227 KiB
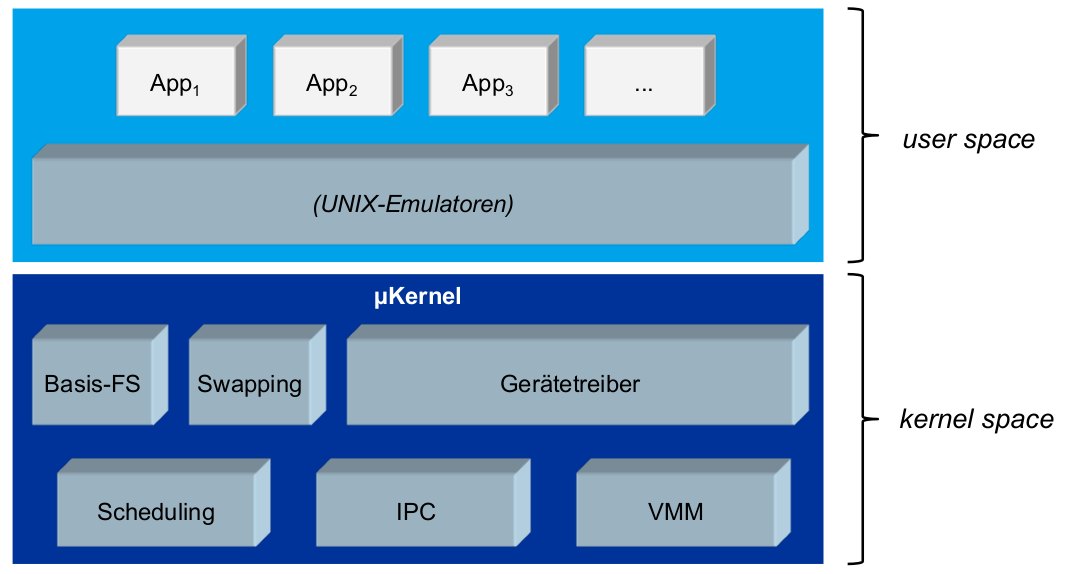
Einführung
Betriebssysteme stecken nicht nur in Einzelplatzrechnern, sondern z.B. auch in:
- Informationssystemen
- Gesundheitswesen
- Finanzdienstleister
- Verkehrsmanagement-Systemen
- Eisenbahn
- Flugwesen
- Kommunikationssystemen
- Mobilfunk
- Raumfahrt
- eingebettetenSystemen
- Multimedia
- Fahrzeugsysteme
- Sensornetze
- ...
\rightarrowverschiedenste Anforderungen!
Konsequenz: Spezialbetriebssysteme für Anforderungen wie ...
- Robustheit
- Echtzeitfähigkeit
- Energieeffizienz
- Sicherheit
- Adaptivität
- ...
Gegenstand dieser Vorlesung: Konstruktionsrichtlinien für solche ,,High-End Betriebssysteme''
Funktionale und nichtfunktionale Eigenschaften
-
Beispiel: Autokauf ,,Mit unserem Fahrzeug können Sie einkaufen fahren!''
-
Beispiel: Handykauf ,,Mit unserem Telefon können Sie Ihre Freunde und Familie anrufen!''
-
Anforderungen (Requirements)
- Funktionale und nichtfunktionale Eigenschaften (eines Produkts, z.B. Softwaresystems) entstehen durch Erfüllung von funktionalen und nichtfunktionalen Anforderungen
-
funktionale Eigenschaft
- legt fest, was ein Produkt tun soll.
- Bsp Handykauf: Das Produkt soll Telefongespräche ermöglichen.
-
eine nichtfunktionale Eigenschaft (NFE)
- legt fest, wie es dies tun soll, also welche sonstigen Eigenschaften das Produkt haben soll.
- Bsp Handykauf: Das Produkt soll klein, leicht, energiesparend, strahlungsarm, umweltfreundlich,... sein.
-
andere Bezeichnungen nichtfunktionaler Eigenschaften
- Qualitäten bzw. Qualitätsattribute (eines Software-Produkts):
- Nichtfunktionale Anforderungen bzw. Eigenschaften eines Software-Systems bzw. -Produkts oft auch als seine Qualitäten bezeichnet.
- einzelne realisierte Eigenschaft ist demzufolge ein Qualitätsattribut (quality property) dieses Systems bzw. Produkts.
- Weitere in der Literatur zu findende Begriffe in diesem Zusammenhang:
- Non-functionalrequirements/properties
- Constraints
- Quality ofservice(QoS) requirements
- u.a.
- Qualitäten bzw. Qualitätsattribute (eines Software-Produkts):
-
,,~ilities''
- im Englischen: nichtfunktionale Eigenschaften eines Systems etc. informell auch als seine ,,ilities'' bezeichnet, hergeleitet von Begriffen wie
- Stability
- Portability
- ...
- im Deutschen: ( ,,itäten'',,,barkeiten'', ... möglich aber sprachästhetisch fragenswert)
- Portab-ilität , Skalier-barkeit, aber: Offen-heit , Performanz, ...
- im Englischen: nichtfunktionale Eigenschaften eines Systems etc. informell auch als seine ,,ilities'' bezeichnet, hergeleitet von Begriffen wie
Konsequenzen für Betriebssysteme
Hardwarebasis
Einst: Einprozessor-Systeme
Heute:
- Mehrprozessor-Systeme
- hochparallele Systeme
- neue Synchronisationsmechanismen erforderlich
\rightarrowunterschiedliche Hardware und deren Multiplexing aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssystemarchitektur
Einst: Monolithische und Makrokernel-Architekturen
Heute:
- Mikrokernel(-basierte) Architekturen
- Exokernelbasierte Architekturen ( Library-Betriebssysteme )
- Virtualisierungsarchitekturen
- Multikernel-Architekturen
\rightarrowunterschiedliche Architekturen aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Ressourcenverwaltung
Einst: sog. Batch-Betriebssysteme: Stapelverarbeitung von Jobs (FIFO, Zeitgarantie: irgendwann)
Heute:
- Echtzeitgarantien für Multimedia und Safety-kritische Anwendungen (Unterhaltung, Luft-und Raumfahrt, autonomes Fahren)
- echtzeitfähige Scheduler, Hauptspeicherverwaltung, Ereignismanagement, Umgangmit Überlast und Prioritätsumkehr ...
\rightarrowunterschiedliche Ressourcenverwaltung aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssystemabstraktionen
- zusätzliche Abstraktionen und deren Verwaltung ...
- ... zur Reservierung von Ressourcen (
\rightarroweingebettete Systeme) - ... zur Realisierung von QoS-Anforderungen (
\rightarrowMultimediasysteme) - ... zur Erhöhung der Ausfallsicherheit (
\rightarrowverfügbarkeitskritische Systeme) - ... zum Schutz vor Angriffen und Missbrauch (
\rightarrowsicherheitskritische Systeme) - ... zum flexiblen und modularen Anpassen des Betriebssystems (
\rightarrowhochadaptive Systeme)
- ... zur Reservierung von Ressourcen (
\rightarrowhöchst diverse Abstraktionen von Hardware aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
Betriebssysteme als Softwareprodukte
- Betriebssystem:
- eine endliche Menge von Quellcode, indiziert durch Zeilennummern: MACOSX =
\{0, 1, 2, ..., 4399822, ...\} - ein komplexes Softwareprodukt ...welches insbesondere allgemeinen Qualitätsanforderungen an den Lebenszyklusvon Softwareprodukten unterliegt!
- eine endliche Menge von Quellcode, indiziert durch Zeilennummern: MACOSX =
- an jedes Softwareprodukt gibt es Anforderungen an seine Nutzung und Pflege
\rightarrowEvolutionseigenschaften - diese können für Betriebssysteme höchst speziell sein (Korrektheitsverifikation, Wartung, Erweiterung, ...)
\rightarrowspezielle Anforderungen an das Softwareprodukt Betriebssystem aufgrund unterschiedlicher nichtfunktionaler Eigenschaften
NFE von Betriebssystemen
Funktionale Eigenschaften (= Funktionen, Aufgaben) ... von Betriebssystemen:
- Betriebssysteme: sehr komplexe Softwareprodukte
- Ein Grund hierfür: besitzen Reihe von differenzierten Aufgaben - also funktionale Eigenschaften
Grundlegende funktionale Eigenschaften von Betriebssystemen:
- Hardware-Abstraktion (Anwendungen/Programmierern eine angenehme Ablaufumgebung auf Basis der Hardware bereitstellen)
- Hardware-Multiplexing (gemeinsame Ablaufumgebung zeitlich oder logisch getrennt einzelnen Anwendungen zuteilen)
- Hardware-Schutz (gemeinsame Ablaufumgebung gegen Fehler und Manipulation durch Anwendungen schützen)
Nichtfunktionale Eigenschaften (Auswahl) von Betriebssystemen:
- Laufzeiteigenschaften
- Sparsamkeit und Effizienz
- Robustheit
- Verfügbarkeit
- Sicherheit (Security)
- Echtzeitfähigkeit
- Adaptivität
- Performanz
- Evolutionseigenschaften
- Wartbarkeit
- Portierbarkeit
- Offenheit
- Erweiterbarkeit
Klassifizierung: Nichtfunktionale Eigenschaften unterteilbar in:
- Laufzeiteigenschaften (execution qualities)
- zur Laufzeit eines Systems beobachtbar
- Beispiele: ,,security'' (Sicherheit), ,,usability'' (Benutzbarkeit), ,,performance'' (Performanz), ...
- Evolutionseigenschaften (evolution qualities)
- charakterisieren (Weiter-) Entwicklung- und Betrieb eines Systems
- Beispiele: ,,testability'' (Testbarkeit), ,,extensibility'' (Erweiterbarkeit) usw.
- liegen in statischer Struktur eines Softwaresystems begründet
Inhalte der Vorlesung
Auswahl sehr häufiger NFE von Betriebssystemen:
- Sparsamkeit und Effizienz
- Robustheit
- Verfügbarkeit
- Sicherheit (Security)
- Echtzeitfähigkeit
- Adaptivität
- Performanz
Diskussion jeder Eigenschaft: (Bsp.: Echtzeitfähigkeit)
- Motivation, Anwendungsgebiete, Begriffsdefinition(en) (Bsp.: Multimedia- und eingebettete Systeme)
- Mechanismen und Abstraktionen des Betriebssystems (Bsp.: Fristen, Deadline-Scheduler)
- unterstützende Betriebssystem-Architekturkonzepte (Bsp.: Mikrokernel)
- ein typisches Beispiel-Betriebssystem (Bsp.: QNX)
- Literaturliste
Sparsamkeit und Effizienz
Motivation
Sparsamkeit (Arbeitsdefinition): Die Eigenschaft eines Systems, seine Funktion mit minimalem Ressourcenverbrauchauszuüben.
Hintergrund: sparsamer Umgang mit einem oder mehreren Ressourcentypen = präziser: Effizienz bei Nutzung dieser Ressourcen
Effizienz: Der Grad, zu welchem ein System oder eine seiner Komponenten seine Funktion mit minimalem Ressourcenverbrauch ausübt. (IEEE)
Entwurfsentscheidungen für BS:
- Wie muss bestimmter Ressourcentyp verwaltet werden, um Einsparungen zu erzielen?
- Welche Erweiterungen/Modifikationen des Betriebssystems (z.B. neue Funktionen, Komponenten, ...) sind hierfür notwendig?
Konkretisierung: Ressource, welche sparsam verwendet wird.
Beispiele:
- mobile Geräte: Sparsamkeit mit Energie
- kleine Geräte, eingebettete Systeme:
- Sparsamkeit mit weiteren Ressourcen, z.B. Speicherplatz
- Betriebssystem (Kernel + User Space): geringer Speicherbedarf
- optimale Speicherverwaltung durch Betriebssystem zur Laufzeit
- Hardwareoptimierungen im Sinne der Sparsamkeit:
- Baugrößenoptimierung(Platinen-und Peripheriegerätegröße)
- Kostenoptimierung(kleine Caches, keine MMU, ...)
- massiv reduzierte HW-Schnittstellen (E/A-Geräte, Peripherie, Netzwerk)
Mobile und eingebettete Systeme (eine kleine Auswahl)
- mobile Rechner-Endgeräte
- Smartphone, Smartwatch
- Laptop-/Tablet-PC
- Weltraumfahrt und -erkundung
- Automobile
- Steuerung von Motor-und Bremssystemen
- Fahrsicherheit
- Insasseninformation (und -unterhaltung)
- (teil-) autonomes Fahren
- verteilte Sensornetze (WSN)
- Chipkarten
- Multimedia-und Unterhaltungselektronik
- eBookReader
- Spielkonsolen
- Digitalkameras
Beispiel: Weltraumerkundung
- Cassini-Huygens (1997-2017)
- Radionuklidbatterien statt Solarzellen
- Massenspeicher: SSDs statt Magnetbänder
- Rosetta (2004-2016)
- 31 Monate im Energiesparmodus
- Opportunity (2003-2019)
- geplante Missionsdauer: 90 d
- Missionsdauer insgesamt: >> 5000 d
- Hayabusa (2003-2010)
- Beschädigung der Energieversorgung
- Energiesparmodus: um 3 Jahre verzögerte Rückkehr
- Voyager 1 (1977 bis heute)
- erste Flugphase: periodisch 20 Monate Standby, 20 Stunden Messungen
- liefert seit 40 Jahren Daten
Energieeffizienz
Hardwaremaßnahmen
- zeitweiliges Abschalten/Herunterschalten momentan nicht benötigter Ressourcen, wie
- Laufwerke: CD/DVD, ..., Festplatte
- Hauptspeicherelemente
- (integrierte/externe) Peripherie: Monitor, E/A-Geräte, ...
Betriebssystemmechanismen
- Dateisystem-E/A:energieeffizientes Festplatten-Prefetching(2.2.1)
- CPU-Scheduling: energieeffizientes Scheduling(2.2.2)
- Speicherverwaltung:minimale Leistungsaufnahme durchSpeicherzugriffe mittels Lokalitätsoptimierung [DGMB07]
- Netzwerk:energiebewusstes Routing
- Verteiltes Rechnen auf Multicore-Prozessoren: temperaturabhängige Lastverteilung
- ...
Energieeffiziente Dateizugriffe
Hardwarebedingungen: Magnetplatten (HDD), Netzwerkgeräte, DRAM-ICs,... sparen nur bei relativ langen Inaktivitätsintervallen Energie.
- Aufgabe: Erzeugen kurzer, intensiver Zugriffsmuster
\rightarrowlange Inaktivitätsintervalle (für alle Geräte mit geringem Energieverbrauch im Ruhezustand) - Beobachtung bei HDD-Geräten: i.A. vier Zustände mit absteigendem Energieverbrauch:
- Aktiv: einziger Arbeitszustand
- Idle (Leerlauf): Platte rotiert, aber Plattenelektronik teilweise abgeschaltet
- Standby: Rotation abgeschaltet
- Sleep: gesamte restliche Elektronik abgeschaltet
- ähnliche, noch stärker differenzierte Zustände bei DRAM (vgl. [DGMB07] )
Energiezustände beim Betrieb von Festplatten:
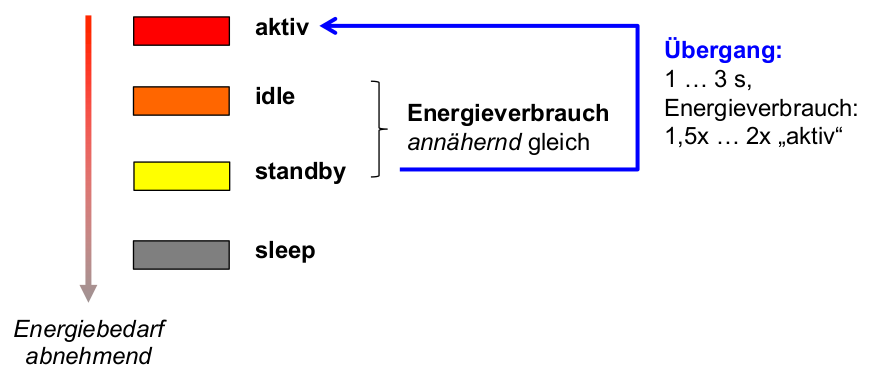
- Schlussfolgerung: durch geringe Verlängerungen des idle - Intervalls kann signifikant der Energieverbrauch reduziert werden.
Prefetching-Mechanismus
- Prefetching (,,Speichervorgriff'', vorausschauendes Lesen) & Caching
- Standard-Praxis bei moderner Datei-E/A
- Voraussetzung: Vorwissen über benötigte Folge von zukünftigen Datenblockreferenzen (z.B. Blockadressen für bestimmte Dateien, gewonnen durch Aufzeichnung früherer Zugriffsmuster beim Start von Anwendungen -Linux: readahead syscall)
- Ziel: Performanzverbesserungdurch Durchsatzerhöhung u. Latenzzeit-Verringerung
- Idee: Vorziehen möglichst vieler E/A-Anforderungen an Festplatte + zeitlich gleichmäßige Verteilung der verbleibenden
- Umsetzung: Caching (Zwischenspeichern) dieser vorausschauend gelesenen Blöcke in ungenutzten Hauptspeicherseitenrahmen ( pagecache )
- Folge: Inaktivitätsintervalle überwiegend sehr kurz
\rightarrowEnergieeffizienz ...? - Zugriffsoperation: (durch Anwendung)
- access(x) ... greife (lesend/schreibend) auf den Inhalt von Festplattenblock x im Page Cache zu
- Festplattenoperationen:
- fetch(x) ... hole Block x nach einem access(x) von Festplatte
- prefetch(x) ... hole Block x ohne access(x) von Festplatte
- beide Operationen schreiben x in einen freien Platz des Festplattencaches; falls dieser voll ist ersetzen sie einen der Einträge gemäß fester Regeln
\rightarrowTeil der (Pre-) Fetching-Strategie
- Beispiel für solche Strategien: Anwendung ...
- mit Datenblock-Referenzstrom A, B, C, D, E, F, G, ...
