierte Seitenliste
- Auslagerung derjenigen Seite, die am „out“-Ende der Liste steht
- Wertung
- einfacher Algorithmus
- effizient implementierbar (Komplexität: Listenoperationen in O(1))
- Beobachtung: soeben ausgelagerte Seiten werden oft wieder benötigt
- Annahme stimmt oft nicht (entfernt z.B. alte, aber oft benutzte Seiten)
Second Chance (Variante des FIFO-Algorithmus)
- Annahme
-statt: Je länger eine Seite eingelagert ist, desto weniger wahrscheinlich ist ihre zukünftige Nutzung
- nun: Je länger eine Seite nicht mehr benutzt wurde, desto weniger wahrscheinlich ist ihre zukünftige Nutzung
- Strategie
- Eine FIFO-gealterte Seite bekommt eine 2. Chance, falls die Seite während des Alterns benutzt wurde (used-Bit der MMU)
- Verjüngungskur:
- Umsortieren der Seite ans junge Ende der FIFO-Liste,
- Löschen des used-Bits
- Wertung
- einfacher Algorithmus
- effizient implementierbar
- used-Bit der MMU
- Listenoperationen in O(1)
- bessere Ergebnisse im Vergleich zu FIFO → die „Kur“ wirkt
- zutreffendere Seitenmerkmale berücksichtigt: Zeitpunkt der letzten Nutzung
- aber immer noch sehr grobgranular: 16 GByte physischer Adressraum u. 4 KByte Seitengröße: ~4.000.000 Seiten im physischen Adressraum -> Prüfintervall ~ 4.000.000 Seitenfehler
Least Recently Used (LRU)
- Annahme: Je länger eine Seite nicht mehr benutzt wurde, desto weniger wahrscheinlich ist ihre zukünftige Nutzung (also dieselbe wie 2 nd Chance)
- Strategie: Feinere Granularität: genauere Nutzungszeitpunkte je Seite
- Notwendiges Wissen: ist teuer
- Speicher: Nutzungszeitpunkte für jede Seite des Prozess-Adressraums (einige Millionen)
- Laufzeit: Aktualisierung bei jedem Speicherzugriff (einige Milliarden/Sekunde)
- Griff in die Trickkiste
- Hardware-Unterstützung speziell für diesen Algorithmus (MMU)
- eine logische Uhr
- tickt bei jeder ausgeführten Prozessorinstruktion
- wird bei jedem Arbeitsspeicherzugriff in den Seitentabelleneintrag der betroffenen Seite eingetragen
- die am längsten nicht mehr benutzte Seite hat dann den ältesten Uhrenstand
- eine logische Uhr
- Software-Realisierungen: Annäherung des Hardware-Tickers
- Hardware-Unterstützung speziell für diesen Algorithmus (MMU)
Variante 1
- jeder Seitentabelleneintrag erhält Zählerfeld
- periodisch (nicht bei jedem Zugriff, wäre zu teuer) wird für residente Seiten
- used-Bit zu diesem Zähler addiert
- used-Bit anschließend gelöscht
- Ergebnis
- recht effizient implementierbar
- Zählerwert: nur Annäherung der Nutzungshäufigkeit
- daher: suboptimale Ergebnisse
Variante 2
- jeder Seitentabelleneintrag erhält Zählerfeld (wie eben)
- periodisch wird
- der Zähler aber gealtert: nach rechts verschoben (= Division durch 2)
- das used-Bit jetzt in das höchstwertige Bit des Zählers geschrieben
- das used-Bit anschließend gelöscht
- Ergebnis
- recht effizient implementierbar
- Zähler: enthält jetzt einen Alterungsfaktor
- Annäherung an Zeitpunkt der letzten Nutzung
- bessere Annäherung an LRU-Grundannahme
- bessere Ergebnisse
Working Set
- Annahmen
- Arbeitsspeicher-Zugriffsmuster von Prozessen besitzen „hot spots“: Bereiche, innerhalb derer fast sämtliche Zugriffe stattfinden
- hot spots: bewegen sich während des Prozessablaufs relativ langsam durch den virtuellen Adressraum
- die zu den hot spots eines Prozesses gehörenden Seiten nennt man seine Arbeitsmenge (Working Set)
- Idee
- Zugriffe auf Seiten der Arbeitsmenge: sind erheblich wahrscheinlicher als auf nicht zur Arbeitsmenge gehörende Seiten
- Auslagerungskandidaten: sind Seiten, die zu keiner der Arbeitsmengen irgendeines Prozesses gehören
Bestimmung der Arbeitsmenge eines Prozesses
- Wann gehört eine Seite dazu? Beobachtung der Speicherzugriffe
- Wann tut sie es nicht mehr? Beobachtungs-Zeitfenster der Größe
Definition: Die Arbeitsmenge
W_p (t, \tau)eines Prozesses p zum Zeitpunkt t ist die Menge der virtuellen Seiten, die p innerhalb des Intervalls[t-\tau , t]benutzt hat.
Quantifizierung von \tau:
- asymptotisches Verhalten
- für
\tauexistieren sinnvolle Schranken
Beobachtung von Arbeitsspeicherzugriffen: ist teuer
- Speicher: Zeitpunkt der letzten Nutzung für jede Seite eines VA (Linux: Billionen/VA)
- Zeit: Aktualisierung bei jedem Speicherzugriff (Milliarden/Sekunde)
- also auch hier gesucht: gute Annäherung (vgl. LRU)
Schema der Implementierung
-
wir brauchen
- used-Bit der MMU
- virtuelle Laufzeit der Prozesse
-
das VMM
- stempelt benutzte Seiten (used-Bit) periodisch mit virtueller Laufzeit des Eigentümers (prozessindividuell)
- löscht deren used-Bits
-
Wir kennen damit (ungefähr) die Zeitpunkte der letzten Nutzung aller Seiten aller Prozesse (ausgedrückt in virtueller Prozesslaufzeit).