- mit konstanter Zugriffsdauer: 10 Zeiteinheiten je Blockzugriff
- Cache-Kapazität: 3 Datenblöcke
- Zeit zum Holen eines Blocks bei Cache-Miss: 1 Zeiteinheit
- Beispiel: Traditionelles Prefetching
- Fetch-on-demand-Strategie (kein vorausschauendes Lesen)
- Strategie entsprechend Prefetching- Regeln nach Cao et al. [CFKL95] (= traditionelle Disk-Prefetching- Strategie)
- traditionelle Prefetching-Strategie: bestimmt
- wann ein Datenblock von der Platte zu holen ist (HW-Zustand aktiv )
- welcher Block zu holen ist
- welcher Block zu ersetzen ist
- Regeln für diese Strategie:
- Optimales Prefetching: Jedes prefetch sollte den nächsten Block im Referenzstrom in den Cache bringen, der noch nicht dort ist.
- Optimales Ersetzen: Bei jedem ersetzenden prefetch sollte der Block überschrieben werden, der am spätesten in der Zukunft wieder benötigt wird.
- ,,Richte keinen Schaden an'': Überschreibe niemals Block A um Block B zu holen, wenn A vor B benötigt wird.
- Erste Möglichkeit: Führe nie ein ersetzendes prefetch aus, wenn dieses schon vorher hätte ausgeführt werden können.
- Energieeffizientes Prefetching
- Optimale Ersetzungsstrategie und 3 unterschiedliche Prefetching-Strategien:
- Fetch-on-demand-Strategie:
- Laufzeit: 66 ZE für access(A) ... access(F) , 7 Cache-Misses
- Disk-Idle-Zeit: 6 Intervalle zu je 10 ZE
- Strategie entsprechend Prefetching-Regeln [CFKL95] (traditionelle Disk-Prefetching-Strategie):
- Laufzeit: 61 ZE für access(A) ... access(F) , 1 Cache-Miss
- Disk-Idle-Zeit: 5 Intervalle zu je 9 ZE und 1 Intervall zu 8 ZE (= 53 ZE)
- Energieeffiziente Prefetching-Strategie, die versucht Länge der Disk-Idle-Intervalle zu maximieren:
- gleiche Laufzeit und gleiche Anzahl Cache-Misses wie traditionelles Prefetching
- Disk-Idle-Zeit: 2 Intervalle zu 27 bzw. 28 ZE (= 55 ZE)
- Auswertung: Regeln für energieeffiziente Prefetching-Strategie nach Papathanasiou elal.: [PaSc04]
- Optimales Prefetching: Jedes prefetch sollte den nächsten Block im Referenzstrom in den Cache bringen, der noch nicht dort ist.
- Optimales Ersetzen: Bei jedem ersetzenden prefetch sollte der Block überschrieben werden, der am spätesten in der Zukunft wieder benötigt wird.
- ,,Richte keinen Schaden an'': Überschreibe niemals Block A um Block B zu holen, wenn A vor B benötigt wird.
- Maximiere Zugriffsfolgen: Führe immer dann nach einem fetch oder prefetch ein weiteres prefetch aus, wenn Blöcke für eine Ersetzung geeignet sind. (i.S.v. Regel 3)
- Beachte Idle-Zeiten: Unterbrich nur dann eine Inaktivitätsperiode durch ein prefetch , falls dieses sofort ausgeführt werden muss, um einen Cache-Miss zu vermeiden.
Allgemeine Schlussfolgerungen
- Hardware-Spezifikation nutzen: Modi, in denen wenig Energie verbraucht wird
- Entwicklung von Strategien, die langen Aufenthalt in energiesparenden Modi ermöglichen , und dabei Leistungsparameter in vertretbarem Umfang reduzieren
- Implementieren dieser Strategien in Betriebssystemmechanismen zur Ressourcenverwaltung
Energieeffizientes Prozessormanagement
Hardware-Gegebenheiten
- z.Zt. meistgenutzte Halbleitertechnologie für Prozessor-Hardware: CMOS ( Complementary Metal Oxide Semiconductor)
- Komponenten für Energieverbrauch:
P = P_{switching} + P_{leakage} + ...P_{switching}: für Schaltvorgänge notwendige LeistungP_{leakage}: Verlustleistung durch verschiedene Leckströme- ...: weitere Einflussgrößen (technologiespezifisch)
Hardwareseitige Maßnahmen
Schaltleistung: P_{switching}
- Energiebedarf kapazitiver Lade-u. Entladevorgänge während des Schaltens
- für momentane CMOS-Technologie i.A. dominanter Anteil am Energieverbrauch
- Einsparpotenzial: Verringerung von
- Versorgungsspannung (quadratische Abhängigkeit!)
- Taktfrequenz
- Folgen:
- längere Schaltvorgänge
- größere Latenzzwischen Schaltvorgängen
- Konsequenz: Energieeinsparung nur mit Qualitätseinbußen(direkt o. indirekt) möglich
- Anpassung des Lastprofils ( Zeit-Last-Kurve? Fristen kritisch? )
- Beeinträchtigung der Nutzererfahrung( Reaktivität kritisch? Nutzungsprofil? )
Verlustleistung: P_{leakage}
- Energiebedarf baulich bedingter Leckströme
- Fortschreitende Hardware-Miniaturisierung
\Rightarrowzunehmender Anteil vonP_{leakage}an P - Beispielhafte Größenordnungen zum Einsparpotenzial:
Schaltkreismaße Versorgungsspannung P_{leakage}/P180 nm 2,5 V 0, 70 nm 0,7 V 0, 22 nm 0,4 V > 0,5 - Konsequenz: Leckströme kritisch für energiesparenden Hardwareentwurf
Regelspielraum: Nutzererfahrung
- Nutzererwartung: wichtigstes Kriterium zur (subjektiven) Bewertung von auf einem Rechner aktiven Anwendungen durch Nutzer
\rightarrowNutzerwartung bestimmt Nutzererfahrung - Typ einer Anwendung
- entscheidet über jeweilige Nutzererwartung
- Hintergrundanwendung (z.B. Compiler); von Interesse: Gesamt-Bearbeitungsdauer, Durchsatz
- Echtzeitanwendung(z.B. Video-Player, MP3-Player); von Interesse: ,,flüssiges'' Abspielen von Video oder Musik
- Interaktive Anwendung (z.B. Webbrowser); von Interesse: Reaktivität, d.h. keine (wahrnehmbare) Verzögerung zwischen Nutzer-Aktion und Rechner-Reaktion
- Insbesondere kritisch: Echtzeitanwendungen, interaktive Anwendungen
- entscheidet über jeweilige Nutzererwartung
Reaktivität
- Reaktion von Anwendungen
- abhängig von sog. Reaktivität des Rechnersystems ≈ durchschnittliche Zeitdauer, mit der Reaktion eines Rechners auf eine (Benutzerinter-) Aktion erfolgt
- Reaktivität: von Reihe von Faktoren abhängig, z.B.:
- von Hardware an sich
- von Energieversorgung der Hardware (wichtig z.B. Spannungspegel an verschiedenen Stellen)
- von Software-Gegebenheiten (z.B. Prozess-Scheduling, Speichermanagement, Magnetplatten-E/A-Scheduling, Vorgänge im Fenstersystem, Arten des Ressourcen-Sharing usw.)
Zwischenfazit: Nutzererfahrung
- bietet Regelspielraum für Hardwareparameter (
\rightarrowSchaltleistung)\rightarrowVersorgungsspannung, Taktfrequenz - Betriebssystemmechanismen zum energieeffizienten Prozessormanagement müssen mit Nutzererfahrung(jeweils erforderlicher Reaktivität) ausbalanciert werden (wie solche Mechanismen wirken: 2.2.3)
- Schnittstelle zu anderen NFE:
- Echtzeitfähigkeit
- Performanz
- Usability
- ...
Energieeffizientes Scheduling
- so weit besprochen: Beschränkung des durchschnittlichen Energieverbrauchs eines Prozessors
- offene Frage zum Ressourcenmultiplexing: Energieverbrauch eines Threads/Prozesses?
- Scheduling-Probleme beim Energiesparen:
- Fairness (der Energieverteilung)?
- Prioritätsumkehr?
- Beispiel: Round Robin (RR) mit Prioritäten (Hoch, Mittel, Niedrig)
- Problem 1: Unfaire Energieverteilung
- Beschränkung des Energieverbrauchs (durch Qualitätseinbußen, schlimmstenfalls Ausfall)ab einem oberen Schwellwert
E_{max} - Problem: energieintensive Threads behindern alle nachfolgenden Threads trotz gleicher Priorität
\rightarrowFairnessmaß von RR (gleiche Zeitscheibenlänge T ) untergraben
- Beschränkung des Energieverbrauchs (durch Qualitätseinbußen, schlimmstenfalls Ausfall)ab einem oberen Schwellwert
- Problem 2: energieintensive Threads niedrigerer Priorität behindern später ankommende Threads höherer Priorität

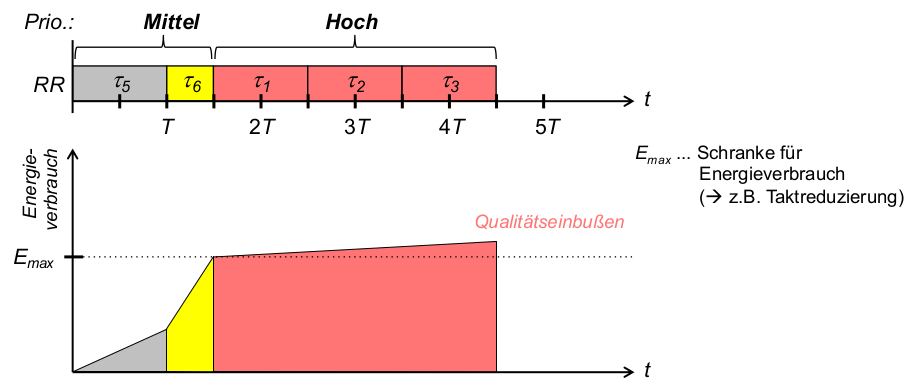
Energiebewusstes RR: Fairness
- Begriffe:
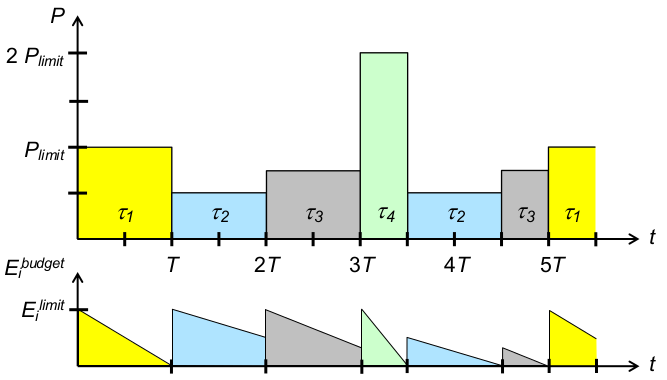
E_i^{budget}... Energiebudget vont_iE_i^{limit}... Energielimit vont_iP_{limit}... Leistungslimit: maximale Leistungsaufnahme [Energie/Zeit]T... resultierende Zeitscheibenlänge
- Strategie 1: faire Energieverteilung (einheitliche Energielimits)
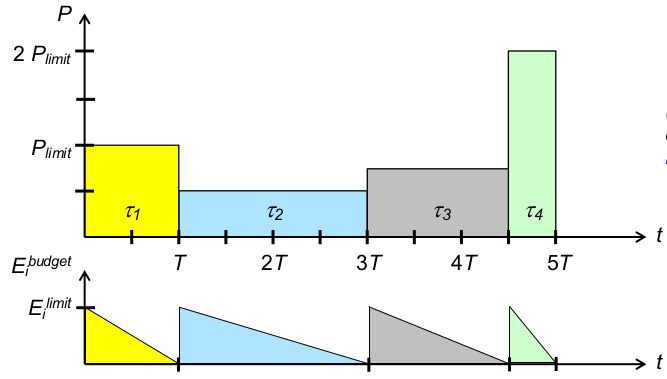
1\leq i\leq 4: E_i^{limit} = P_{limit}* T- (Abweichungen = Wichtung der Prozesse
\rightarrowbedingte Fairness)
Energiebewusstes RR: Reaktivität
- faire bzw. gewichtete Aufteilung begrenzter Energie optimiert Energieeffizienz
- Problem: lange, wenig energieintensive Threads verzögern Antwort-und Wartezeiten kurzer, energieintensiver Threads
- Lösung im Einzelfall: Wichtung per
E_i^{limit} - globale Reaktivität (
\rightarrowNutzererfahrung bei interaktiven Systemen) ...?
- Lösung im Einzelfall: Wichtung per
- Strategie 2: maximale Reaktivität (
\rightarrowklassisches RR)
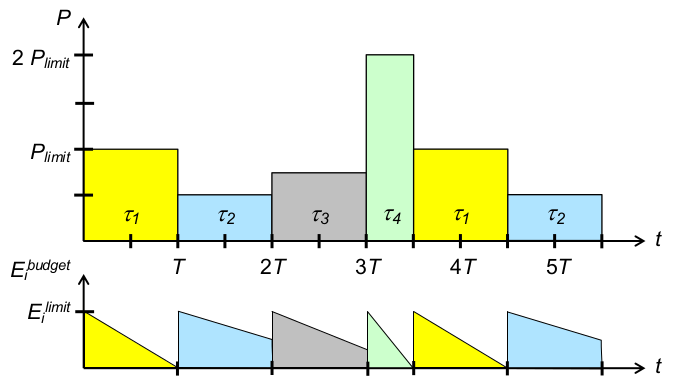
Energiebewusstes RR: Reaktivität und Fairness
- Problem: sparsame Threads werden bestraft durch Verfallen des ungenutzten Energiebudgets
- Idee: Ansparen von Energiebudgets
\rightarrowmehrfache Ausführung eines Threads innerhalb einer Scheduling-Periode - Strategie 3: Reaktivität, dann faire Energieverteilung
Implementierungsfragen
-
Scheduling-Zeitpunkte?
- welche Accounting-Operationen (Buchführung über Budget)?
- wann Accounting-Operationen?
- wann Verdrängung?
-
Datenstrukturen?
- ... im Scheduler
\rightarrowWarteschlange(n)? - ... im Prozessdeskriptor?
- ... im Scheduler
-
Kosten ggü. klassischem RR? (durch Prioritäten...?)
-
Pro:
- Optimierung der Energieverteilung nach anwendungsspezifischen Schedulingzielen(
\rightarrowStrategien) - Berücksichtigung von prozessspezifischen Energieverbrauchsmustern möglich:fördert Skalierbarkeit i.S.v. Lastadaptivität, indirekt auch Usability (
\rightarrowNutzererfahrung)
- Optimierung der Energieverteilung nach anwendungsspezifischen Schedulingzielen(
-
Kontra:
- zusätzliche sekundäre Kosten: Energiebedarf des Schedulers, Energiebedarf zusätzlicher Kontextwechsel, Implementierungskosten (Rechenzeit, Speicher)
- Voraussetzung hardwareseitig: Monitoring des Energieverbrauchs (erforderliche/realisierbare Granularität...? sonst: Extrapolation?)
-
generelle Alternative: energieintensive Prozesse verlangsamen
\rightarrowRegelung der CPU-Leistungsparameter (Versorgungsspannung) (auch komplementär zum Schedulingals Maßnahme nach Energielimit-Überschreitung) -
Beispiel: Synergie nichtfunktionaler Eigenschaften
- Performanz nur möglich durch Parallelität
\rightarrowMulticore-Hardware - Multicore-Hardware nur möglich mit Lastausgleich und Lastverteilungauf mehrere CPUs
- dies erfordert ebenfalls Verteilungsstrategien: ,,Energy-aware Scheduling'' (Linux-Strategie zur Prozessorallokation -nicht zeitlichem Multiplexing!)
- Performanz nur möglich durch Parallelität
Systemglobale Energieeinsparungsmaßnahmen
- Traditionelle Betriebssysteme: Entwurf so, dass zu jedem Zeitpunkt Spitzen-Performanzangestrebt
- Beobachtungen:
- viele Anwendungen benötigen keine Spitzen-Performanz
- viele Hardware-Komponenten verbringen Zeit in Leerlaufsituationen bzw. in Situationen, wo keine Spitzen-Performanz erforderlich
- Konsequenz (besonders für mobile Systeme) :
- Hardware mit Niedrigenergiezuständen(Prozessoren und Magnetplattenlaufwerke, aber auch DRAM, Netzwerkschnittstellen, Displays, ...)
- somit kann Betriebssystem Energie-Management realisieren
Hardwaretechnologien
- DPM: Dynamic Power Management
- versetzt leerlaufende/unbenutzte Hardware-Komponenten selektiv in Zustände mit niedrigem Energieverbrauch
- Zustandsübergänge durch Power-Manager (in Hardware) gesteuert, dem bestimmte DPM- Strategie (Firmware) zugrunde liegt, um gutes Verhältnis zwischen Performanz/Reaktivität und Energieeinsparung zu erzielen
- DVS: Dynamic Voltage Scaling
- effizientes Verfahren zur dynamischen Regulierungvon Taktfrequenz gemeinsammit Versorgungsspannung
- Nutzung quadratischer Abhängigkeitder dynamischen Leistung von Versorgungsspannung
- Steuerung/Strategien: Softwareunterstützungnotwendig!
Dynamisches Energiemanagement (DPM)- Strategien (Klassen) bestimmt, wann und wie lange eine Hardware-Komponente sich in Energiesparmodusbefinden sollte
- Greedy: Hardware-Komponente sofort nach Erreichen des Leerlaufs in Energiesparmodus, ,,Aufwecken'' durch neue Anforderung
- Time-out: Energiesparmodus erst nachdem ein definiertes Intervall im Leerlauf, ,,Aufwecken'' wie bei Greedy-Strategien
- Vorhersage: Energiesparmodus sofort nach Erreichen des Leerlaufs, wenn Heuristik vorhersagt,dass Kosten gerechtfertigt
- Stochastisch: Energiesparmodus auf Grundlage eines stochastischen Modells
Spannungsskalierung (DVS)
- Ziel: Unterstützung von DPM-Strategien durch Maßnahmen auf Ebene von Compiler, Betriebssystem und Applikationen:
- Compiler
- kann Informationen zur Betriebssystem-Unterstützung bezüglich Spannungs-Einstellung in Anwendungs-Code einstreuen,
- damit zur Laufzeit Informationen über jeweilige Arbeitslast verfügbar
- Compiler
- Betriebssystem (prädiktives Energiemanagement)
- kann Benutzung verschiedener Ressourcen (Prozessor usw.) beobachten
- kann darüber Vorhersagen tätigen
- kann notwendigen Performanzbereich bestimmen
- Anwendungen
- können Informationen über jeweils für sie notwendige Performanz liefern
\rightarrowKombination mit energieefizientemScheduling!
Speichereffizienz
- ... heißt: Auslastung des verfügbaren Speichers
- oft implizit: Hauptspeicherauslastung (memoryfootprint)
- besonders für kleine/mobile Systeme: Hintergrundspeicherauslastung
- Maße zur Konkretisierung:
- zeitliche Dimension: Maximum vs. Summe genutzten Speichers?
- physischer Speicherverwaltung?
\rightarrowBelegungsanteil pAR - virtuelle Speicherverwaltung?
\rightarrowBelegungsanteil vAR
- Konsequenzen für Ressourcenverwaltung durch BS:
- Taskverwaltung (Accounting, Multiplexing, Fairness, ...)
- Programmiermodell, API (besonders: dynamische Speicherreservierung)
- Sinnfrage und ggf. Strategien virtueller Speicherverwaltung (VMM)
- Konsequenzen für Betriebssystem selbst:
- minimaler Speicherbedarfdurch Kernel
- minimale Speicherverwaltungskosten (durch obige Aufgaben)
Hauptspeicherauslastung

Problem: externe Fragmentierung
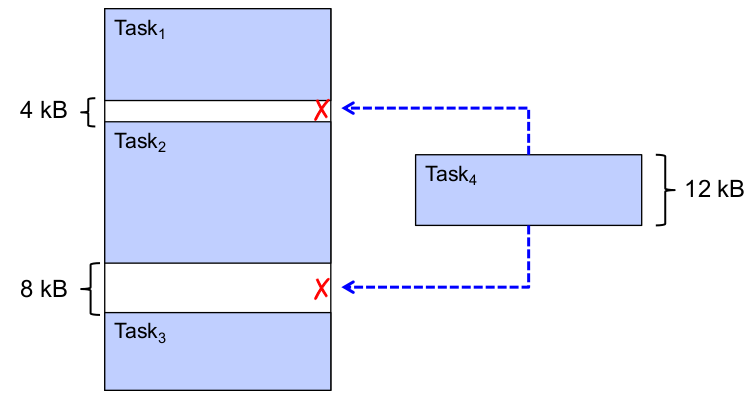
- Lösungen:
- First Fit, Best Fit, WorstFit, Buddy
- Relokation
- Kompromissloser Weg: kein Multitasking!
Problem: interne Fragmentierung
-
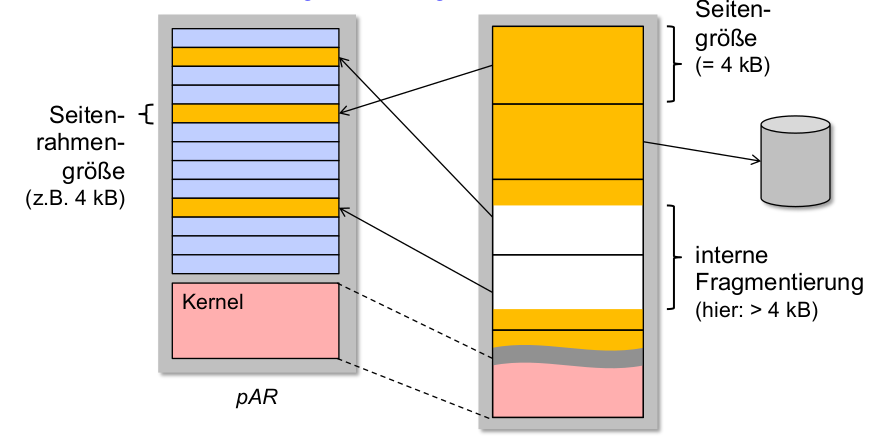
-
Lösung:
- Seitenrahmengröße verringern
- Tradeoff: dichter belegte vAR
\rightarrowgrößere Datenstrukturen für Seitentabellen!
-
direkter Einfluss des Betriebssystems auf Hauptspeicherbelegung:
\rightarrowSpeicherbedarf des Kernels- statische(Minimal-) Größe des Kernels (Anweisungen + Daten)
- dynamischeSpeicherreservierung durch Kernel
- bei Makrokernel: Speicherbedarf von Gerätecontrollern (Treibern)!
weitere Einflussfaktoren: Speicherverwaltungskosten
- VMM: Seitentabellengröße
\rightarrowMehrstufigkeit - Metainformationen über laufende Programme: Größe von Taskkontrollblöcken( Prozess-/Threaddeskriptoren ...)
- dynamische Speicherreservierung durch Tasks
Beispiel 1: sparsam
Prozesskontrollblock (PCB, Metadatenstruktur des Prozessdeskriptors) eines kleinen Echtzeit-Kernels (,,DICK''):
// Process Control Block (PCB)
struct pcb {
char name[MAXLEN +1]; // process name
proc (*addr)(); // first instruction
int type; // process type
int state; // process state
long dline; // absolute deadline
int period; // period
int prt; // priority
int wcet; // worst-case execution time
float util; // processor utilization
int *context;
proc next;
proc prev;
};
Beispiel 2: eher nicht sparsam
Linux Prozesskontrollblock (taskstruct):
struct task_struct {
volatile long state; /* - 1 unrunnable, 0 runnable, >0 stopped */
void *stack;
atomic_t usage;
unsigned int flags; /* per process flags, defined below */
unsigned int ptrace;
#ifdef CONFIG_SMP
struct llist_node wake_entry;
int on_cpu;
#endif
int on_rq;
// SCHEDULING INFORMATION
int prio, static_prio, normal_prio;
unsigned int rt_priority;
const struct sched_class *sched_class;
// Scheduling Entity
struct sched_entity se;
struct sched_rt_entity rt;
#ifdef CONFIG_CGROUP_SCHED
struct task_group *sched_task_group;
#endif
#ifdef CONFIG_PREEMPT_NOTIFIERS
struct hlist_head preempt_notifiers; /* list of struct preempt_notifier */
#endif
unsigned char fpu_counter;
#ifdef CONFIG_BLK_DEV_IO_TRACE
unsigned int btrace_seq;
#endif
unsigned int policy;
cpumask_t cpus_allowed;
#ifdef CONFIG_PREEMPT_RCU
int rcu_read_lock_nesting;
char rcu_read_unlock_special;
struct list_head rcu_node_entry;
struct rcu_node *rcu_blocked_node;
#endif /* #ifdef CONFIG_TREE_PREEMPT_RCU */
#ifdef CONFIG_RCU_BOOST
struct rt_mutex *rcu_boost_mutex;
#endif /* #ifdef CONFIG_RCU_BOOST */
#if defined(CONFIG_SCHEDSTATS) || defined(CONFIG_TASK_DELAY_ACCT)
struct sched_info sched_info;
#endif
struct list_head tasks;
#ifdef CONFIG_SMP
struct plist_node pushable_tasks;
#endif
// virtual address space reference
struct mm_struct *mm, *active_mm;
#ifdef CONFIG_COMPAT_BRK
unsigned brk_randomized:1;
#endif
#if defined(SPLIT_RSS_COUNTING)
struct task_rss_stat rss_stat;
#endif
/* task state */
int exit_state;
int exit_code, exit_signal;
int pdeath_signal; /* The signal sent when the parent dies */
unsigned int jobctl; /* JOBCTL_*, siglock protected */
unsigned int personality;
unsigned did_exec:1;
unsigned in_execve:1;/* Tell the LSMs that the process is doing an * execve */
unsigned in_iowait:1;
/* Revert to default priority/policy when forking */
unsigned sched_reset_on_fork:1;
unsigned sched_contributes_to_load:1;
#ifdef CONFIG_GENERIC_HARDIRQS
/* IRQ handler threads */
unsigned irq_thread;
#endif
pid_t pid;
pid_t tgid;
#ifdef CONFIG_CC_STACKPROTECTOR
/* Canary value for the -fstack-protector gcc feature */
unsigned long stack_canary;
#endif
// Relatives
struct task_struct __rcu *real_parent; /* real parent process */
struct task_struct __rcu *parent; /* recipient of SIGCHLD, wait4() reports */
/* children/sibling forms the list of my natural children */
struct list_head children; /* list of my children */
struct list_head sibling; /* linkage in my parent's children list */
struct task_struct *group_leader; /* threadgroup leader */
struct list_head ptraced;
struct list_head ptrace_entry;
/* PID/PID hash table linkage. */
struct pid_link pids[PIDTYPE_MAX];
struct list_head thread_group;
struct completion *vfork_done; /* for vfork() */
int __user *set_child_tid;
...
unsigned long timer_slack_ns;
unsigned long default_timer_slack_ns;
struct list_head *scm_work_list;
#ifdef CONFIG_FUNCTION_GRAPH_TRACER
/* Index of current stored address in ret_stack */
int curr_ret_stack;
/* Stack of return addresses for return function tracing */
struct ftrace_ret_stack *ret_stack;
/* time stamp for last schedule */
unsigned long long ftrace_timestamp;
...
Hintergrundspeicherauslastung
Einflussfaktoren des Betriebssystems:
- statische Größe des Kernel-Images, welches beim Bootstrapping gelesen wird
- statische Größe von Programm-Images (Standards wie ELF)
- statisches vs. dynamisches Einbinden von Bibliotheken: Größe von Programmdateien
- VMM: Größe des Auslagerungsbereichs (inkl. Teilen der Seitentabelle!) für Anwendungen
- Modularisierung (zur Kompilierzeit) des Kernels: gezielte Anpassung an Einsatzdomäne möglich
- Adaptivität (zur Kompilier-und Laufzeit) des Kernels: gezielte Anpassung an sich ändernde Umgebungsbedingungen möglich (
\rightarrowCassini-Huygens-Mission)
Architekturentscheidungen
- bisher betrachtete Mechanismen: allgemein für alle BS gültig
- ... typische Einsatzgebiete sparsamer BS: eingebettete Systeme
- eingebettetes System: (nach [Manl94] )
- Computersystem, das in ein größeres technisches System, welches nicht zur Datenverarbeitung dient,physisch eingebunden ist.
- Wesentlicher Bestandteil dieses größeren Systems hinsichtlich seiner Entwicklung, technischer Ausstattung sowie seines Betriebs.
- Liefert Ausgaben in Form von (menschenlesbaren)Informationen, (maschinenlesbaren)Daten zur Weiterverarbeitung und Steuersignalen.
- BS für eingebettete Systeme: spezielle, anwendungsspezifische Ausprägung der Aufgaben eines ,,klassischen'' Universal-BS
- reduzierter Umfang von HW-Abstraktion, generell: hardwarenähere Ablaufumgebung
- begrenzte (extrem: gar keine) Notwendigkeit von HW-Multiplexing & -Schutz
- daher eng verwandte NFE: Adaptivitätvon sparsamen BS
- sparsame Betriebssysteme:
- energieeffizient ~ geringe Architekturanforderungen an energieintensive Hardware (besonders CPU, MMU, Netzwerk)
- speichereffizient ~ Auskommen mit kleinen Datenstrukturen (memory footprint)
- Konsequenz: geringe logische Komplexität des Betriebssystemkerns
- sekundär: Adaptivität des Betriebssystemkerns
Makrokernel (monolithischer Kernel)

- User Space:
- Anwendungstasks
- CPU im unprivilegiertenModus (Unix ,,Ringe'' 1...3)
- Isolation von Tasks durch Programmiermodell(z.B. Namespaces) oder VMM(private vAR)
- Kernel Space:
- Kernelund Gerätecontroller (Treiber)
- CPU im privilegierten Modus (Unix ,,Ring'' 0)
- keine Isolation (VMM: Kernel wird in alle vAR eingeblendet)
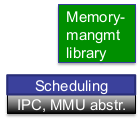
Mikrokernel
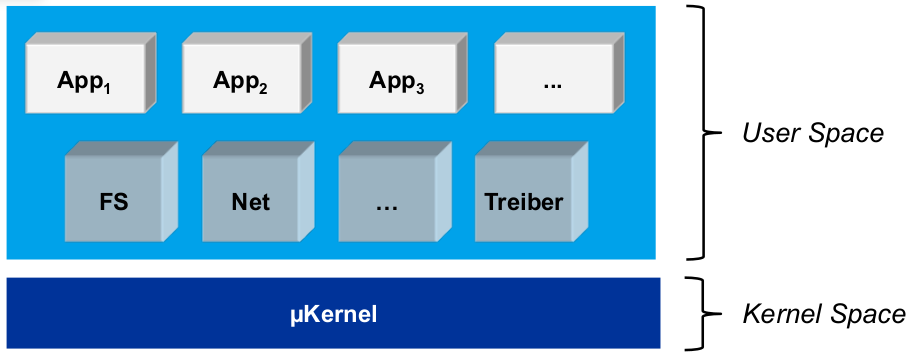
- User Space:
- Anwendungstasks, Kernel-und Treiber tasks ( Serverprozesse, grau)
- CPU im unprivilegiertenModus
- Isolation von Tasks durch VMM
- Kernel Space:
- funktional minimaler Kernel(μKernel)
- CPU im privilegierten Modus
- keine Isolation (Kernel wird in alle vAR eingeblendet)
Architekturkonzepte im Vergleich
- Makrokernel:
- ✓ vglw. geringe Kosten von Kernelcode (Energie, Speicher)
- ✓ VMM nicht zwingend erforderlich
- ✓ Multitasking (
\rightarrowProzessmanagement!)nicht zwingend erforderlich - ✗ Kernel (inkl. Treibern) jederzeit im Speicher
- ✗ Robustheit, Sicherheit, Adaptivität
- Mikrokernel:
- ✓ Robustheit, Sicherheit, Adaptivität
- ✓ Kernelspeicherbedarf gering, Serverprozesse nur wenn benötigt (
\rightarrowAdaptivität) - ✗ hohe IPC-Kosten von Serverprozessen
- ✗ Kontextwechselkosten von Serverprozessen
- ✗ VMM, Multitasking i.d.R. erforderlich
Beispiel-Betriebssysteme
TinyOS
- Beispiel für sparsame BS im Bereich eingebetteter Systeme
- verbreitete Anwendung: verteilte Sensornetze (WSN)
- ,,TinyOS'' ist ein quelloffenes, BSD-lizenziertes Betriebssystem
- das für drahtlose Geräte mit geringem Stromverbrauch, wie sie in
- Sensornetzwerke, (
\rightarrowSmart Dust) - Allgegenwärtiges Computing,
- Personal Area Networks,
- intelligente Gebäude,
- und intelligente Zähler.
- Sensornetzwerke, (
- Architektur:
- grundsätzlich: monolithisch (Makrokernel) mit Besonderheiten:
- keine klare Trennung zwischen der Implementierung von Anwendungen und BS (wohl aber von deren funktionalen Aufgaben!)
\rightarrowzur Laufzeit: 1 Anwendung + Kernel
- Mechanismen:
- kein Multithreading, keine echte Parallelität
\rightarrowkeine Synchronisation zwischen Tasks\rightarrowkeine Kontextwechsel bei Taskwechsel- Multitasking realisiert durch Programmiermodell
- nicht-präemptives FIFO-Scheduling
- kein Paging$\rightarrow$ keine Seitentabellen, keine MMU
- in Zahlen:
- Kernelgröße: 400 Byte
- Kernelimagegröße: 1 - 4 kByte
- Anwendungsgröße: typisch ca. 15 kB, Datenbankanwendung: 64 kB
- Programmiermodell:
- BS und Anwendung werden als Ganzes übersetzt: statische Optimierungen durch Compilermöglich (Laufzeit, Speicherbedarf)
- Nebenläufigkeit durch ereignisbasierte Kommunikation zw. Anwendung und Kernel
\rightarrowcommand: API-Aufruf, z.B. EA-Operation (vglb. Systemaufruf)\rightarrowevent: Reaktion auf diesen durch Anwendung
- sowohl commands als auch events : asynchron
- Beispieldeklaration:
interface Timer { command result_t start(char type, uint32_t interval); command result_t stop(); event result_t fired(); } interface SendMsg { command result_t send(uint16_t address, uint8_t length, TOS_MsgPtr msg); event result_t sendDone(TOS_MsgPtr msg, result_t success); }
RIOT
[RIOT-Homepage: http://www.riot-os.org]
- ebenfalls sparsames BS,optimiert für anspruchsvollere Anwendungen (breiteres Spektrum)
- ,,RIOT ist ein Open-Source-Mikrokernel-basiertes Betriebssystem, das speziell für die Anforderungen von Internet-of-Things-Geräten (IoT) und anderen eingebetteten Geräten entwickelt wurde.''
- Smartdevices,
- intelligentes Zuhause, intelligente Zähler,
- eingebettete Unterhaltungssysteme
- persönliche Gesundheitsgeräte,
- intelligentes Fahren,
- Geräte zur Verfolgung und Überwachung der Logistik.
- Architektur:
- halbwegs: Mikrokernel
- energiesparendeKernelfunktionalität:
- minimale Algorithmenkomplexität
- vereinfachtes Threadkonzept
\rightarrowkeine Kontextsicherung erforderlich - keine dynamische Speicherallokation
- energiesparende Hardwarezustände vom Scheduler ausgelöst (inaktive CPU)
- Mikrokerneldesign unterstützt komplementäre NFE: Adaptivität, Erweiterbarkeit
- Kosten: IPC (hier gering!)