-
Wir können damit ausrechnen: Die Arbeitsmengen aller Prozesse
-
Wir nutzen diese nun zur Bestimmung von Auslagerungskandidaten
-
Wann? → Genau dann wenn
- ein Seitenfehler auftritt und
- kein Seitenrahmen (im Arbeitsspeicher) frei ist
-
Wie?
- Bestimmung der Arbeitsmenge
W_peines Prozesses p zum Zeitpunkt t mitz_sals Zeitstempel einer Seites\in VA_pv_p(t)als virtueller Prozesszeit von p zum Zeitpunkt t\tauals Beobachtungsintervall gilt:s\in W_p(t,\tau)\leftrightarrow z_s\geq v_p(t)-\tau
- Bestimmung der Auslagerungskandidaten
- Seite s ist Auslagerungskandidat zum Zeitpunkt t
\leftrightarrows gehört zu keiner Arbeitsmenge, d.h. s\not\in\bigcup_{p\in P} W_p(t,\tau)\existskein Kandidat: Auswahl gemäß LRU-Regel\existsmehrere Kandidaten: Auslagerungskosten berücksichtigen (dirty-Bit)
- Seite s ist Auslagerungskandidat zum Zeitpunkt t
- Bestimmung der Arbeitsmenge
Algorithmus zur Kandidatenbestimmung:
for p in P
W_p ← null;
for s in PA
if s in VA_p OR z_s >= v_p(t)-tau then W_p ← W_p + {s};
kandSet ← PA-U + W_p ;
Bewertung:
- bei zutreffender Grundannahme (hot spots): sehr gute Ergebnisse
- Effizienz: Arbeitsmenge kann schon vor einer Prozessreaktivierung eingelagert werden („prepaging“)
- schneller Prozessanlauf
- Kosten
- periodisch:
- Löschen der used-Bits sämtlicher PA-Seiten
- Stempeln (z.B. 16GB → 2 21 Seiten, verteilt auf die Seitentabellen der Prozesse)
- je Suche eines Auslagerungskandidaten
- Bestimmung sämtlicher Working Sets:
O(|P|*|PA|) - Bestimmung der Auslagerungskandidaten:
PA- U_{p\in P} W_p
- Bestimmung sämtlicher Working Sets:
- periodisch:
2 Methoden zur Kostenreduzierung
- Trennung
- Seitentabellen der Prozesse und
- Seitentabelle zur Buchführung der Zeitstempel (nur auf Seiten im PA kann überhaupt zugegriffen werden)
- Reduzierung der Tabellenzugriffe bei Stempeln und W p –Bildung
- Nutzung von Informationen der letzten Suche (soo viel hat sich seitdem nicht geändert)
- Reduzierung der Suchoperationsanzahl
- WSClock , der heute wohl meistgebrauchte Paging-Algorithmus
WSClock
Umsetzung:
-
Zeitstempel-Datenstruktur: ringartige Liste der Seiten im physischen Adressraum („Uhren-Zifferblatt“)
-
Kandidatensuche: je Seite Zugehörigkeit zum Working Set prüfen
-
Zustandsinformationen: Ende der letzten Suche (Uhrzeiger)
-
Stopp der Suche: sobald eine Seite
s\not\in U_{p\in P} W_pgefunden wird -
Beobachtung: hot spots → individuelle Arbeitsmenge je Prozess
-
Idee: Verdrängung von nicht zu einer Arbeitsmenge gehörenden Seiten
-
Realisierung: Arbeitsmengenbildung über Zeitstempel der letzten Nutzung
effizient implementiert durch
- Zeitstempel virtueller Prozesslaufzeit in den Seitentabellen (Hardware)
- periodische Inspektion des used-Bits (vgl. LRU)
- Nutzung vorausgegangener Scan-Ergebnisse durch zifferblattartige Datenstruktur der Seiten im physischen Adressraum
Zusammenfassung
- Ziele:
- großer Arbeitsspeicher virtuelle Adressräume
- Isolation von Prozessen private Adressräume
- Methoden und Techniken
- Abbildung vm p : VA p → PA
- effizient implementiert durch MMU: Seitentabellen
- Abbildung:
vm_p: VA_p\rightarrow PA - Zugriffsüberwachung: Rechte, Anwesenheit
- Statistik: used, dirty
- Abbildung:
- Problembereiche
- sehr große Seitentabellen/Adressräume: mehrstufige (/invertierte/gehashte) Seitentabellen
- Zugriffszeit auf Seitentabelle: TLBs
|VA_p| >> |PA|: Paging, Seitenaustauschalgorithmen
Segmentierung
Das Problem: Arbeitsspeicher aus Sicht eines Prozesses -> strukturiert, typisiert
Probleme des Speichermanagements der Compiler und Linker
- Bibliotheken
- a) dynamisch gebunden: Adressen (Code, Daten) zur Übersetzungszeit unbekannt
- b) gemeinsame Nutzung: Relokation der Adressen zur Nutzungszeit nicht möglich
- Speichertypen
- vom Compiler organisierte statische Datensegmente (Programmvariablen)
- vom Compiler organisierte dynamische Datensegmente (Stacks)
- vom Prozess zur Laufzeit organisierte dynamische Datensegmente (Heaps) („new“: malloc, shared segments)
Dies alles in einem eindimensionalen, linearen Adressraum
Strukturierung des Arbeitsspeichers → Zweidimensionales Adressraum-Layout
- n Segmente (z.B.16384 bei Intel Pentium Architektur)
- je Segment eigener linearer Adressraum, z.B. Adressen 0..2 32 -1
- je Segment individuelle Schutzmöglichkeiten, z.B. rw oder x
Aufbau einer Arbeitsspeicheradresse eines Programms (erzeugt vom Compiler/Linker): 2-dimensional
Gewinn
- typisierte Segmente (Code, Daten, Stack) mit dediziertem Zugriffsschutz
- Robustheit, Sicherheit
- je Segment beginnen Adressen bei 0
- komfortabel für Compiler/Linker, gemeinsame Nutzung (Bibliotheken, IPC)
- viele Segmente
- Organisierbarkeit; Shared Libraries, DLLs
VMM- Abstraktionen in der Praxis
Wir kennen nun die Abstraktionen des VMMs zum Umgang mit physischem Speicher:
- private Adressräume
- schaffen Illusion individuellen Arbeitsspeichers je Prozess
- virtuelle Adressräume
- schaffen Illusion beliebig großen Arbeitsspeichers
- Segmente
- schaffen Abstraktion typisierten 2-dimensionalen Arbeitsspeichers
- Schutzmechanismen auf Seiten- und Segmentebene
Nutzung von Sicherheits- und Robustheitseigenschaften
- Standard: Isolation
- Anwendungsprozesse untereinander
- Anwendungs- und Systemprozesse
Zusammenfassung
- viele Prozesse
- Relokation, Swapping
- Prozess-Adressraum >> physischer Adressraum
- virtueller Speicher
- Isolation von Anwendungsprozessen
- private Adressräume
- strukturierter und typisierter 2D-Arbeitsspeicher
- Segmentierung
- differenzierter Zugriffsschutz auf Segmente und Seiten
- schützt Prozesse vor eigenen Fehlern
- schützt Betriebsystem vor Anwendungsprozessen
- effiziente Realisierungen:
- Hardware: MMUs
Adressraum-Layout beeinflusst massiv
- Sicherheitseigenschaften
- Robustheitseigenschaften
- Korrektheitseigenschaften
- Performanzeigenschaften
Architekturprinzipien
- monolithische Betriebssystem-Architekturen
- großer, monolithischer Betriebssystem-Adressraum
- aus Performanzgründen oft in private Adressräume der Anwendungsprozesse eingeblendet (s. Linux-Beispiel)
- mikrokernbasierte Architekturen
- feingranulare Adressraum-Isolation, auch zwischen Betriebssystem-Komponenten
Dateisystem
Prozesse
- verarbeiten Informationen,
- speichern diese,
- rufen diese ab,
- deren Lebenszeit >> Lebenszeit Prozesse → Persistenz
- deren Datenvolumen >> Arbeitsspeicher → Größe
- zur gemeinsamen Nutzung → individuelle Zugriffsrechte
- benötigt wird: geeignetes Paradigma
- Datei: Betriebssystem-Abstraktion zum Management persistenter Daten
- Dateisystem: „Aktenschrank“, der Dateien enthält
Dateimodelle
Aufgabe: Präzise Festlegung der Semantik der Abstraktion „Datei“
Varianten unterscheiden sich durch:
- Dateinamen; z.B.
- Typtransparenz („kap4.pptx“ vs. „kap4“)
- Ortstransparenz („C:\Users\maier“ vs. „/Users/maier“)
- Struktur (flach, hierarchisch)
- Dateiattribute; z.B.
- Sicherheitsattribute,
- Zugriffsstatistiken
- Operationen auf Dateien
- Erzeugen,
- Löschen,
- Lese/Schreiboperationen
Aufgabe: Identifikation von Dateien mittels symbolischer Namen
Namensmerkmale
- Grundmerkmale
- verwendbare Zeichen, Groß/Kleinschreibungssensitivität, Längenbeschränkungen, ...
- Typtransparenz
- Windows-Familie: explorer.exe, kap4.pdf, LadyInBlack.flac
- Unix-Familie: explorer, kap4, LadyInBlack
- Ortstransparenz
- Windows: C:\Users\maier
- Mac OS X, Linux: /Users/maier
- Namensstruktur
Hierarchischer Namensraum: Kennen wir schon; z.B.
- Postadressen: Land/Stadt/Straße/Hausnummer/Name
- große Dateianzahlen: Beherrschbarkeit
- Eindeutigkeit
- vorlesungen/bs/kap1 vs. vorlesungen/va/kap1
- Eingrenzung von Sichten (Mehrbenutzersysteme)
- /Users/schindler vs. /Users/amthor
- Darstellung: baumartige Strukturen
- „Pfadnamen“ = Pfade im Namensraum
Varianten
- unstrukturiert: lineare Bytefolgen (Linux, Windows, Mac OS X)
- satz- oder baumstrukturiert, indexsequenziell (Mainframes)
Unstrukturierte Dateien (= das Unix/Windows/-Modell)
- Datei: Bytefolge
- keinerlei inhaltliche/strukturelle Interpretation durch Betriebssystem
- elementares Model
- hohe Flexibilität
- performant realisierbar
- manchmal: auch mühevoll, z.B.
- Speicherung strukturierter Daten wie Bankkonten
- Datenstrukturen aus Programmen etc.