- Mechanismen:
- Multithreading-Programmiermodell
- modulare Implementierung von Dateisystemen, Scheduler, Netzwerkstack
- in Zahlen:
- Kernelgröße: 1,5 kByte
- Kernelimagegröße: 5 kByte
Implementierung
- ... kann sich jeder mal ansehen (keine spezielle Hardware, beliebige Linux-Distribution, FreeBSD, macOSX mit git ):
$ git clone git://github.com/RIOT-OS/RIOT.git $ cd RIOT $ cd examples/default/ $ make all $ make term - startet interaktive Instanz von RIOT als ein Prozess des Host-BS
- Verzeichnis RIOT: Quellenzur Kompilierung des Kernels, mitgelieferte Bibliotheken, Gerätetreiber, Beispielanwendungen; z.B.:
- RIOT/core/include/thread.h: Threadmodell, Threaddeskriptor
- RIOT/core/include/sched.h,
- RIOT/core/sched.c: Implementierung des (einfachen) Schedulers
- weitere Infos: riot-os.org/api
Robustheit und Verfügbarkeit
Motivation
- allgemein: verlässlichkeitskritischeAnwendungsszenarien
- Forschung in garstiger Umwelt
- Weltraumerkundung
- hochsicherheitskritische Systeme:
- Rechenzentren von Finanzdienstleistern
- Rechenzentren von Cloud-Dienstleistern
- hochverfügbare System:
- all das bereits genannte
- öffentliche Infrastruktur(Strom, Fernwärme, ...)
- HPC (high performancecomputing)
Allgemeine Begriffe
- Verlässlichkeit, Zuverlässigkeit (dependability)
- übergeordnete Eigenschaft eines Systems [ALRL04]
- Fähigkeit, eine Leistungzu erbringen, der man berechtigterweise vertrauen kann
- Taxonomie: umfasst entsprechend Definition die Untereigenschaften
- Verfügbarkeit (availability)
- Robustheit (robustness, reliability
- (Funktions-) Sicherheit (safety)
- Vertraulichkeit (confidentiality)
- Integrität (integrity)
- Wartbarkeit (maintainability) (vgl.: evolutionäre Eigenschaften)
- 1., 4. & 5. auch Untereigenschaften von IT-Sicherheit (security)
\rightarrownicht für alle Anwendungen sind alle Untereigenschaften erforderlich
Robustheitsbegriff
- Teil der primären Untereigenschaften von Verlässlichkeit: Robustheit (robustness, reliability)
- Ausfall: beobachtbare Verminderung der Leistung, die ein System tatsächlich erbringt, gegenüber seiner als korrekt spezifizierten Leistung
- Robustheit: Verlässlichkeit unter Anwesenheit externer Ausfälle (= Ausfälle, deren Ursache außerhalb des betrachteten Systems liegt)
- im Folgenden: kurze Systematik der Ausfälle ...
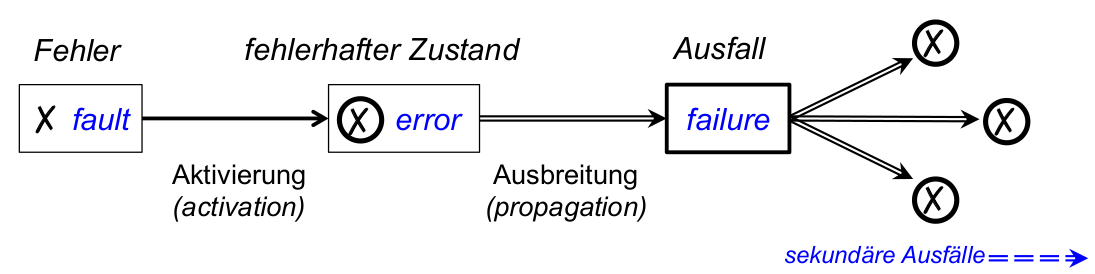
Fehler und Ausfälle ...
- Fehler
\rightarrowfehlerhafter Zustand\rightarrowAusfall - grundlegende Definitionen dieser Begriffe (ausführlich: [ALRL04, AvLR04] ):
- Ausfall (failure): liegt vor, wenn tatsächliche Leistung(en), die ein System erbringt, von als korrekt spezifizierter Leistung abweichen
- fehlerhafter Zustand ( error ): notwendige Ursacheeines Ausfalls (nicht jeder error muss zu failure führen)
- Fehler ( fault ): Ursache für fehlerhaften Systemzustand ( error ), z.B. Programmierfehler
... und ihre Vermeidung
- Umgang mit ...
- faults:
- Korrektheit testen
- Korrektheit beweisen(
\rightarrowformale Verifikation)
- errors:
- Maskierung, Redundanz
- Isolationvon Subsystemen
\rightarrowIsolationsmechanismen
- failures:
- Ausfallverhalten (neben korrektem Verhalten) spezifizieren
- Ausfälle zur Laufzeit erkennen und Folgen beheben, abschwächen...
\rightarrowMicro-Reboots
- faults:
Fehlerhafter Zustand
- interner und externer Zustand (internal & external state)
- externer Zustand (einer Systems oder Subsystems): der Teil des Gesamtzustands, der an externer Schnittstelle (also für das umgebende (Sub-) System) sichtbar wird
- interner Zustand: restlicher Teilzustand
- (tatsächlich) erbrachte Leistung: zeitliche Folge externer Zustände
- Beispiele für das System ( Betriebssystem-) Kernel :
- Subsysteme: Dateisystem, Scheduler, E/A, IPC, ..., Gerätetreiber
- fault : Programmierfehler im Gerätetreiber
- externer Zustand des Treibers (oder des Dateisystems, Schedulers, E/A, IPC, ...) ⊂ interner Zustand des Kernels
Fehlerausbreitung und (externer) Ausfall
- Wirkungskette:
-[X] Treiber-Programmierfehler (fault)
-[X] fehlerhafter interner Zustand des Treibers (error)
- Ausbreitung dieses Fehlers ( failure des Treibers)
- = fehlerhafter externer Zustand des Treibers
- = fehlerhafter interner Zustand des Kernels( error )
- = Kernelausfall!( failure )
- Auswirkung: fehlerhafter interner Zustand eines weiteren Kernel-Subsystems (z.B. error des Dateisystems)
\rightarrowRobustheit: Isolationsmechanismen
Isolationsmechanismen
- im Folgenden: Isolationsmechanismen für robuste Betriebssysteme
- durch strukturierte Programmierung
- durch Adressraumisolation
- es gibt noch mehr: Isolationsmechanismen für sichere Betriebssysteme
- all die obigen...
- durch kryptografische Hardwareunterstützung: Enclaves
- durch streng typisierte Sprachen und managed code
- durch isolierte Laufzeitumgebungen: Virtualisierung
Strukturierte Programmierung
Monolithisches BS... in historischer Reinform:
- Anwendungen
- Kernel
- gesamte BS-Funktionalität
- programmiert als Sammlung von Prozeduren
- jede darf jede davon aufrufen
- keine Modularisierung
- keine definierten internen Schnittstellen
Monolithisches Prinzip
- Ziel: Isolation zwischen Anwendungen und Betriebssystem
- Mechanismus: Prozessor-Privilegierungsebenen ( user space und kernel space )
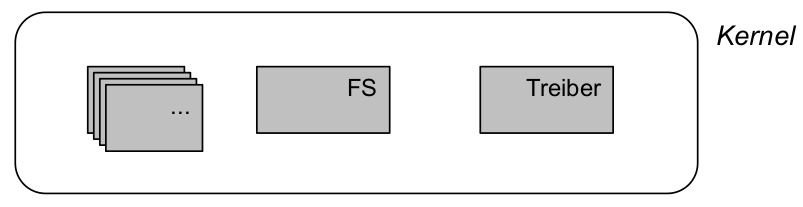
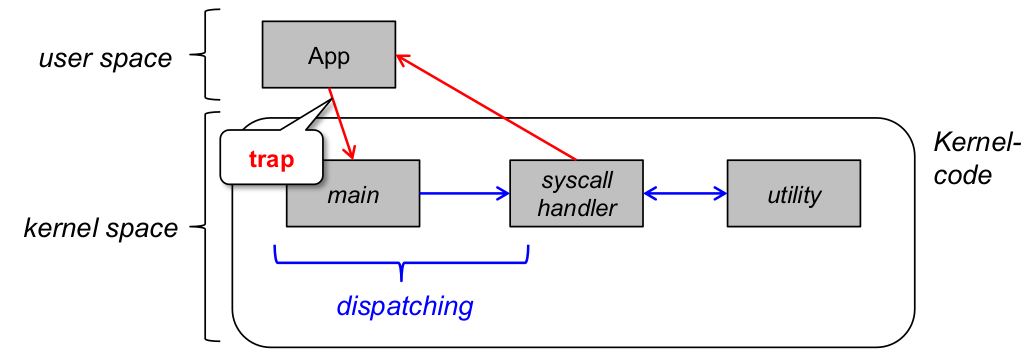
- Konsequenz für Strukturierung des Kernels: Es gibt keine Strukturierung des Kernels ...
- ... jedenfalls fast: Ablauf eines Systemaufrufs (Erinnerung)

Strukturierte Makrokernarchitektur
- Resultat: schwach strukturierter (monolithischer) Makrokernel
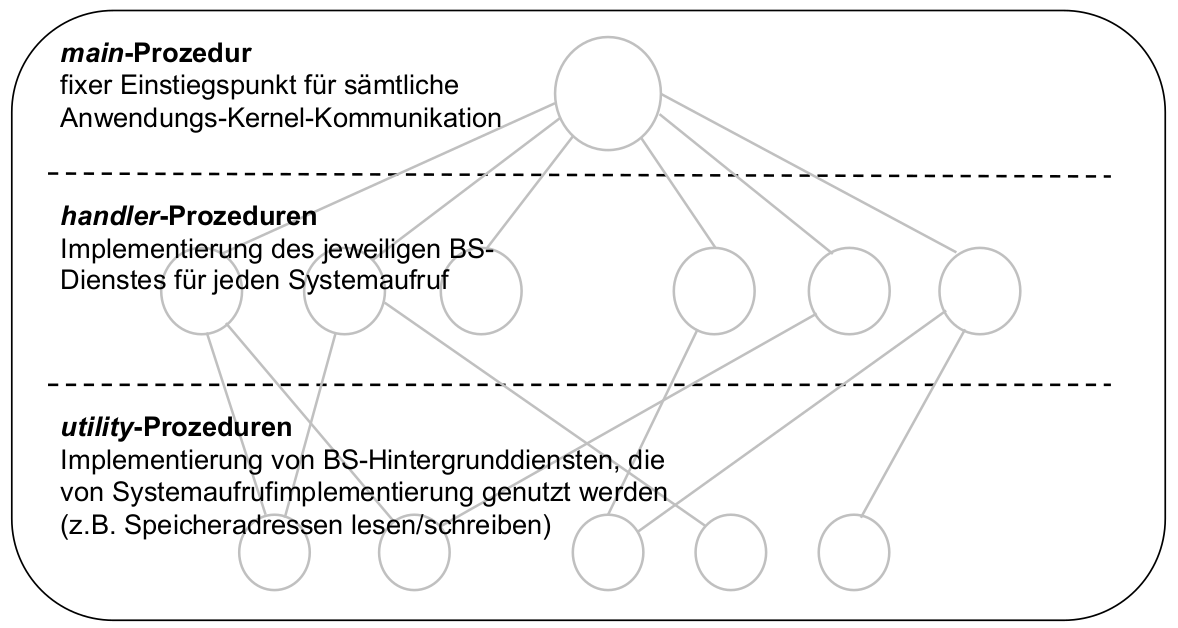
- nach [TaWo05], S. 45
- Weiterentwicklung:
- Schichtendifferenzierung ( layered operating system )
- Modularisierung (Bsp.: Linux-Kernel)
Kernelcode VFS IPC, Dateisystem Scheduler, VMM Dispatcher, Gerätetreiber - Modularer Makrokernel:
- alle Kernelfunktionen in Moduleunterteilt (z.B. verschiedene Dateisystemtypen)
\rightarrowErweiterbarkeit, Wartbarkeit, Portierbarkeit - klar definierte Modulschnittstellen(z.B. virtualfilesystem, VFS )
- Module zur Kernellaufzeit dynamisch einbindbar (
\rightarrowAdaptivität)
Fehlerausbreitung beim Makrokernel
- strukturierte Programmierung:
- ✓ Wartbarkeit
- ✓ Portierbarkeit
- ✓ Erweiterbarkeit
- O (begrenzt) Adaptivität
- O (begrenzt) Schutz gegen statische Programmierfehler: nur durch Compiler (z.B. C private, public)
- ✗ kein Schutz gegen dynamische Fehler
\rightarrowRobustheit...?- nächstes Ziel: Schutz gegen Laufzeitfehler...
\rightarrowLaufzeitmechanismen
Adressraumisolation
- zur Erinnerung: private virtuelle Adressräume zweier Tasks (
i\not= j) - private virtuelle vs. physischer Adresse
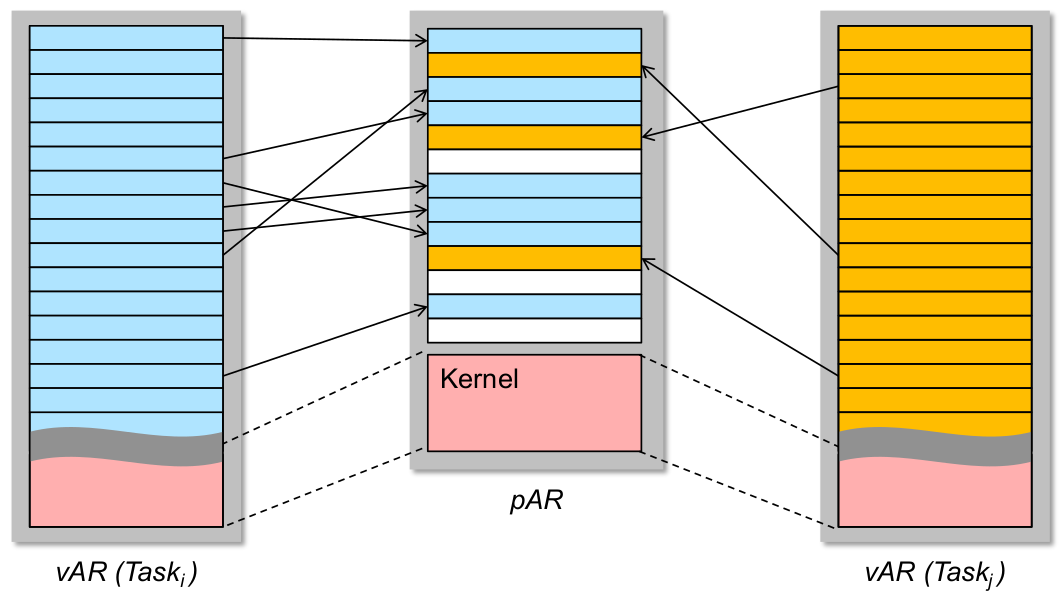
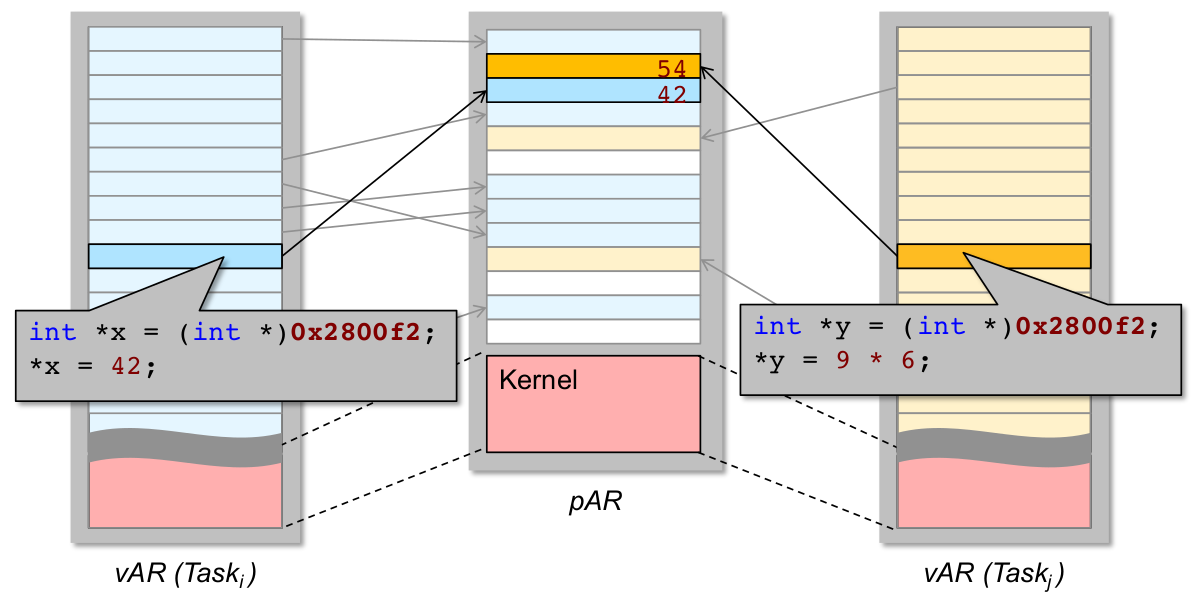
Private virtuelle Adressräume und Fehlerausbreitung
- korrekte private vAR ~ kollisionsfreie Seitenabbildung!
- Magie in Hardware: MMU (BS steuert und verwaltet...)
- Robustheit: Was haben wir von privaten vAR?
- ✓ nichtvertrauenswürdiger (i.S.v. potenziell nicht korrekter) Code kann keine beliebigen physischen Adressen schreiben (er erreicht sie ja nicht mal...)
- ✓ Kommunikation zwischen nvw. Code (z.B. Anwendungstasks) muss durch IPC-Mechanismen explizit hergestellt werden (u.U. auch shared memory)
\rightarrowÜberwachung und Validierung zur Laufzeit möglich
- ✓ Kontrollfluss begrenzen: Funktionsaufrufe können i.A. (Ausnahme: RPC) keine AR-Grenzen überschreiten
\rightarrowBS-Zugriffssteuerungkann nicht durch Taskfehler ausgehebelt werden\rightarrowunabsichtliche Terminierungsfehler(unendliche Rekursion) erschwert ...
Was das für den Kernel bedeutet
- private virtuelle Adressräume
- gibt es schon so lange wie VMM
- gab es lange nur auf Anwendungsebene
\rightarrowkeine Isolation zwischen Fehlern innerhalb des Kernels!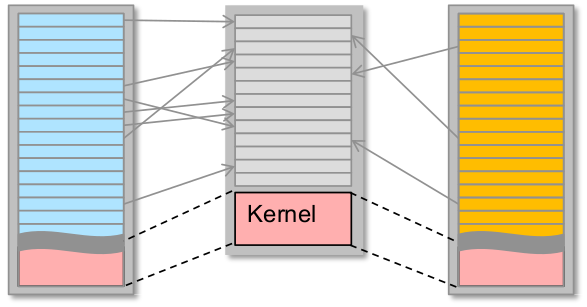
- nächstes Ziel: Schutz gegen Kernelfehler (Gerätetreiber)...