Strukturierte Dateien (Mainframe-Dateisysteme)
- oft genutzte Standard-Strukturen
- satzstrukturiert, baumstrukturiert, indexsequenziell
- komfortabel, anwendungsnah
- Vorstufe der DBMS-Schemata
- z.B. satzstrukturiert oder baumstrukturiert mit Schlüsseln
Datei-Attribute
Sicherheitsattribute
- Standard seit 50 Jahren: wahlfreie Zugriffssteuerung (Discretionary Access Control [DAC])
- Eigentümer, Gruppe
- Zugriffssteuerungslisten: Listen mit Benutzern und Rechten
- z.B. Unix: Eigentümer, Gruppe, Rest der Welt; jeweils rwx-Flags
- z.B. NTFS, Mac OS EFS: Listen von Paaren (Name, Rechte), (etwas) leistungsfähiger
- jüngere, leistungsfähigere Dateisysteme (SELinux, TrustedBSD, SEAndroid): obligatorische Zugriffssteuerung (Mandatory Access Control [MAC])
- Klassifikationen (z.B. „öffentlich/vertraulich/geheim“)
- Sicherheitslabel (z.B. Zugehörigkeit zu Organisationseinheit, örtliche Beschränkungen)
Weitere Attribute
- Zugriffsstatistiken; Datum
- der Erstellung
- des letzten Lesezugriffs
- des letzten Schreibzugriffs
- Nutzungszähler
Operationen auf Dateien
Benutzung von Dateien: Operationen der Betriebssystem-API
| Operationen (Systemaufrufe) | Typische Parameter |
|---|---|
| Erzeugen (create, open) | Name, Attribute -> Filedesckriptor (fd) |
| Löschen (unlink) | Name |
| Öffnen (open) | Name, Zugriffsart -> fd |
| Schließen (close) | fd |
| Inhalt lesen (read) | fd, Anzahl Bytes (,Position)-> Daten |
| Inhalt schreiben (write) | fd, Anzahl Bytes (, Position), Daten |
| Positionszeiger setzten (Iseek) | fd, Position |
| in virtuellen AR einbinden (mmap) | fd, virtuelle Adresse |
| Attribute lesen (stat) | Name -> Attribute |
| Attribute setzten (chmod/own/grp) | Name, Attribute |
(in Klammern die Namen der Unix-API)
Syntax und Semantik: BS-spezifisch, definiert in API-Spezifikation
Zusammenfassung Dateimodelle
- unterscheiden sich durch
- Namen und Namensräume (hierarchisch, Semantik)
- Dateistrukturen (un-, satz- oder baumstrukturiert)
- Attribute (Zugriffsschutz (Eigentümer, Zugriffsrechte, Klassifikationen, Zugriffsstatistiken)
- Operationen (Semantik von Erzeugen, Löschen, Lese/Schreiboperationen)
- werden implementiert: durch Dateisysteme
Dateisysteme
Problem
- schnelles
- effizientes
- robustes
- sicheres Speichern und Wiederfinden von Dateien auf persistenten Speichermedien
Dateisystem \approx Aktenschrank, bestehend aus
- Metadaten: Datenstrukturen zum Management der Nutzdaten
- Nutzdaten der Dateien
- Algorithmen, die ein Dateisystem realisieren
Verbreitete „Aktenschrank“-Typen:
- FAT (File Allocation Table): QDOS, MS-DOS (1978)
- NTFS (New Technology File System): Windows 2000/XP/Vista/7+
- HFS+ (Mac OS Extended (journaled)): Mac OS, APFS: iOS
- Ext∗ (Extended File System (∗=4: journaled)): Linux, IBM AIX
- NFS (Network File System): Sun; Unix-Systeme, Windows-Systeme, ...
- ISO 9660 für optische Speichermedien
Speichermedien
- Physisches Layout von Magnetplattenlaufwerken
- Plattengeometrie: Sektoren, Spuren; mehrere Lagen: Oberflächen
- Sektoren: elementare Zugriffseinheiten, z.B. 1024 Byte groß
- Sektor eindeutig identifiziert durch 3D-Adresse (Sektornummer, Spurnummer, Oberflächennummer)
- Zugriffszeiten (Desktop/Server Laufwerke, 2017)
- Rotationszeit = 4-8 Millisekunden (10.000 min -1 )
- Armpositionierzeit = 4-8 Millisekunden (voller Schwenk, 200-400 Armpositionierungen/Sek)
- Zugriffszeit auf Sektor
- abhängig von Lage des Sektors in Relation zur aktuellen
- Rotationsposition der Platte
- Schwenkposition des Armes
- Größenordnung bei heutigen PC-typischen Laufwerken: 6-12 Millisekunden
- kein wahlfreier Speicher !!
- Datenrate = 40-170 MByte/Sekunde
- um Größenordnungen langsamer als Arbeitsspeicher !!
SSDs vs. Magnetplatten (2017)
- wahlfreier Zugriff (c.g.s.)
- erheblich geringerer Stromverbrauch (technologieabhängig, 10%)
- erheblich geringere Zugriffszeiten, 5%
- erheblich höhere Datenraten, Faktor 3
- erheblich teurer, Faktor 5-10
Management-Datenstrukturen auf Speichermedien
- Ziele
- Speichern
- Wiederfinden von Dateien; schnell, effizient, robust, sicher
- Management-Datenstrukturen (Metadatenstrukturen)
- Datenstrukturen zur Organisation der Nutzdaten
- Informationen über das Dateisystem selbst
- Inhaltsverzeichnisse
- Informationen über individuelle Dateien
Informationen über individuelle Dateien: i-Nodes
- i-Node: Metainformationen über genau eine Datei (allg.: persistentes Objekt)
- abhängig von konkretem Dateisystem:
- enthaltene Informationen
- Layout
- Größe (≥ 128 Byte, teils >>)
- beim Lesen von Dateien
- i-Node-Index der Datei besorgen (aus Verzeichnis, s.u.)
- mit diesem Index: i-Node in der i-Node-Tabelle finden
- aus dem i-Node lesen:
- a) Schutzinformationen (Sicherheitsattribute)
- b) Adressen der Nutzdaten
- beim Erzeugen von Dateien create(“/home/anna/ProjectXBoard“,)
- Suche nach freiem i-Node in der i-Node-Tabelle
- Dateiinfos in i-Node schreiben (z.B. Struktur, Schutzinformationen)
- Name und i-Node-Index in Verzeichnis eintragen
- beim Schreiben von Daten
- Adressierungsinformationen im i-Node aktualisieren
- bei der Freigabe von Dateien
- Verzeichniseintrag löschen
- falls letzter Verzeichniseintrag dieser Datei (↑Referenzzähler):
- a) i-Node in i-Node-Tabelle als „frei“ markieren
- b) Ressourcen (belegte Sektoren) freigeben
Verzeichnisse
Aufgabe: Symbolische, hierarchische Namen ⟼ eindeutige Objekt-Id (=i-Node-Index)
- Idee
- Verzeichnis: Abbildung
- symbolischer Namensraum → Objektnamensraum
- Pfadnamenskomponente ⟼ Objekt-Id
- alle Verzeichnisse gemeinsam: Abbildung
- hierarchischer symbolischer Namensraum → Objektnamensraum
- Pfadname ⟼ Objekt-Id
- Verzeichnis: Abbildung
- in Graph-Notation
- symbolischer Namensraum: baumähnlicher Graph
- Knoten: Verzeichnisse
- Kanten: attributiert mit Namen
- Pfadname: Folge von Kantennamen
- symbolischer Namensraum: baumähnlicher Graph
- Realisierung: Verzeichnis = Menge von Paaren (Name, i-Node-Index)
Freiliste
Management-Datenstruktur für freien Speicher
- Sektoren sind
- entweder in Benutzung; enthalten dann
- a) Nutzdaten von Dateien oder Verzeichnissen
- b) Metadaten, z.B. i-Nodes
- oder frei
- alle freien Plattensektoren: Freiliste
- Organisation
- z.B. als Bitmap, je Plattensektor ein Bit (frei/belegt)
- z.B. als B-Baum (HFS)
- effiziente Suche von Mustern
- zusammenhängende Bereiche
- benachbarte Bereiche
- Bereiche bestimmter Größe
- effiziente Suche von Mustern
Superblock
Einstiegspunkt eines Dateisystems
- erzeugt: bei Erstellung eines Dateisystems („mkfs“, „formatieren“)
- steht: an wohldefiniertem Ort (direkt hinter (eventuellem) Boot-Sektor)
- enthält: Schlüsselparameter
- Name des Dateisystems
- Typ (NTFS, Ext ∗ , HFS, ...) → Layout der Metadaten
- Größe und Anzahl Sektoren
- Ort und Größe der i-Node-Tabelle
- Ort und Größe der Freiliste
- i-Node-Nummer des Wurzelverzeichnisses
- wird als erstes beim Öffnen („montieren“, s.u.) eines Dateisystems vom Betriebssystem gelesen:
- Typ: passende Betriebssystem-Komponente
- i-Node-Liste, Freiliste: Metadaten zum Management
- Wurzelverzeichnis: logischer Einstiegspunkt
Datenstrukturen u. Algorithmen des Betriebssystems
Ablauf eines Dateizugriffs
- Anwendungsprogramm
- im Folgenden: beteiligte Datenstrukturen und Algorithmen des Betriebssystems
fd=open(“/home/jim“, O_RDONLY);
Pfadnamenauflösung
- Lesen des i-Nodes des Wurzelverzeichnisses (Superblock)
- Lesen der Nutzdaten des Wurzelverzeichnisses: Suchen von „home“
- Lesen des i-Nodes von „home“
- Lesen der Nutzdaten des „home“-Verzeichnisses: Suchen von „jim“
- Lesen des i-Nodes von „jim“: Prüfen der Rechte zum Lesen (O_RDONLY)
- Anlegen eines Filedeskriptors im Prozess-Deskriptor,
- Rückgabe von dessen Index (fd) an Aufrufer
read(fd, &buffer, nbytes);
Transfer von nbytes aus der geöffneten Datei fd zur Variablen buffer
- Rechteprüfung
- Zugriff auf Nutzdatenadressen im i-Node über fd-Tabelle im Prozessdeskriptor; Ergebnis: Sektornummer(n) auf Speichermedium
- Auftrag an Gerätetreiber: „Transfer der Sektoren in den BS-Cache“
- Nach Fertigstellung (Interrupt):
- Kopie des Caches nach buffer,
- Rückgabe der Anzahl der tatsächlich gelesenen Bytes / Fehler
Alternative Zugriffsmethode: per VMM
mmap(start, length, PROT_READ, MAP_PRIVATE, fd, offset);- Einblenden einer Datei in (eigenen) Adressraum: vm p , Kap. 3
- Zugriffsoperationen: sind reguläre Arbeitsspeicherzugriffe
- Zugriff auf Medium: durch reguläre Seitenfehlerbehandlung des VMMs
Vergleich Bsp Kontozugriff
read/write
struct konto_t konto;
off_t kontoOffset;
fd=open(“kontodatei“, O_RDWR);
kontoOffset = kontoNr*sizeof(konto_t);
lseek(fd,kontoOffset);
read(fd, &konto, sizeof(konto_t));
konto.stand = 0;
lseek(fd,kontoOffset);
write(fd, &konto, sizeof(konto_t));
=> 6 Operationen
mmap
struct konto_t kontenDB[kontenZahl];
fd=open(“kontodatei“, O_RDWR);
mmap(&kontenDB, ... , RW, ..., fd, 0);
kontenDB[kontoNr].stand = 0;
=> 1 Operation
-
read/write
- Umständliche Benutzung
- jede Operation erfordert Kopieren (teuer!)
- Caching des Dateisystems wird genutzt
- kleinste Transfereinheit 1 Sektor
-
mmap
- direkter Zugriff auf Daten, implizite Leseoperationen per VMM
- keine Kopieroperationen
- VMM, working set, wird genutzt
- kleinste Transfereinheit 1 Seite
-
close(fd)
- Freigabe des Filedeskriptors im Prozess-Deskriptor
- Zurückschreiben der gecachten Informationen (i-Node, Nutzdaten)
- implizit, im Rahmen des Dateisystem-internen Cachemanagements (Alterung)
- explizit, durch fsync()
-
munmap(start,length)
- hebt Assoziation zwischen Datei und Arbeitsspeicher auf (vm p )
- weitere Zugriffe: Speicherzugriffsfehler
- Zurückschreiben modifizierter Seiten
- implizit, im Rahmen des regulären Pagings (Verlassen des working sets)
- explizit, durch msync()
- hebt Assoziation zwischen Datei und Arbeitsspeicher auf (vm p )
Netzwerkmanagement
Räumlich verteilte Systeme
- Arbeitsplatzrechner, Server, Laptops, Smartphones, dedizierte IT-Geräte
- Kommunikationsmedien (LANs, WLANs, WANs; diverse Technologien)
Verteilte Dienste und Anwendungen
- Email, Web
- Netzwerk-Dateisysteme, ssh
- Grid-Computing, Cloud-Computing
- Energieinfrastrukturmanagementsysteme
Rechnergrenzen überschreitende Kommunikation
- ein geeignetes Paradigma muss her
- Socket: standardisierte Betriebssystem-Abstraktion zur Botschaften basierten Kommunikation in heterogenen verteilten Systemen
(Berkeley * -)Sockets
- botschaftenbasiert, send/receive-Modell
- komplex in der Nutzung, da
- universell: Implementierungsbasis anwendungsnäherer Modelle (RPC, RMI, Blackboards, Tuple Spaces, ... → Kommunikationsmodelle)
- problemspezifisch konfigurierbar hinsichtlich
- Synchronität (send/receive-Operationen)
- Verlässlichkeit (Garantien über Zustellung, Reihenfolgeerhalt)
- Kommunikationsdomäne (Internet, lokales System, Novell-Netz, ...)