\rightarrowBS-Architektur
Mikrokernelarchitektur
- Fortschritt ggü. Makrokernel:
- Strukturierungskonzept:
- strenger durchgesetzt durch konsequente Isolation voneinander unabhängiger Kernel-Subsysteme
- zur Laufzeit durchgesetzt
\rightarrowReaktion auf fehlerhafte Zustände möglich!
- zusätzlich zu vertikaler Strukturierung des Kernels: horizontale Strukturierungeingeführt
\rightarrowfunktionale Einheiten: vertikal (Schichten)\rightarrowisolierteEinheiten: horizontal (private vAR)
- Strukturierungskonzept:
- Idee:
- Kernel (alle BS-Funktionalität)
\rightarrowμKernel (minimale BS-Funktionalität) - Rest (insbes. Treiber): ,,gewöhnliche'' Anwendungsprozesse mit Adressraumisolation
- Kommunikation: botschaftenbasierteIPC (auch client-server operating system )
- Nomenklatur: Mikrokernelund Serverprozesse
- Kernel (alle BS-Funktionalität)
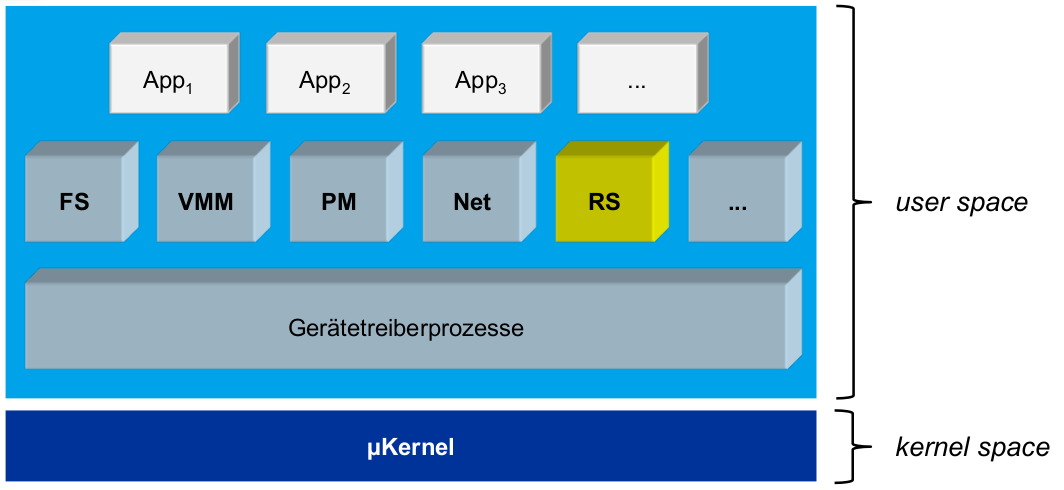
Modularer Makrokernel vs. Mikrokernel
![Abb. nach [Heis19]](/wieerwill/Informatik/media/branch/master/Assets/AdvancedOperatingSystems-modularer-makrokernel.png)
- minimale Kernelfunktionalität:
- keine Dienste, nur allgemeine Schnittstellenfür diese
- keine Strategien, nur grundlegende Mechanismenzur Ressourcenverwaltung
- neues Problem: minimales Mikrokerneldesign
- ,,Wir haben 100 Leute gefragt...'': Wie entscheide ich das?
![Abb. nach [Heis19]](/wieerwill/Informatik/media/branch/master/Assets/AdvancedOperatingSystems-modularer-makrokernel-2.png)
- Ablauf eines Systemaufrufs
- schwarz: unprivilegierteInstruktionen
- blau:privilegierte Instruktionen
- rot:Übergang zwischen beidem (μKern
\rightarrowKontextwechsel!)
Robustheit von Mikrokernen
- = Gewinn durch Adressraumisolation innerhalb des Kernels
- ✓ kein nichtvertrauenswürdiger Code im kernelspace , der dort beliebige physische Adressen manipulieren kann
- ✓ Kommunikation zwischen nvw. Code (nicht zur zwischen Anwendungstasks)muss durch IPC explizit hergestellt werden
\rightarrowÜberwachung und Validierung zur Laufzeit - ✓ Kontrollfluss begrenzen: Zugriffssteuerung auch zwischen Serverprozessen, zur Laufzeit unabhängiges Teilmanagement von Code (Kernelcode) möglich (z.B.: Nichtterminierung erkennen)
- Neu:
- ✓ nvw. BS-Code muss nicht mehr im kernelspace (höchste Prozessorprivilegierung) laufen
- ✓ verbleibender Kernel (dessen Korrektheit wir annehmen): klein, funktional weniger komplex, leichter zu entwickeln, zu testen, evtl. formal zu verifizieren
- ✓ daneben: Adaptivitätdurch konsequentere Modularisierung des Kernels gesteigert
Mach
- Mikrokernel-Design: Erster Versuch
- Carnegie Mellon University (CMU), School of Computer Science 1985 - 1994
- ein wenig Historie
- UNIX (Bell Labs) - K. Thompson, D. Ritchie
- BSD (U Berkeley) - W. Joy
- System V - W. Joy
- Mach (CMU) - R. Rashid
- MINIX - A. Tanenbaum
- NeXTSTEP (NeXT) - S. Jobs
- Linux - L. Torvalds
- GNU Hurd (FSF) - R. Stallman
- Mac OS X (Apple) - S. Jobs
Mach: Ziele
Entstehung
- Grundlage:
- 1975: Aleph(BS des ,,Rochester Intelligent Gateway''), U Rochester
- 1979/81: Accent (verteiltes BS), CMU
- gefördert durch militärische Geldgeber:
- DARPA: Defense AdvancedResearch Projects Agency
- SCI: Strategic Computing Initiative
Ziele
- Mach 3.0 (Richard Rashid, 1989): einer der ersten praktisch nutzbaren μKerne
- Ziel: API-Emulation(≠ Virtualisierung!)von UNIX und -Derivaten auf unterschiedlichen Prozessorarchitekturen
- mehrere unterschiedliche Emulatoren gleichzeitig lauffähig
- Emulation außerhalb des Kernels
- jeder Emulator:
- Komponente im Adressraum des Applikationsprogramms
- 1...n Server, die unabhängig von Applikationsprogramm laufen
Mach-Server zur Emulation
![Abb.: [TaBo15]](/wieerwill/Informatik/media/branch/master/Assets/AdvancedOperatingSystems-mach-server.png)
- Emulation von UNIX-Systemen mittels Mach-Serverprozessen
μKernel-Funktionen
- Prozessverwaltung
- Speicherverwaltung
- IPC-und E/A-Dienste, einschließlich Gerätetreiber
unterstützte Abstraktionen (\rightarrow API, Systemaufrufe):
- Prozesse
- Threads
- Speicherobjekte
- Ports (generisches, ortstransparentes Adressierungskonzept; vgl. UNIX ,,everything is a file'')
- Botschaften
- ... (sekundäre, von den obigen genutzte Abstraktionen)
Architektur
-
-
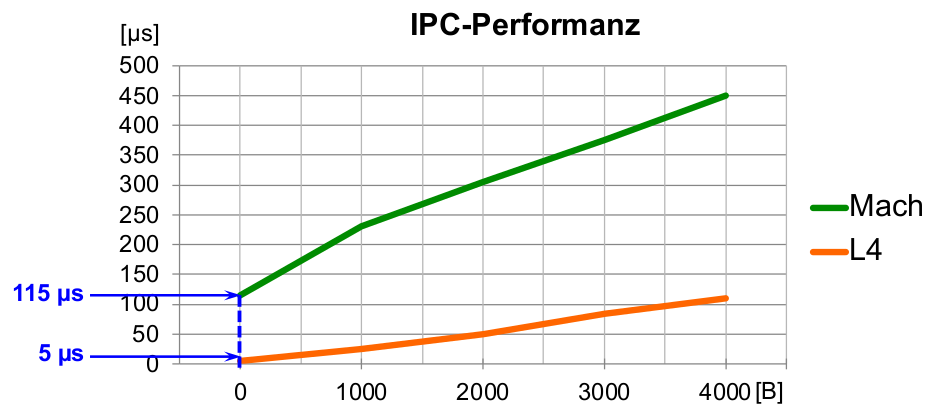
Systemaufrufkosten:
- IPC-Benchmark (1995): i486 Prozessor, 50 MHz
- Messung mit verschiedenen Botschaftenlängen( x - Werte)
- ohne Nutzdaten (0 Byte Botschaftenlänge): 115 μs (Tendenz unfreundlich ...)
-
Bewertung aus heutiger Sicht:
- funktional komplex
- 153 Systemaufrufe
- mehrere Schnittstellen, parallele Implementierungen für eine Funktion
\rightarrowAdaptivität (Auswahl durch Programmierer)
-
Fazit:
- zukunftsweisender Ansatz
- langsame und ineffiziente Implementierung
Lessons Learned
- erster Versuch:
- Idee des Mikrokernelsbekannt
- Umsetzung: Designkriterienweitgehend unbekannt
- Folgen für Performanz und Programmierkomfort: [Heis19]
- ✗ ,,complex''
- ✗ ,,inflexible''
- ✗ ,,slow''
- wir wissen etwas über Kosten: IPC-Performanz, Kernelabstraktionen
- wir wissen noch nichts über guten μKern-Funktionsumfangund gute Schnittstellen...
\rightarrownächstes Ziel!
L4
- Made in Germany:
- Jochen Liedtke (GMD, ,,Gesellschaft für Mathematik und Datenverarbeitung''), Betriebssystemgruppe (u.a.): J. Liedtke, H. Härtig, W. E. Kühnhauser
- Symposium on Operating Systems Principles 1995 (SOSP '95): ,,On μ-Kernel Construction'' [Lied95]
- Analyse des Mach-Kernels:
- falsche Abstraktionen
- unperformanteKernelimplementierung
- prozessorunabhängige Implementierung
- Letzteres: effizienzschädliche Eigenschaft eines Mikrokernels
- Neuimplementierung eines (konzeptionell sauberen!) μ-Kerns kaum teurer als Portierung auf andere Prozessorarchitektur
L3 und L4
- Mikrokerne der 2. Generation
- zunächst L3, insbesondere Nachfolger L4: erste Mikrokerne der 2. Generation
- vollständige Überarbeitung des Mikrokernkonzepts: wesentliche Probleme der 1. Generation (z.B. Mach) vermieden
- Bsp.: durchschnittliche Performanz von User-Mode IPC in L3 ggü. Mach: Faktor 22 zugunsten L3
- heute: verschiedene Weiterentwicklungen von L4 (bezeichnet heute Familie ähnlicher Mikrokerne)
First generation Second Generation Third generation Eg Mach [87] Eg L4 [95] seL4 [09] 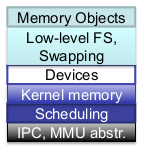

180 syscalls ~7 syscalls ~3 syscalls 100 kLOC ~10 kLOC 9 kLOC 100 \mu sIPC~1 \mu sIPC0,2-1 \mu sIPC
Mikrokernel-Designprinzipien
- Was gehört in einen Mikrokern?
- Liedtke: Unterscheidung zwischen Konzepten und deren Implementierung
- bestimmende Anforderungen an beide:
- Konzeptsicht
\rightarrowFunktionalität, - Implementierungssicht
\rightarrowPerformanz
- Konzeptsicht
\rightarrow1. μKernel-Generation: Konzept durch Performanzentscheidungen aufgeweicht\rightarrowEffekt in der Praxis genau gegenteilig: schlechte (IPC-) Performanz!
,,The determining criterion used is functionality, not performance. More precisely, a concept is tolerated inside the μ-kernel only if moving it outside the kernel, i.e. permitting competing implementations, would prevent the implementation of the systems‘s required functionality .'' [Jochen Liedtke]
Designprinzipien für Mikrokernel-Konzept:
\rightarrowAnnahmen hinsichtlich der funktionalen Anforderungen:
- System interaktive und nicht vollständig vertrauenswürdige Applikationen unterstützen (
\rightarrowHW-Schutz, -Multiplexing), - Hardware mit virtueller Speicherverwaltung und Paging
Designprinzipien:
- Autonomie: ,,Ein Subsystem (Server)muss so implementiert werden können, dass es von keinem anderen Subsystem gestört oder korrumpiert werden kann.''
- Integrität: ,,Subsystem (Server)
S_1muss sich auf Garantien vonS_2verlassen können. D.h. beide Subsysteme müssen miteinander kommunizieren können, ohne dass ein drittes Subsystem diese Kommunikation stören, fälschen oder abhören kann.''
L4: Speicherabstraktion
- Adressraum: Abbildung, die jede virtuelle Seite auf einen physischen Seitenrahmen abbildet oder als ,,nicht zugreifbar'' markiert
- Implementierung über Seitentabellen, unterstützt durch MMU-Hardware
- Aufgabe des Mikrokernels (als gemeinsame obligatorische Schicht aller Subsysteme): muss Hardware-Konzept des Adressraums verbergen und durch eigenes Adressraum-Konzept überlagern (sonst Implementierung von VMM-Mechanismen durch Server unmöglich)
- Mikrokernel-Konzept des Adressraums:
- muss Implementierung von beliebigen virtuellen Speicherverwaltungs-und -schutzkonzepten oberhalb des Mikrokernels (d.h. in den Subsystemen) erlauben
- sollte einfach und dem Hardware-Konzept ähnlich sein
- Idee: abstrakte Speicherverwaltung
- rekursive Konstruktion und Verwaltung der Adressräume auf Benutzer-(Server-)Ebene
- Mikrokernel stellt dafür genau drei Operationen bereit:
- grant(x) - Server
Süberträgt Seitexseines AR in AR von EmpfängerS‘ - map(x) - Server
Sbildet Seitexseines AR in AR von EmpfängerS‘ab - flush(x) - Server
Sentfernt (flusht) Seite x seines AR aus allen fremden AR
- grant(x) - Server
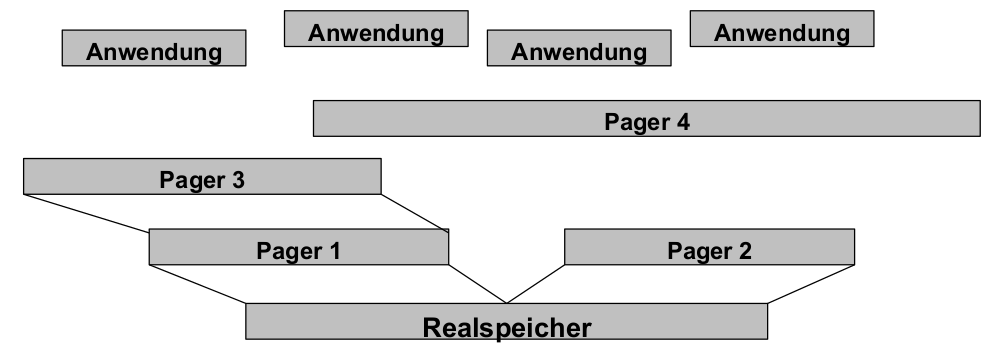
Hierarchische Adressräume
- Rekursive Konstruktion der Adressraumhierarchie
- Server und Anwendungenkönnen damit ihren Klienten Seiten des eigenen Adressraumes zur Verfügung stellen
- Realspeicher: Ur-Adressraum, vom μKernel verwaltet
- Speicherverwaltung(en), Paging usw.: vollständig außerhalb des μ-Kernels realisiert
L4: Threadabstraktion
- Thread
- innerhalb eines Adressraumesablaufende Aktivität
\rightarrowAdressraumzuordnung ist essenziell für Threadkonzept (Code + Daten)- Bindung an Adressraum: dynamisch oder fest
- Änderung einer dynamischen Zuordnung: darf nur unter vertrauenswürdiger Kontrolle erfolgen (sonst: fremde Adressräume les- und korrumpierbar)
- Designentscheidung
\rightarrowAutonomieprinzip\rightarrowKonsequenz: Adressraumisolation\rightarrowentscheidender Grund zur Realisierung des Thread-Konzepts innerhalb des Mikrokernels
IPC
- Interprozess-Kommunikation
- Kommunikation über Adressraumgrenzen: vertrauenswürdig kontrollierte Aufhebung der Isolation
\rightarrowessenziell für (sinnvolles) Multitasking und -threading
- Designentscheidung
\rightarrowIntegritätsprinzip\rightarrowwir haben schon: vertrauenswürdige Adressraumisolation im μKernel\rightarrowgrundlegendes IPC-Konzepts innerhalb des Mikrokernels (flexibel und dynamisch durch Server erweiterbar, analog Adressraumhierarchie)
Identifikatoren
- Thread-und Ressourcenbezeichner
- müssen vertrauenswürdig vergeben (authentisch und i.A. persistent) und verwaltet(eindeutig und korrekt referenzierbar)werden
\rightarrowessenziell für (sinnvolles) Multitasking und -threading\rightarrowessenziell für vertrauenswürdige Kernel-und Server-Schnittstellen
- Designentscheidung
\rightarrowIntegritätsprinzip\rightarrowID-Konzept innerhalb des Mikrokernels (wiederum: durch Server erweiterbar)
Lessons Learned
- Ein minimaler Mikrokernel
- soll Minimalmenge an geeigneten Abstraktionenzur Verfügung stellen:
- flexibel genug, um Implementierung beliebiger Betriebssysteme zu ermöglichen
- Nutzung umfangreicher Mengeverschiedener Hardware-Plattformen
- Geeignete, funktional minimale Mechanismen im μKern:
- Adressraum mit map-, flush-, grant-Operation
- Threadsinklusive IPC
- eindeutige Identifikatoren
- Wahl der geeigneten Abstraktionen:
- kritischfür Verifizierbarkeit (
\rightarrowRobustheit), Adaptivität und optimierte Performanz des Mikrokerns
- kritischfür Verifizierbarkeit (
- Bisherigen μ-Kernel-Abstraktionskonzepte:
- ungeeignete
- zu viele
- zu spezialisierte u. inflexible Abstraktionen
- Konsequenzen für Mikrokernel-Implementierung
- müssen für jeden Prozessortyp neu implementiert werden
- sind deshalb prinzipiell nicht portierbar
\rightarrowL3-und L4-Prototypen by J. Liedtke: 99% Assemblercode
- innerhalb eines Mikrokernels sind
- grundlegende Implementierungsentscheidungen
- meiste Algorithmen u. Datenstrukturen
- von Prozessorhardware abhängig
- Fazit:
- Mikrokernelmit akzeptabler Performanz: hardwarespezifische Implementierung minimalerforderlicher, vom Prozessortyp unabhängiger Abstraktionen
Heutige Bedeutung
- nach Tod von J. Liedtke (2001) auf Basis von L4 zahlreiche moderne BS
- L4 heute: Spezifikation eines Mikrokernels (nicht Implementierung)

- Einige Weiterentwicklungen:
- TU Dresden (Hermann Härtig): Neuimplementierung in C++ (L4/Fiasco), Basis des Echtzeit-Betriebssystems DROPS, der VirtualisierungsplattformNOVA (genauer: Hypervisor) und des adaptiven BS-Kernels Fiasco.OC
- University ofNew South Wales (UNSW), Australien (Gernot Heiser):
- Implementierung von L4 auf verschiedenen 64 - Bit-Plattformen, bekannt als L4/MIPS, L4/Alpha
- Implementierung in C (Wartbarkeit, Performanz)
- Mit L4Ka::Pistachio bisher schnellste Implementierung von botschaftenbasierterIPC (2005: 36 Zyklen auf Itanium-Architektur)
- seit 2009: seL4, erster formal verifizierter BS-Kernel (d.h. mathematisch bewiesen, dass Implementierung funktional korrekt ist und nachweislich keinen Entwurfsfehler enthält)
Zwischenfazit
- Begrenzung von Fehlerausbreitung (
\rightarrowFolgen von errors ): - konsequent modularisierte Architektur aus Subsystemen
- Isolationsmechanismen zwischen Subsystemen
- Konsequenzen für BS-Kernel:
- statische Isolation auf Quellcodeebene
\rightarrowstrukturierte Programmierung - dynamische Isolation zur Laufzeit
\rightarrowprivate virtuelle Adressräume - Architektur, welche diese Mechanismen komponiert: Mikrokernel
- Was haben wir gewonnen?