Die Socket-Abstraktion:
- Socket: Steckdose ins Netzwerk (Betriebssystem-)Objekt, zu dem gesendet oder von dem empfangen wird)
- mit Socket assoziiert:
- Name (z.B. IP-Adresse in der Internet-Domäne, Port-Nummer)
- Protokoll (z.B. TCP, UDP)
- Kommunikation: über Socket-Paare
Betriebssystem-Integration
- Socket als Betriebssystem-Abstraktion: Teil der API
- BS-Komponente: Integrationsrahmen für Protokollimplementierungen
- Darstellung: Rahmen, den Betriebssysteme zur Integration von Protokollen bieten
Socketframework des Betriebssystems
-
auf Anwendungsebene implementierte, Sockets nutzende Protokolle (smtp, http, ftp, ...)
-
Kommunikationsframework im Betriebssystem
- Socket-Level
- TCP/UDP/...-Level
- IP-Level
- Netzwerktreiber
- Gerätecontroller-Hardware ("Netzwerkkarten")
werden die 7 Ebenen des ISO/OSI-Schichtenmodells implementiert
Zusammenfassung
- Betriebssystem-Abstraktion zur (Rechnergrenzen überschreitenden) Kommunikation
- botschaftenorientiertes Kommunikationsmodell
- vielfältig konfigurierbar (Protokolle, Verlässlichkeit, Synchronität, ...)
- weitgehend unabhängig von Netzwerk-Technologien
- als Betriebssystem-Abstraktion Teil der API
- Betriebssystem-Komponente: Integrationsrahmen für Protokollimplementierungen
E/A Systeme
85% der Ausfälle heutiger Standard-Betriebssysteme haben ihre Ursache im E/A-System!
Programmierung eines Plattenlaufwerks
- Geräteschnittstelle
- ein Bündel von Steuerungs-, Status-, Adress- und Datenregistern
- erreichbar über bestimmte (s.u.) Adressen
- Typische Operationen
- Start/Stopp/Zustandsabfrage des Spindelmotors
- Positionierung des Lese/Schreibkopfes
- Datentransferoperationen (bspw. Toshiba Laptop-Laufwerk)
- Nach Abschluss einer Operation: Ergebnisanalyse
- 23 Status- und Fehlerbits, verteilt über diverse Kontroll- und Statusregister
- Traum eines jeden Softwareentwicklers
Umgang damit
- Kapselung gerätespezifischer Merkmale
- Anzahl, Layout und Adressen der Steuerungs-, Status- und Adressregister
- Gerätekommandos und Timing
- Fehler und Fehlerbehandlung in gerätespezifischen Softwarekomponenten → Gerätemanager („Treiber“)
- hierauf aufbauende Abstraktionsschichten
Hardware Prinzipien
- Prinzipieller Aufbau von E/A-Geräten: Hardware/Software-Interface (Programmierschnittstelle): Controllerregister
- Programmierparadigma: Lesen und Schreiben von Steuerungs- und Datenregistern
Kommunikationsmuster mit einem Controller
Das Betriebssystem (Gerätemanager)
- schreibt einen Befehlscode in ein Steuerungsregister
- schreibt Parameter in Datenregister
- setzt Interrupt-Enable-Bit des Steuerungsregisters
- setzt go-Bit des Kontrollregisters Wenn die Operation ausgeführt ist: Die Controller-Hard/Firmware
- löscht go- und Interrupt-Enable-Bits
- schreibt Ergebnis/Fehlercode in Statusregister
- setzt ready-Bit
- löst (evtl.) Interrupt aus
Wie "sieht" ein Betriebssystem diese Geräte-Register?
- adressiert: über Arbeitsspeicheradressen
- 2 Varianten
- in separatem E/A Adressraum (I/O Address Space)
- Zugriff: über spezielle Operationen (Prozessor-Instruktionssatz) auf
- "I/O-Ports"
- in regulärem physischen Adressraum (Memory Mapped I/O)
- Zugriff: durch Einblendung in regulären virtuellen Adressraum
- Nutzung regulärer virtueller Adressen
- in separatem E/A Adressraum (I/O Address Space)
E/A- Adressräume
E/A-Adressraumzugriff über 2 (privilegierte!) Prozessorinstruktionen:
IN R8, #0x42liest im E/A-Adressraum das auf Adresse 0x42 liegende Controllerregister(I/O-Port 42_16)ins Prozessorregister R8OUT #0x42,R8schreibt den Inhalt von Prozessorregister R8 in das im E/A-Adressraum auf Adresse42_16liegende Controllerregister
Technik: PCI-Bridge
- Bridge-Stellung bei Zugriff auf regulären physischen Speicher:
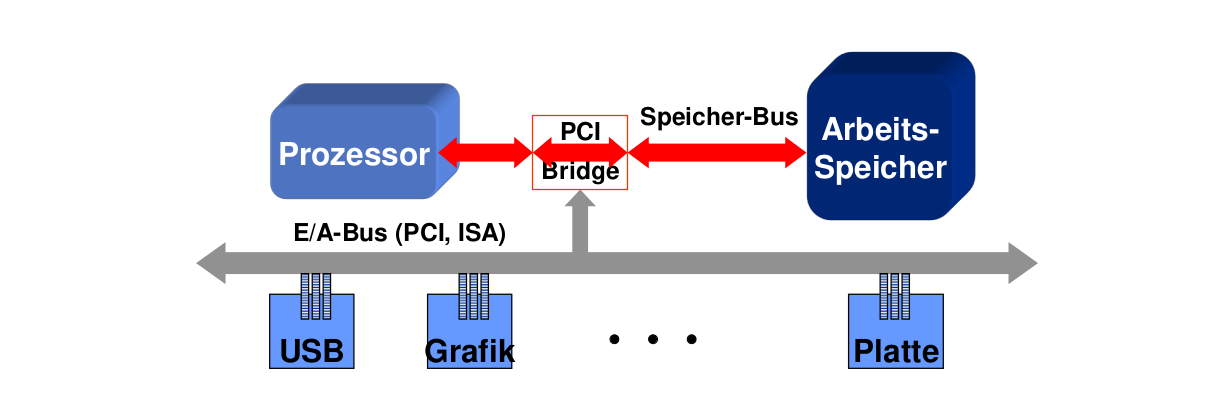
- Bridge-Stellung bei Zugriff auf E/A-Adressen:
- Bridge-Umschaltung
- Benachrichtigen der PCI-Bridge durch eigene Busleitung
- veranlasst durch "IN"- und "OUT"-Instruktionen
- Probleme hiermit
- IN/OUT sind Operationen im Prozessorinstruktionssatz
- stehen in höheren Programmiersprachen nicht direkt zur Verfügung