- ✓ Adressraumisolation für sämtlichen nichtvertrauenswürdigen Code
- ✓ keine privilegierten Instruktionen in nvw. Code (Serverprozesse)
- ✓ geringe Größe (potenziell: Verifizierbarkeit) des Kernels
- ✓ neben Robustheit: Modularitätund Adaptivitätdes Kernels
- Und was noch nicht?
- ✗ Behandlung von Ausfällen (
\rightarrowabstürzende Gerätetreiber ...)
- ✗ Behandlung von Ausfällen (
3.5 Micro-Reboots
- Beobachtungen am Ausfallverhalten von BS:
- Kernelfehler sind (potenziell) fatal für gesamtes System
- Anwendungsfehler sind es nicht
\rightarrowkleiner Kernel = geringeres Risiko von Systemausfällen\rightarrowdurch BS-Code in Serverprozessen: verbleibendes Risiko unabhängiger Teilausfälle von BS-Funktionalität (z.B. FS, Treiberprozesse, GUI, ...)- Ergänzung zu Isolationsmechanismen:
- Mechanismen zur Behandlung von Subsystem-Ausfällen
- = Mechanismen zur Behandlung Anwendungs-, Server- und Gerätetreiberfehlen
\rightarrowMicro-Reboots
Ansatz
- wir haben:
- kleinen, ergo vertrauenswürdigen (als fehlerfrei angenommenen)μKernel
- BS-Funktionalität in bedingt vertrauenswürdigen Serverprozessen (kontrollierbare, aber wesentlich größere Codebasis)
- Gerätetreiber und Anwendungen in nicht vertrauenswürdigen Prozessen (nicht kontrollierbare Codebasis)
- wir wollen:
- Systemausfälle verhindern durch Vermeidung von errors im Kernel
\rightarrowhöchste Priorität - Treiber-und Serverausfälle minimieren durch Verbergen ihrer Auswirkungen
\rightarrownachgeordnete Priorität (Best-Effort-Prinzip) - Idee:
- Systemausfälle
\rightarrowμKernel - Treiber-und Serverausfälle
\rightarrowNeustart durch spezialisierten Serverprozess
- Systemausfälle
Beispiel: Ethernet-Treiberausfall
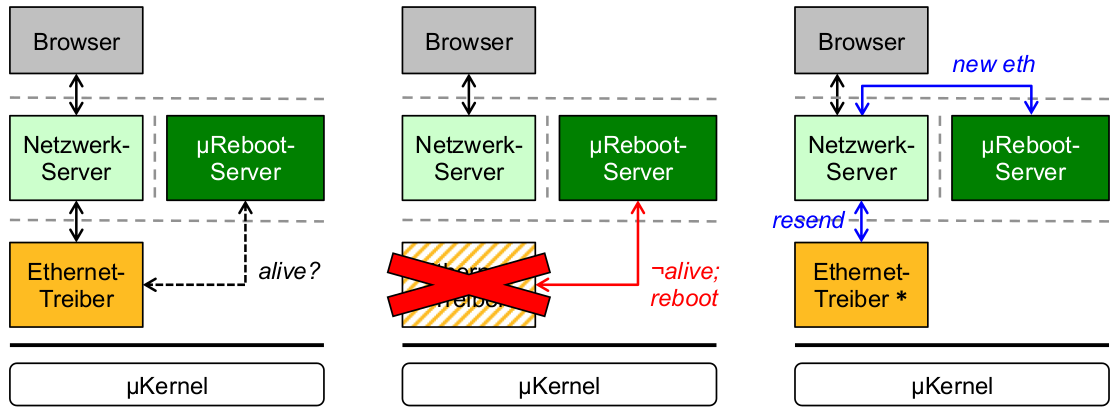
- schwarz: ausfallfreie Kommunikation
- rot: Ausfall und Behandlung
- blau: Wiederherstellung nach Ausfall
Beispiel: Dateisystem-Serverausfall
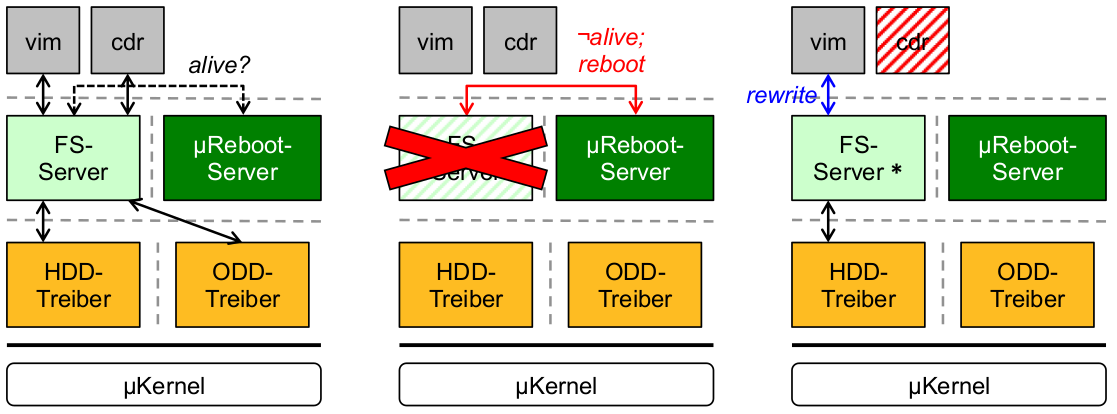
- schwarz: ausfallfreie Kommunikation
- rot: Ausfall und Behandlung
- blau: Wiederherstellung nach Ausfall
Beispiel-Betriebssystem: MINIX
- Ziele:
- robustes Betriebssystems
\rightarrowSchutz gegen Sichtbarwerden von Fehlern(= Ausfälle) für Nutzer- Fokus auf Anwendungsdomänen: Endanwender-Einzelplatzrechner (Desktop, Laptop, Smart*) und eingebettete Systeme
- Anliegen: Robustheit > Verständlichkeit > geringer HW-Bedarf
- aktuelle Version: MINIX 3.3.0
Architektur
- Kommunikationsschnittstellen ...
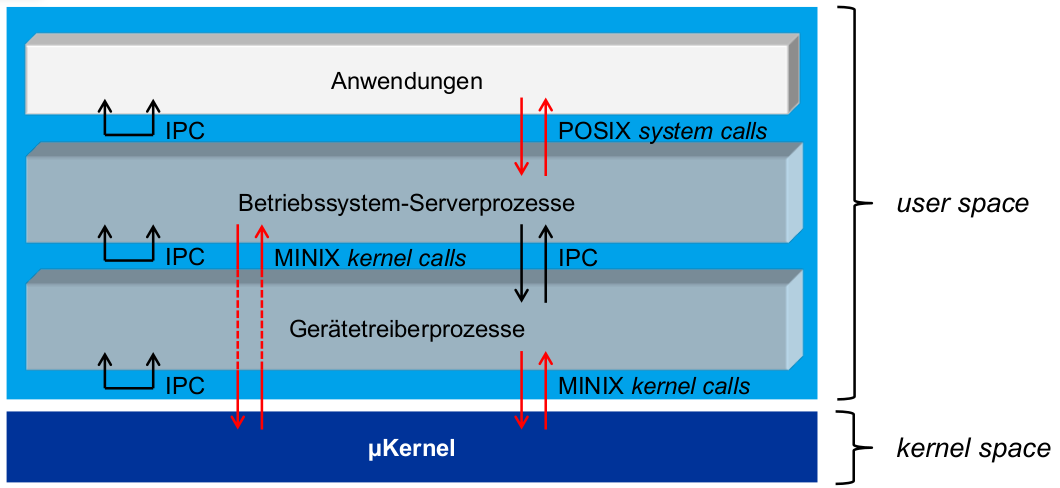
- ... für Anwendungen (weiß): Systemaufrufe im POSIX-Standard
- ... für Serverprozesse (grau):
- untereinander: IPC (botschaftenbasiert)
- mit Kernel: spezielle MINIX-API (kernel calls), für Anwendungsprozesse gesperrt
- Betriebssystem-Serverprozesse:
- Dateisystem (FS)
- Prozessmanagement (PM)
- Netzwerkmanagement (Net)
- Reincarnation Server (RS)
\rightarrowMicro-Reboots jeglicher Serverprozesse - (u. a.) ...
- Kernelprozesse:
- systemtask
- clocktask
Reincarnation Server
- Implementierungstechnik für Micro-Reboots:
- Prozesse zum Systemstart (
\rightarrowKernel Image): system, clock, init, rs- system, clock: Kernelprogramm
- init: Bootstrapping (Initialisierung von rs und anderer BS-Serverprozesse), Fork der Login-Shell (und damit sämtlicher Anwendungsprozesse)
- rs: Fork sämtlicher BS-Serverprozesse, einschließlich Gerätetreiber
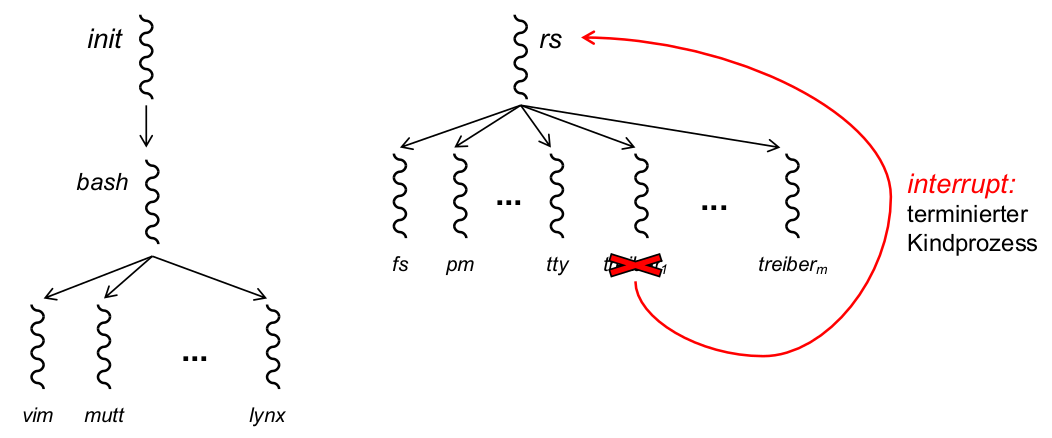
MINIX: Ausprobieren
Verfügbarkeit
- komplementäre NFE zu Robustheit: Verfügbarkeit ( availability )
- Zur Erinnerung: Untereigenschaften von Verlässlichkeit
- Verfügbarkeit (availability)
- Robustheit (robustness, reliability)
- Beziehung:
- Verbesserung von Robustheit
\RightarrowVerbesserung von Verfügbarkeit - Robustheitsmaßnahmen hinreichend , nicht notwendig (hochverfügbare Systeme können sehr wohl von Ausfällen betroffen sein...)
- Verbesserung von Robustheit
- eine weitere komplementäre NFE:
- Robustheit
\RightarrowSicherheit (security)
- Robustheit
Allgemeine Definition: Der Grad, zu welchem ein System oder eine Komponente funktionsfähig und zugänglich (erreichbar) ist,wann immer seine Nutzung erforderlichist. (IEEE)
genauer quantifiziert:
- Der Anteil an Laufzeit eines Systems, in dem dieses seine spezifizierte Leistung erbringt.
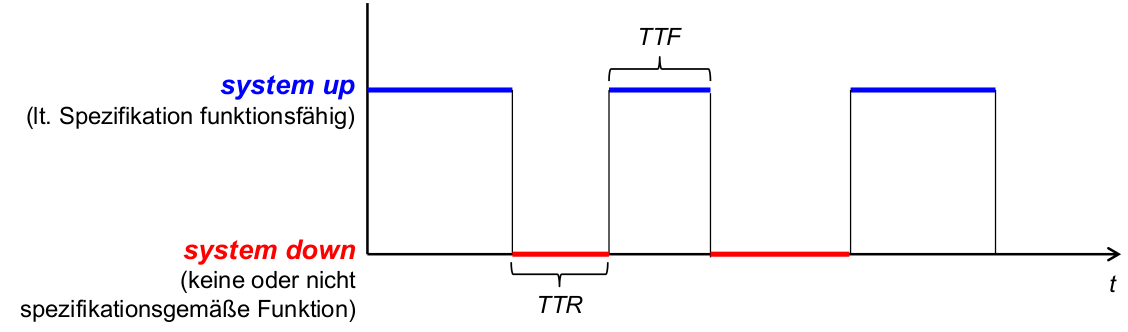
- Availability= Total Uptime/ Total Lifetime= MTTF / (MTTF + MTTR)
- MTTR: Mean Time to Recovery ... Erwartungswert für TTR
- MTTF: Mean Time to Failure ... Erwartungswert für TTF
- einige Verfügbarkeitsklassen:
Verfügbarkeit Ausfallzeit pro Jahr Ausfallzeit pro Woche 90% > 1 Monat ca. 17 Stunden 99% ca. 4 Tage ca. 2 Stunden 99,9% ca. 9 Stunden ca. 10 Minuten 99,99% ca. 1 Stunde ca. 1 Minute 99,999% ca. 5 Minuten ca. 6 Sekunden 99,9999% ca. 2 Sekunden << 1 Sekunde - Hochverfügbarkeitsbereich (gefeierte ,,five nines'' availability)
- Maßnahmen:
- Robustheitsmaßnahmen
- Redundanz
- Ausfallmanagement
QNX Neutrino: Hochverfügbares Echtzeit-BS
Überblick QNX:
- Mikrokern-Betriebssystem
- primäres Einsatzfeld: eingebettete Systeme, z.B. Automobilbau
- Mikrokernarchitektur mit Adressraumisolation für Gerätetreiber
- (begrenzt) dynamische Micro-Rebootsmöglich
\rightarrowMaximierung der Uptime des Gesamtsystems
Hochverfügbarkeitsmechanismen:
- ,,High-Avalability-Manager'': Laufzeit-Monitor, der Systemdienste oder Anwendungsprozesse überwacht und neustartet
\rightarrowμReboot-Server - ,,High-Availability-Client-Libraries'': Funktionen zur transparenten automatischen Reboot für ausgefallene Server-Verbindungen
Sicherheit
Motivation
Medienberichte zu IT-Sicherheitsvorfällen:
- 27.-28.11.2016: Ausfälle von über 900.000 Kundenanschlüssen der Deutschen Telekom
- Bundesamt für Sicherheit in der Informationstechnik (BSI): weltweiter Angriff auf ausgewählte Fernverwaltungsports von DSL-Routern, um angegriffene Geräte mit Schadsoftware zu infizieren
- Angreiferziel: Missbrauch der Hardware für eigentliche Angriffe (Botnet)
- 15.05.-06.06.2019: Ransomware-Angriff zur Erpressung der Heise Verlagsgruppe
- Infektion eines Rechners im lokalen Netz durch Malware in eMail-Anhang (Trojaner)
- Täuschung des Nutzers: Schadcode mit Administratorrechten ausgeführt (Spezialfall von Malware: Root Kit)
- Malwareziel: Verschlüsselungvon Nutzerdaten
- Angreiferziel: Erspressungvon Lösegeld für Entschlüsselung
Was sichere Betriebssysteme erreichen können ... und was nicht: youtube
Terminologie
Achtung zwei unterschiedliche ,,Sicherheiten''
- Security (IT-Sicherheit, Informationssicherheit)
- Ziel: Schutz des Rechnersystems
- hier besprochen
- Systemsicherheit
- Safety (Funktionale Sicherheit, Betriebssicherheit)
- Ziel: Schutz vor einem Rechnersystem
- an dieser Stelle nicht besprochen
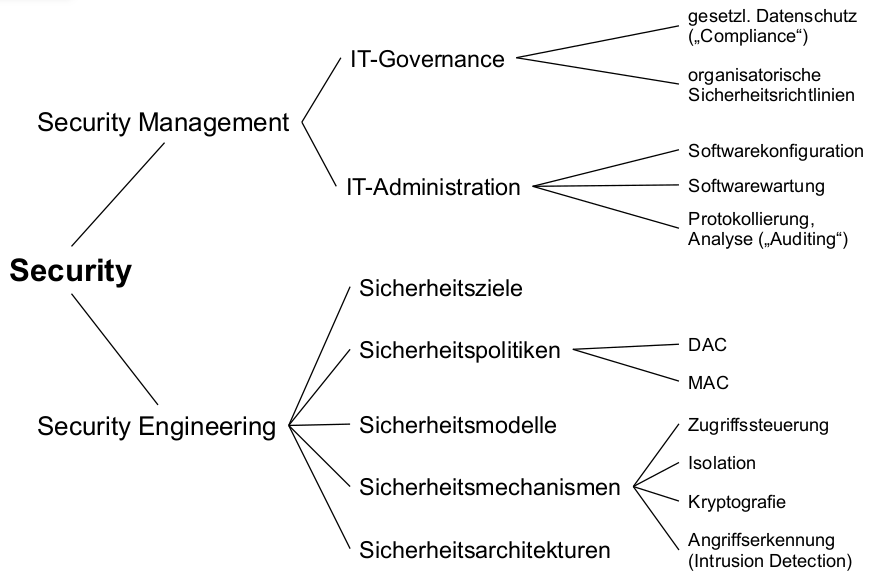
Eine (unvollständige) Taxonomie:
Sicherheitsziele
Allgemeines Ziel von IT-Sicherheit i.S.v. Security ... ein Rechnersystem sicher zu machen gegen Schäden durch zielgerichtete Angriffe, insbesondere in Bezug auf die Informationen, die in solchen Systemen gespeichert, verarbeitet und übertragen werden. (Programme sind somit ebenfalls als Informationen zu verstehen.)
Cave! Insbesondere für Sicherheitsziele gilt: Daten \not= Informationen
Sicherheitsziele: sukzessive Konkretisierungen dieser Allgemeinformel hinsichtlich anwendungsspezifischer Anforderungen
Abstrakte Ziele:
- Vertraulichkeit (Confidentiality)
- Integrität (Integrity)
- Verfügbarkeit (Availability)
- Authentizität (Authenticity)
- Verbindlichkeit = Nichtabstreitbarkeit (Non-repudiability)
Abstrakte Ziele dienen zur Ableitung konkreter Sicherheitsziele. Wir definieren sie als Eigenschaften von gespeicherten oder übertragenen Informationen ...
- Vertraulichkeit: ... nur für einen autorisierten Nutzerkreis zugänglich (i.S.v. interpretierbar) zu sein.
- Integrität: ... vor nicht autorisierter Veränderung geschützt zu sein.
- Verfügbarkeit: ... autorisierten Nutzern in angemessener Frist zugänglich zu sein.
- Authentizität: ... ihren Urheber eindeutig erkennen zu können.
- Verbindlichkeit: ... sowohl integer als auch authentisch zu sein.
Schadenspotenzial
- Vandalismus, Terrorismus
- reine Zerstörungswut
- Systemmissbrauch
- illegitime Ressourcennutzung, Ziel i.d.R.: hocheffektive Folgeangriffe
- Manipulationvon Inhalten (
\rightarrowDesinformation)
- (Wirtschafts-) Spionage und Diebstahl
- Verlust der Kontrolle über kritisches Wissen (
\rightarrowRisikotechnologien) - immense wirtschaftliche Schäden (
\rightarrowTechnologieführer, Patentinhaber) - z.B. Diebstahl von industriellem Know-How
- Betrug, persönliche Bereicherung
- wirtschaftliche Schäden
- Sabotage, Erpressung
- Außerkraftsetzen lebenswichtiger Infrastruktur (z.B. schon Registrierkassen)
- Erpressung von ausgewählten (oder schlicht großen ) Zielgruppen durch vollendete, reversible Sabotage (
\rightarrowVerschlüsselung von Endanwenderinformationen)
Bedrohungen
- Eindringlinge (intruders)
- im engeren Sinne menschliche Angreifer ( ,,Hacker'' ), deren Angriff eine technische Schwachstelleausnutzt ( exploit )
- Schadsoftware (malicious software, malware)
- durch Ausnutzung einer (auch menschlichen) Schwachstelle zur Ausführung gebrachte Programme, die (teil-) automatisierte Angriffe durchführen
- Trojanische Pferde (trojan horses): scheinbar nützliche Software, die verborgene Angriffsfunktionalität enthält
- Viren, Würmer (viruses, worms): Schadsoftware, die Funktionalität zur eigenen Vervielfältigung und/oder Modifikation beinhaltet
- Logische Bomben (logicbombs): Code-Sequenz in trojanischen Pferden, deren Aktivierung an System-oder Datumsereignisse gebunden ist
- Root Kits
- Bots und Botnets
- (weit-) verteilt ausgeführte Schadsoftware
- eigentliches Ziel i.d.R. nicht das jeweils infizierte System
Professionelle Malware: Root Kit
- Programm-Paket, das unbemerkt Betriebssystem (und ausgewählte Anwendungen) modifiziert, um Administratorrechte zu erlangen
- Administrator-bzw. Rootrechte: ermöglichen Zugriff auf alle Funktionen und Dienste eines Betriebssystems
- Angreifer erlangt vollständige Kontrolle des Systems und kann
- Dateien (Programme) hinzufügen bzw. ändern
- Prozesse überwachen
- über die Netzverbindungen senden und empfangen
- bei all dem Hintertüren für Durchführung und Verschleierung zukünftiger Angriffe platziere
- Ziele eines Rootkits:
- seine Existenz verbergen
- zu verbergen, welche Veränderungen vorgenommen wurden
- vollständige und irreversible Kontrolle über BS zu erlangen
- Ein erfolgreicher Root-Kit-Angriff ...
- ... kann jederzeit
- ... mit hochaktuellem und systemspezifischem Wissen über Schwachstellen
- ... vollautomatisiert, also reaktiv unverhinderbar
- ... unentdeckbar
- ... nicht reversibel
- ... die uneingeschränkte Kontrolle über das Zielsystem erlangen.
- Voraussetzung: eine einzige Schwachstelle...
Schwachstellen
- Passwort (begehrt: Administrator-Passwörter...)
- ,,erraten''
- zu einfach, zu kurz, usw.
- Brute-Force-Angriffe mit Rechnerunterstützung
- Abfangen ( eavesdropping )
- unverschlüsselte Übertragung (verteilte Systeme) oder Speicherung
- Programmierfehler (Speicherfehler...!)
- im Anwenderprogrammen
- in Gerätemanagern
- im Betriebssystem
- Mangelhafte Robustheit
- keine Korrektur fehlerhafter Eingaben
- buffer overrun/underrun (,, Heartbleed'' )
- Nichttechnische Schwachstellen
- physisch, organisatorisch, infrastrukturell
- menschlich (
\rightarrowErpressung, socialengineering )
Zwischenfazit
- Schwachstellen sind unvermeidbar
- Bedrohungen sind unkontrollierbar
- ... und nehmen tendeziellzu!
Beides führt zu operationellen Risiken beim Betrieb eines IT-Systems
\rightarrow Aufgabe der Betriebssystemsicherheit: Auswirkungen operationeller Risiken reduzieren (wo diese nicht vermieden werden können...)
Wie dies geht: Security Engineering
Sicherheitspolitiken
- Herausforderung: korrekte Durchsetzung von Sicherheitspolitiken
- Vorgehensweise: Security Engineering
| Sicherheitsziele | Welche Sicherheitsanforderungen muss das Betriebssystem erfüllen? |
| Sicherheitspolitik | Durch welche Strategien soll es diese erfüllen? (\rightarrow Regelwerk) |
| Sicherheitsmechanismen | Wie implementiert das Betriebssystem seine Sicherheitspolitik? |
| Sicherheitsarchitektur | Wo implementiert das Betriebssystem seine Sicherheitsmechanismen (und deren Interaktion)? |
Sicherheitspolitiken und -modelle
Kritischfür korrekten Entwurf, Spezifikation, Implementierung der Betriebssystem-Sicherheitseigenschaften!
Begriffsdefinitionen:
- Sicherheitspolitik (Security Policy): Eine Menge von Regeln, die zum Erreichen eines Sicherheitsziels dienen.
- Sicherheitsmodell (Security Model): Die formale Darstellung einer Sicherheitspolitik zum Zweck
- der Verifikation ihrer Korrektheit
- der Spezifikation ihrer Implementierung.
Zugriffssteuerungspolitiken
... geben Regeln vor, welche durch Zugriffssteuerungsmechanismen in BS durchgesetzt werden müssen.
Zugriffssteuerung (access control): Steuerung, welcher Nutzer oder Prozess mittels welcher Operationen auf welche BS-Ressourcen zugreifen darf (z.B.: Anwender darf Textdateien anlegen, Administrator darf Dateisysteme montieren und System-Logdateien löschen, systemd - Prozess darf Prozessdeskriptoren manipulieren, ...)
Zugriffssteuerungspolitik: konkrete Regeln, welche die Zugriffssteuerung in einem BS beschreiben
Zugriffssteuerungsmodell: Sicherheitsmodell einer Zugriffssteuerungspolitik
Zugriffssteuerungsmechanismus: Implementierung einer Zugriffssteuerungspolitik
Beispiele für BS-Zugriffssteuerungspolitiken
klassifiziert nach Semantik der Politikregeln:
- IBAC (Identity-basedAccess Control): Politik spezifiziert, welcher Nutzer an welchen Ressourcen bestimmte Rechte hat.
- Bsp.: ,,Nutzer Anna darf Brief.docx lesen, aber nicht schreiben.''
- TE (Type-Enforcement): Politik spezifiziert Rechte durch zusätzliche Abstraktion (Typen): welcher Nutzertyp an welchem Ressourcentyp bestimmte Rechte hat.
- Bsp.: ,,Nutzer vom Typ Administrator dürfen Dateien vom Typ Log lesen und schreiben.''
- MLS (Multi-Level Security): Politik spezifiziert Rechte, indem aus Nutzern und Ressourcen hierarchische Klassen (Ebenen, ,,Levels'') gleicher Kritikalität im Hinblick auf Sicherheitsziele gebildet werden.
- Bsp.: ,,Nutzer der Klasse nicht vertrauenswürdig dürfen Dateien der Klasse vertraulich nicht lesen.''
- DAC (Discretionary Access Control, auch: wahlfreie Zugriffssteuerung ): Aktionen der Nutzer setzen die Sicherheitspolitik (oder wesentliche Teile davon) durch. Typisch: Begriff des Eigentümers von BS-Ressourcen.
- Bsp.: ,,Der Eigentümer einer Datei bestimmt (bzw. ändert), welcher Nutzer welche Rechte daran hat.''
- MAC (MandatoryAccess Control, auch: obligatorische Zugriffssteuerung ): Keine Beteiligung der Nutzer an der Durchsetzungeiner (zentral administrierten) Sicherheitspolitik.
- Bsp.: ,,Anhand ihres Dateisystempfads bestimmt das Betriebssystem, welcher Nutzer welche Rechte an einer Datei hat.''
Einige Beispiele ...
| DAC | MAC | |
|---|---|---|
| IBAC | Unixoide,Linux, Windows | Linux AppArmor, Mac OS Seatbelt |
| TE | - | SELinuxEnterprise Linux (RHEL), RedHat |
| MLS | Windows UAC | SELinux, TrustedBSD |
... und ein Verdacht Eindruck der Effektivität von DAC: ,,[...] so the theory goes. By extension, yes, there may be less malware, but that will depend on whether users keep UAC enabled, which depends on whether developers write software that works with it and that users stop viewing prompts as fast-clicking exercises and actually consider whether an elevation request is legitimate.'' (Jesper M. Johansson, TechNet Magazine) [https://technet.microsoft.com/en-us/library/2007.09.securitywatch.aspx, Stand: 10.11.2017]
Traditionell: DAC, IBAC
Auszug aus der Unix-Sicherheitspolitik:
- es gibt Subjekte (Nutzer, Prozesse) und Objekte (Dateien, Sockets ...)
- jedes Objekt hat einen Eigentümer
- Eigentümer legen Zugriffsrechte an Objekten fest (
\rightarrowDAC) - es gibt drei Zugriffsrechte: read, write, execute
- je Objekt gibt es drei Klassen von Subjekten, für die individuell Zugriffsrechte vergeben werden können: Eigentümer (,,u''), Gruppe (,,g''), Rest der Welt (,,o'')
In der Praxis:
- identitätsbasierte (IBAC), wahlfreie Zugriffssteuerung (DAC)
- hohe individuelle Freiheit der Nutzer bei Durchsetzung der Politik
- hohe Verantwortung ( ,,Welche Nutzer werden jemals in Gruppe vsbs sein...?'' )
-rw- rw- r-- 1 amthor vsbs 397032 2017-11-19 12:12 paper.pdf
Modellierung: Zugriffsmatrix
| acm | paper.pdf | aos-05.pptx | gutachten.tex | worse-engine |
|---|---|---|---|---|
| kühnhauser | rw | - | rw | rx |
| schlegel | rw | - | - | rx |
| amthor | rw | rw | - | rx |
| krause | r | - | - | - |
- acm (access control matrix): Momentaufnahme der globalen Rechteverteilung zu einem definierten ,,Zeitpunkt t''
- Korrektheitskriterium: Wie kann sich dies nach t möglicherweise ändern...? (HRU-Sicherheitsmodell)[HaRU76]
Modellkorrektheit: Rechteausbreitung
- Änderungsbeispiel: kühnhauser nimmt krause in Gruppe vsbs auf ...
- Rechteausbreitung ( privilegeescalation ), hier verursacht durch eine legale Nutzeraktion (
\rightarrowDAC)- (Sicherheitseigenschaft: HRU Safety ,
\rightarrow,,Systemsicherheit'')
- (Sicherheitseigenschaft: HRU Safety ,
Modern: MAC, MLS
Sicherheitspolitik der Windows UAC ( user account control):
- es gibt Subjekte (Prozesse) und Objekte (Dateisystemknoten)
- jedem Subjekt ist eine Integritätsklasse zugewiesen:
- Low: nicht vertrauenswürdig (z.B. Prozesse aus ausführbaren Downloads)
- Medium: reguläre Nutzerprozesse, die ausschließlich Nutzerdaten manipulieren
- High: Administratorprozesse, die Systemdaten manipulieren können
- System: (Hintergrund-) Prozesse, die ausschließlich Betriebssystemdienste auf Anwenderebene implementieren (etwa der Login-Manager)
- jedem Objekt ist analog eine dieser Integritätsklassen zugewiesen (Kritikalität von z.B. Nutzerdaten vs. Systemdaten)
- sämtliche DAC-Zugriffsrechte (die gibt es auch) müssen mit einer Hierarchie der Integritätsklassen konsistent sein (
\rightarrowein bisschen MAC) - Nutzer können diese Konsistenzanforderung selektiv außer Kraft setzen (
\rightarrowDAC)
MAC-Modellierung: Klassenhierarchie
Beispiel: Modelliert durch Relation \leq: gleich oder kritischer als
\leq=\{( High , Medium ), ( High , Low ), ( Medium , Low ), ( High , High ), ( Medium , Medium ), ( Low , Low )\}
- repräsentiert Kritikalität hinsichtlich des Sicherheitsziels Integrität (Biba-Sicherheitsmodell) [Biba77]
- wird genutzt, um legale Informationsflüsse zwischen Subjekten und Objekten zu modellieren
\rightarrowSchutz vor illegalem Überschreiben - leitet Zugriffsrechte aus Informationsflüssen ab:
- Prozess Datei: schreiben
- Prozess Datei: lesen
DAC-Modellierung: Zugriffsmatrix
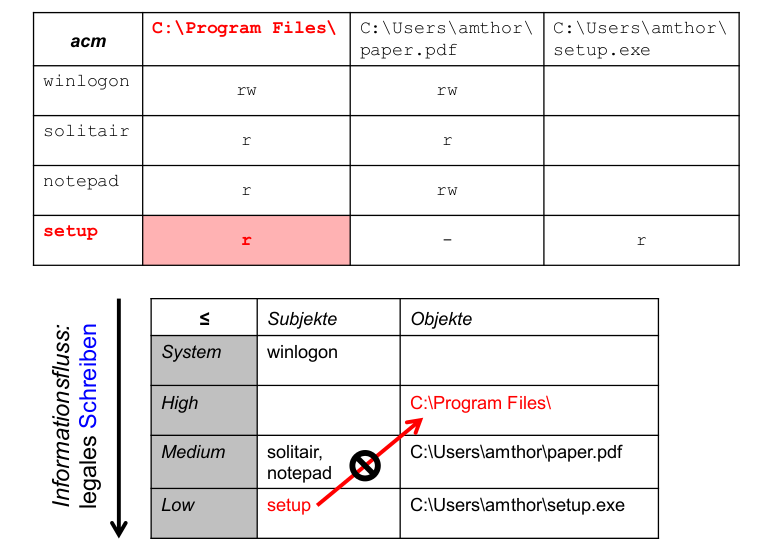
Modellkorrektheit: Konsistenz
- Korrektheitskriterium: Garantiert die Politik, dass acm mit
\leqjederzeit konsistent ist? ( BLP Security ) [BeLa76] - elevation-Mechanismus: verändert nach Nutzeranfrage (
\rightarrowDAC) sowohl acm als auch\leq\rightarrowkonsistenzerhaltend? - andere BS-Operationen: verändern unmittelbar nur acm (z.B. mittels Dateisystemmanagement)
\rightarrowkonsistenzerhaltend?
Autorisierungsmechanismen
Begriffsdefinitionen:
- Sicherheitsmechanismen: Datenstrukturen und Algorithmen, welche die Sicherheitseigenschaften eines Betriebssystems implementieren.
\rightarrowSicherheitsmechanismen benötigt man zur Herstellung jeglicher Sicherheitseigenschaften (auch jener, die in unseren Modellen implizit angenommen werden!)- Nutzerauthentisierung ( login - Dientsprogramm, Passwort-Hashing, ...)
- Autorisierungsinformationen (Metainformationen über Rechte, MLS-Klassen, TE-Typen, ...)
- Autorisierungsmechanismen (Rechteprüfung, Politikadministration, ...)