- (Teile der) Gerätemanagementsoftware in nativem Code des Prozessors
- Schutzkonzept des E/A-Adressraums:
- ist die Privilegierung der IN/OUT-Operationen (IO Privilege Level)
- extrem grobgranular:
- jeder Gerätemanager hat Zugriff auf sämtliche Geräte
- keine Isolation nicht vertrauenswürdiger Gerätemanager
- keine Fehlerisolation
- nicht sicher, nicht robust
- IN/OUT sind Operationen im Prozessorinstruktionssatz
Memory Mapped E/A
Controllerregisterzugriff über reguläre physische Arbeitsspeicheradressen
Schutzkonzept
- Abbildung verschiedener Geräte auf verschiedene Seiten des PA
- Abbildung dieser Seiten in die verschiedenen privaten VAe der Gerätemanager
- Isolation nicht vertrauenswürdiger Treibersoftware
- Robustheit, Sicherheit, kleine TCB (Mikrokernarchitekturen!)
Technik
- Zugriff auf Controllerregister:
- Konfiguration der PCI-Bridge beim Booten: "alle Adressen > 0xFF00... sind E/A-Register"
- E/A-Controllerregister sind hier Teil des Arbeitsspeichers
- Arbeitsspeicher: unterliegt i.A. Caching-Mechanismen
- MMU: muss „nicht cachebare Seiten“ kennen (Cache bekommt Veränderungen der Controllerregister durch Gerät nicht mit!)
- Varianten in der Praxis
- reiner E/A-Adressraum
- reine memory mapped I/O
- Hybridansätze (z.B. Pentium-Architektur): sowohl als auch
Software Prinzipien
- E/A-Operationen dauern – vergleichsweise – lange
- Wartesituationen
- ökonomische Überbrückung
- Prozessor: führt andere Aktivitäten durch
- am Ende einer E/A-Operation
- Prozessor: erhält Nachricht (Interrupt)
- von E/A-Controllern erzeugt
- über Kommunikationsbusse dem Prozessor zugestellt, dort
- asynchrone Unterbrechung des regulären Prozessablaufs
- Start der ISRs der Gerätemanager
Gerätemanager ("Treiber")
- gerätespezifische Software mit direktem Zugriff auf HW-Ressourcen
- Komponenten:
- Auftragsannahme - Schnittstelle zu höheren BS-Ebenen (Reader/Writer-Queues) - Kommunikation mit Gerät (Controller-HW): Auftragserteilung
- Ergebnisanalyse (ISR) - Kommunikation mit Gerät (Controller-HW): Interruptbehandlung - Kommunikation mit höheren BS-Ebenen: Ergebnisrückgabe
BS-Integration
- im Maschinenraum
- Integrationsrahmen für gerätespezifische Software
In heutigen Standardbetriebssystemen
- nehmen Gerätemanager ca. 80% der Distributionssoftware ein
- Hardware spezifische Konfiguration
- liegt die Ursache ca. 85% aller Systemausfälle in (Fremd-) Gerätemanagern:
- Komplexität der Programmierung: zeitliche Bedingungen, Parallelität, Synchronisation
- Diversität des Gerätezoos
- Diversität der HW- und Gerätemanager-Hersteller
- Innovationsfreudigkeit und time-to-market → Bananensoftware
- Massive Robustheits- und Sicherheitsprobleme !
Problemfolgen
- Management der Schwachstellen
- Treiberzertifizierung (automatisierte Korrektheitsanalysen)
- Flicken "42 wichtige Updates stehen bereit" ...
- Architekturprinzipien robuster und sicherer Systeme (→ Kap. 7)
- Isolation nicht verifizierter verifizierbarer (Treiber-)Software
- Ausfallerkennung und -behandlung
- Treiberwrapping, micro-reboot
- Mikrokernarchitekturen
Zusammenfassung
HW-Programmierung mittels
- Controller-Register
- in E/A-Adressräumen
- im Arbeitsspeicher (Memory Mapped E/A)
- Isolation, Robustheit, Sicherheit
- Interruptsystem
- asynchrone Benachrichtigungen
Software-Prinzipien
- Gerätemanager (Treiber)
- Auftragsmanagement
- ISRs
High-End-Betriebssysteme
Was sind High-End- Betriebssysteme?
In-etwa-Übersetzung: „Fortgeschrittene“ Betriebssysteme (engl. „Advanced Operating Systems“)
Es geht um:
- „Einbau“ nichtfunktionaler Eigenschaften
- neue Konzepte für die Architektur von Betriebssystemen
- neue Abstraktionen innerhalb von Betriebssystemen
- ...
Wir greifen 2 nichtfunktionale Eigenschaften von Betriebssystemen heraus, die insbesondere damit zu tun haben, dass kein (Betriebs)System vollständig fehlerfrei ist! und eine wichtige Notwendigkeit besteht in der Reduktion operationaler Risiken Verantwortbarkeit
Sicherheit
Das Problem: Paradigmatische Grundlagen heutiger Mainstream-Betriebssysteme stammen aus den 60er Jahren des letzten Jahrtausends (Prozesse, Dateien, Kommunikation, ...)
Die Folge: Für viele kritische Anwendungsgebiete
- unzulängliche Paradigmen
- schwache Implementierungen
- unzureichende Sicherheit (engl. Security – nicht Safety!!) z.B. gegen Hacker, Spionage, Sabotage ...
High End: Paradigmenwechsel
Ein Beispiel: SELinux
Ziel: Security Enhanced Linux
- state-of-the-art Betriebssystem
- state-of-the-art Sicherheitsparadigmen
Idee: durch Sicherheitspolitik gesteuertes Betriebssystem
Technischer Ansatz (z.B.) SELinux = Linux + Sicherheitspolitiken
Sicherheitspolitiken in SELinux
- neue Betriebssystem-Abstraktion (die erste seit 50 Jahren)
- absolute Kontrolle über kritische Funktionen des Betriebssystems
- spezifiziert durch Regelmenge
- implementiert durch die SELinux-Sicherheitsarchitektur
SELinux-Sicherheitsarchitektur
- Security Server (strategische Komponente): Laufzeitumgebung für Sicherheitspolitik in Schutzdomäne des BS-Kerns
- Interzeptoren (Politikdurchsetzung): vollständige Kontrolle
Spezifikation einer Sicherheitspolitik
- Sicherheitspolitik: Regelmenge der Art
allow <user_dom> <apps_dom>: <mailer> allow <execute> <auth_dom> <auth_dom>: <passwd> <write> - kritisch
- Korrektheit (100.000 Regeln ...)
- Vollständigkeit
- Widerspruchsfreiheit
- Security Engineering
- Politikspezifikation
- Politikanalyse
- Sicherheitsarchitekturen
Robustheit
Ziel: Tolerierung unvorhergesehener Fehler und Ausfälle
Auch hier ein Beispiel: Architekturprinzipien
- monolithische Architektur
- BS-Komponenten zusammengefasst zu
- einem Programmsystem
- in einem Adressraum
- Kommunikation untereinander mittels Prozeduraufrufen
- Fehlerausbreitung: innerhalb des (großen) BS-Adressraums
- Mikrokernarchitektur
- BS-Komponenten bilden
- separate Funktionseinheiten
- mit individuellen Adressräumen
- Kommunikation: mittels Prozedurfernaufrufen
- Fehlerausbreitung: gestoppt an Adressraumgrenze(n)
Folgen
- Korrektheit
- Fehlerausbreitung
- Aussagekraft formaler Verifikation von BS-Komponenten
- Robustheit
- Fehlerisolation
- Fehlerbehebung (vgl. Micro-Reboot)
Abschließend
Risikoszenarien und High-End Betriebssysteme
- IT-Sicherheit & Security Engineering
- Design von Sicherheitseigenschaften und Architekturen
- AOS
- (z.B. Robustheit)
- Konzepte, Architekturen, Algorithmen
Abschließende Zusammenfassung und Schwerpunkte
- Betriebssysteme
- Spektrum der Anwendungsszenarien
- Spektrum der Aufgaben
- funktionale u. nichtfunktionale Eigenschaften von Betriebssystemen
- Prozessormanagement
- Prozesse u. Threads
- Betriebssystem-Abstraktion „Prozess“
- Prozessmodelle
- Prozessmanagement und Prozessdeskriptor
- Threads, Multithread-Prozessmodelle u. Threaddeskriptor
- Prozesse u. Threads
- Betriebssystem-Abstraktion „Prozess“
- Prozessmodelle
- Prozessmanagement und Prozessdeskriptor
- Threads u. Thread-Typen
- Multithread-Prozessmodelle u. Threaddeskriptor
- Scheduling u. Scheduling-Strategien
- Scheduling: Notwendigkeit, Sinn u. Grundaufgabe
- Zustandsmodelle
- Kontextwechsel
- diverse Scheduling-Strategien
- Privilegierungsebenen
- Prozessormodi: Zweck u. Handhabung
- Kommunikation & Synchronisation
- Kommunikation und Synchronisation
- Kritische Abschnitte u. wechselseitiger Ausschluss
- Mechanismen zur Kommunikation u. Synchronisation
- Botschaften und Botschaften basierte Kommunikation
- Motivation
- elementare Operationen
- Fernaufrufe (RPCs)
- Systemaufrufe
- Ereignismanagement
- Notwendigkeit des Ereignismanagement
- Umgangsformen mit Ereignissen
- Interrupts und Programmiermodelle zum Umgang damit
- Interrupt-Vektor(en) und Interrupt-Service-Routinen
- Interrupts auf Anwendungsebene
- Speichermanagement
- Speichermedien
- Speichertechnologien u. deren Eigenschaften
- Speicherhierarchien
- Arbeitsspeicher, Relokation u. Swapping
- Virtueller Speicher und dessen Management
- Virtuelle Prozessadressräume und physischer Adressraum
- Abbildungen aus virtuellen Adressräumen in den physischen Adressraum
- Seiten(abbildungs)tabellen: Funktion u. Aufbau
- Seitentabelleneinträge
- Funktion von MMU und TLB
- Seitenfehler u. Seitenfehlerbehandlung
- Seitenaustauschalgorithmen
- Segmentierung
- Prinzip
- Sinn der Segmentierung
- Segmentierung u. Paging
- Dateisysteme
- Motivation
- Dateimodelle
- Dateinamen
- Dateistrukturen
- Dateiattribute
- Operationen auf Dateien
- Speichermedien: Magnetplatten u. SSDs
- Management-Datenstrukturen
- i-Nodes
- Verzeichnisse
- Superblock u. Freilisten
- Netzwerkmanagement
- Verteilte Systeme
- Socket-Abstraktion
- E/A Systeme
- Hardware-Prinzipien
- Geräteschnittstelle
- E/A-Adressräume
- Memory-Mapped E/A
- Software-Prinzipien
- Treiber (Gerätemanager): Funktion u. Struktur
- Treiber-Integration ins Betriebssystem
- Problemzonen
- High End Betriebssysteme
- Nichtfunktionale Eigenschaften von Betriebssystemen
- Sicherheit u. SELinux-Ansatz
- Robustheit
- Betriebssystem-Architekturen
- Makrokerne u. Mikrokerne