- kryptografische Mechanismen (Verschlüsselungsalgorithmen, Hashfunktionen, ...)
- Auswahl im Folgenden: Autorisierungsmechanismen und -informationen
Traditionell: ACLs, SUID
Autorisierungsinformationen:
- müssen Subjekte (Nutzer) bzw. Objekte (Dateien, Sockets ...) mit Rechten assoziieren
\rightarrowImplementierung der Zugriffsmatrix ( acm ), diese ist:- groß (
\rightarrowDateianzahl auf Fileserver) - dünn besetzt
- in Größe und Inhalt dynamisch veränderlich
\rightarroweffiziente Datenstruktur?
- groß (
- Lösung: verteilte Implementierung der acm als Spaltenvektoren, deren Inhalt in den Objekt-Metadaten repräsentiert wird: Zugriffssteuerungslisten ( Access Control Lists , ACLs)
ACLs: Linux-Implementierung
- objektspezifischer Spaltenvektor = Zugriffssteuerungsliste
- Dateisystem-Metainformationen: implementiert in I-Nodes
-rw- rw- r-- 1 amthor vsbs 397032 2017-11-19 12:12 paper.pdf
ACLs: Linux-Implementierung
Modell einer Unix acm ...
| lesen | schreiben | ausführen | |
|---|---|---|---|
| Eigentümer (,,u'') | ja | ja | ja |
| Rest der Welt (,,o'') | ja | nein | ja |
| Gruppe (,,g'') | ja | nein | ja |
- 3 - elementige Liste
- 3 - elementige Rechtemenge
\rightarrow9 Bits- dessen Implementierung kodiert in 16-Bit-Wort: 1 1 1 1 0 1 1 0 1
- ... und dessen Visualisierung in Linux:
$ ls -alF
drwxr-xr-x 2 amthor amthor 4096 2017-11-16 12:01 ./
drwxr-xr-x 31 amthor amthor 4096 2017-11-07 12:42 ../
-rw-rw-r-- 1 amthor vsbs 397032 2017-11-19 12:12 paper.pdf
-rw------- 1 amthor amthor 120064 2017-02-07 07:56 draft.tex
Autorisierungsmechanismen: ACL-Auswertung
Subjekte = Nutzermenge eines Linux-Systems... besteht aus Anzahl registrierter Nutzer
- jeder hat eindeutige UID (userID), z.B. integer- Zahl
- Dateien, Prozesse und andere Ressourcenwerden mit UID des Eigentümersversehen
- bei Dateien: Teil des I-Nodes
- bei Prozessen: Teil des PCB (vgl. Grundlagen ,,Betriebssysteme'')
- standardmäßiger Eigentümer: derjenige, eine Ressource erzeugt hat
Nutzergruppen (groups)
- jeder Nutzer wird durch Eintrag in einer Systemdatei ( /etc/group ) einer oder mehreren Gruppen zugeordnet(
\rightarrowACL: ,, g '' Rechte)
Superuser oder root... hat grundsätzlich uneingeschränkte Rechte.
- UID = 0
- darf insbesondere alle Dateien im System lesen, schreiben, ausführen; unabhängig von ACL
ACL-Implementierung
- ACLs:
- in welchen Kerneloperationen?
- welche Kernelschnittstellen (Rechte prüfen, ändern)?
- welche Datenstrukturen, wo gespeichert?
- acm und ACLs:
- Vorteile der Listenimplementierung?
- Nachteile ggü. zentral implementierter Matrix? (DAC vs. MAC, Administration, Analyse ...)
\rightarrowÜbung 2
Nutzerrechte \rightarrow Prozessrechte
bisher: Linux-Sicherheitspolitik formuliert Nutzerrechte an Dateien (verteilt gespeichert in ACLs)
Durchsetzung: basiert auf Prozessrechten
- Annahme: Prozesse laufen mit UID des Nutzers, welcher sie gestartet hat und repräsentieren Nutzerintention und Nutzerberechtigungen i.S.d. Sicherheitspolitik
- technisch bedeutet dies: ein Nutzer beauftragt einen anderen Prozess, sich zu dublizieren( fork() ) und das gewünschte Programm auszuführen ( exec*() )
- Vererbungsprinzip:
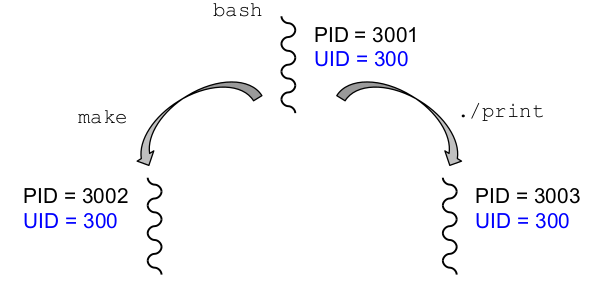
Autorisierungsmechanismen: Set-UID
konsequente Rechtevererbung:
- Nutzer können im Rahmen der DAC-Politik ACLs manipulieren
- Nutzer können (i.A.) jedoch keine Prozess-UIDs manipulieren
\rightarrowund genau so sollte es gem. Unix-Sicherheitspolitik auch sein!
Hintergrund:
- Unix-Philosophie ,, everythingisa file '': BS-Ressourcen wie Sockets, IPC-Instanzen, E/A-Gerätehandler als Datei repräsentiert
\rightarrowidentische Schutzmechanismen zum regulären Dateisystem - somit: Autorisierungsmechanismen zur Begrenzung des Zugriffs auf solche Geräte nutzbar (Bsp.: Zugriffe verschiedener Prozesse auf einem Drucker müssen koordiniert, ggf. eingeschränkt werden)
- dazu muss
- root bzw. zweckgebundener Nutzer Eigentümer des Druckers sein
- ACL als
rw- --- ---gesetzt sein
Folge:
- Nutzerprozesse könnten z.B. nicht drucken ...
Lösung: Mechanismus zur Rechtedelegation
- implementiert durch ein weiteres ,,Recht'' in ACL: SUID-Bit (,, setUID'' )
- Programmausführung modifiziert Kindprozess, so dass UID des Programmeigentümers (im Bsp.: root ) seine Rechte bestimmt
- Technik: eine von UID abweichende Prozess-Metainformation (
\rightarrowPCB) effektive UID (eUID) wird tatsächlich zur Autorisierung genutzt -rws rws r-x 1 root root 2 2011-10-01 16:00 print
Strategie für sicherheitskritische Linux-Programme
- Eigentümer: root
- SUID-Bit: gesetzt
- per eUID delegiert root seine Rechte an genau solche Kindprozesse, die SUID-Programme ausführen
- Folge: Nutzerprozesse können Systemprogramme (und nur diese) ohne permanente root - Rechte ausführen
Weiteres Beispiel: passwd
- ermöglicht Nutzern Ändern des (eigenen) Anmeldepassworts
- Schreibzugriff auf /etc/shadow (Password-Hashes) erforderlich ... Schutz der Integrität anderer Nutzerpasswörter?
- Lösung: `-rws rws r-x 1 root root 1 2005-01-20 10:00 passwd$
- passwd - Programm (und nur dieses!) wird mit root-Rechten ausgeführt ()... und passwd schreibt ja nur unseren eigenen Passwort-Hash)
Beispiel passwd
- Problem: privilegierter Zugriff durch unprivilegierte Anwendung
- Standard Linux Lösung:
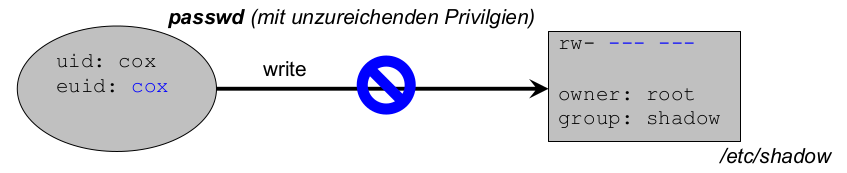
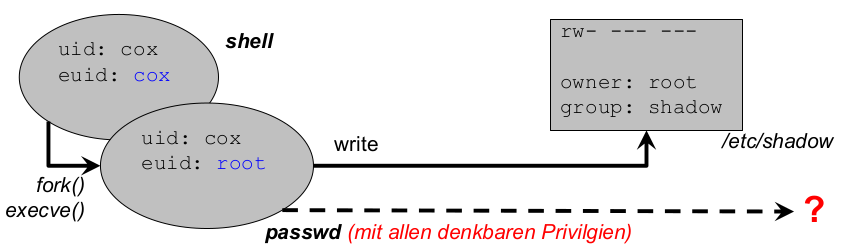
Modern: SELinux
- Ursprung
- Anfang 2000er Jahre: sicherheitsfokussiertes Betriebssystemprojekt für US-amerikanische NSA [LoSm01]
- Implementierung des (eigentlich)μKernel-Architekturkonzepts Flask
- heute: Open Source, Teil des mainline Linux Kernels
- Klassische UNIXoide: Sicherheitspolitik fest im Kernel implementiert
- I-Nodes, PCBs, ACLs, UID, GID, SUID, ...
- Idee SELinux: Sicherheitspolitikals eigene BS-Abstraktion
- zentrale Datenstruktur für Regeln, die erlaubte Zugriffe auf ein SELinux-System definiert
- erlaubt Modifikation und Anpassung an verschiedene Sicherheitsanforderungen
\rightarrowNFE Adaptivität ...
SELinux-Sicherheitsmechanismen
BS-Komponenten
- Auswertung der Sicherheitspolitik: Security- Server , implementiert als Linux-Kernelmodul(Technik: LSM, Linux Security Module );
\rightarrowentscheidet über alle Zugriffe auf alle Objekte - Durchsetzung der Sicherheitspolitik : LSM Hooks (generische Anfrage-Schnittstellen in allen BS-Funktionen)
- Administration der Sicherheitspolitik: geschrieben in Textform, muss zur Laufzeit in Security Server installiert werden
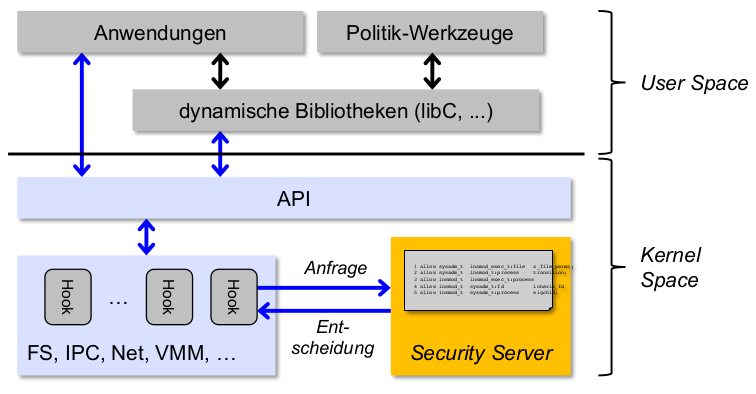
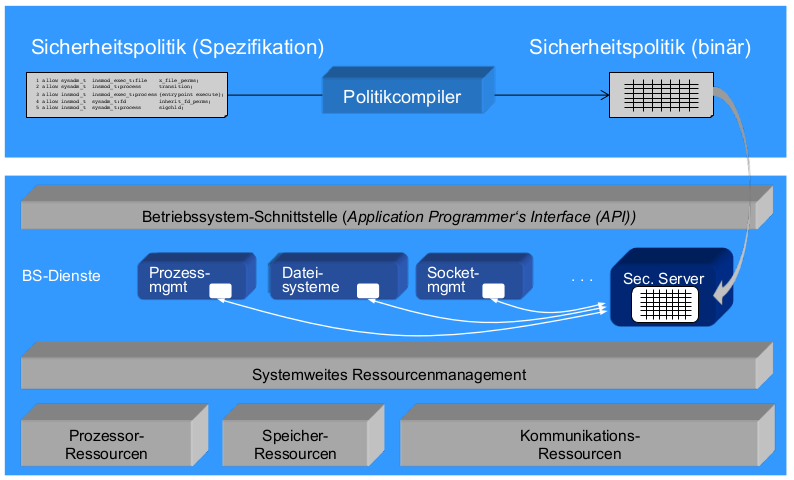
SELinux-Sicherheitspolitik
Repräsentation der Sicherheitspolitik:
- physisch: in spezieller Datei, die alle Regeln enthält (in maschinenlesbarer Binärdarstellung), die der Kernel durchsetzen muss
- diese Datei wird aus Menge von Quelldateien in einer Spezifikationssprache für SELinux-Sicherheitspolitiken kompiliert
- diese ermöglicht anforderungsspezifische SELinux-Politiken: können (und müssen) sich von einem SELinux-System zum anderen wesentlich unterscheiden
- Politik wird während des Boot-Vorgangs in Kernel geladen
Politiksemantik
Regeln einer SELinux-Sicherheitspolitiken, Semantische Konzepte(Auswahl):
- Type Enforcement (TE)
- Typisierung von
- Subjekten: Prozesse
- Objekten der Klassen: Dateien, Sockets, EA-Geräteschnittstellen, ...
- Rechte delegation durch Retypisierung(vgl. Unix-SUID!)
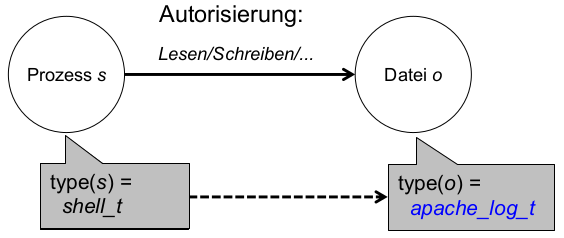
Autorisierungsinformationen
Security Context: Respräsentiert SELinux-Autorisierungsinformationen für jedes Objekt:
$ ps -Z
cox:doctor_r:shell_t:s0-s0:c0.c255 4056 pts/2 00:00:00 bash
$ ls -Z /etc/shadow
system_u:object_r:shadow_t:s0 /etc/shadow
- Semantik:
- Prozess bash läuft (momentan) mit Typ
shell_t - Datei shadow hat (momentan) den Typen
shadow_t.
- Prozess bash läuft (momentan) mit Typ
Autorisierungsregeln
... werden systemweit festgelegt in dessen Sicherheitspolitik (\rightarrow MAC):
Access Vector Rules
- definieren Autorisierungsregeln basierend auf Subjek-/Objekttypen
- Zugriffe müssen explizit gewährt werden ( default-deny )
allow shell_t passwd_exec_t : file { execute }; allow passwd_t shadow_t : file { read write }; - Semantik: Erlaube( ''allow'' ) ...
- jedem Prozess mit Typ
shell_t - ausführenden Zugriff (benötigt die Berechtigung
{execute}), - auf Dateien (also Objekte der Klassefile)
- mit Typ
passwd_exec_t.
- jedem Prozess mit Typ
Autorisierungsmechanismen: passwd Revisited
Klassischer Anwendungsfall für SELinux-TE: Passwort ändern
Lösung: Retypisierung bei Ausführung
- Prozess wechselt in einen aufgabenspezifischen Typ
passwd_t \rightarrowmassiv verringertes Missbrauchspotenzial!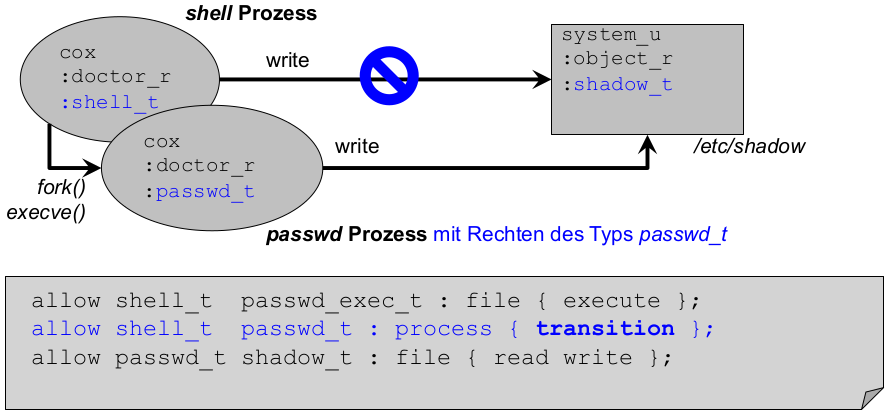
SELinux: weitere Politiksemantiken
- hier nur gezeigt: Überblick über TE
- außerdem relevant für SELinux-Politiken (und deren Administration...):
- Einschränkung von erlaubten Typtransitionen (Welches Programm darf mit welchem Typ ausgeführt werden?)
- weitere Abstraktionsschicht: rollenbasierte Regeln (RBAC)
\rightarrowSchutz gegen nicht vertrauenswürdige Nutzer (vs. nvw. Software)
- Ergebnis:
- ✓ extrem feingranulare, anwendungsspezifische Sicherheitspolitik zur Vermeidung von privilege escalation Angriffen
- ✓ obligatorische Durchsetzung (
\rightarrowMAC, zusätzlich zu Standard-Unix-DAC) - O Softwareentwicklung: Legacy-Linux-Anwendungen laufen ohne Einschränkung, jedoch
- ✗ Politikentwicklung und -administrationkomplex!
Weitere Informationen zu SELinux
\rightarrow MAC-Mechanismen ala SELinux sind heutzutage in vielerlei Software bereits zu finden:
- Datenbanksoftware (SEPostgreSQL)
- Betriebssysteme für mobile Geräte (FlaskDroid)
- sehr wahrscheinlich: zukünftige, sicherheitsorientierte BS...
Isolationsmechanismen
- bekannt: Isolationsmechanismen für robuste Betriebssysteme
- strukturierte Programmierung
- Adressraumisolation
- nun: Isolationsmechanismen für sichere Betriebssysteme
- all die obigen...
- kryptografische Hardwareunterstützung: Intel SGX Enclaves
- sprachbasiert:
- streng typisierte Sprachen und managed code : Microsoft Singularity [HLAA05]
- speichersichere Sprachen (Rust) + Adressraumisolation (μKernel): RedoxOS
- isolierte Laufzeitumgebungen: Virtualisierung (Kap. 6)
Intel SGX
- SGX: Software Guard Extensions [CoDe16]
- Ziel: Schutz von sicherheitskritischen Anwendungen durch vollständige, hardwarebasierte Isolation
\rightarrowstrenggenommen kein BS-Mechanismus: Anwendungen müssen dem BS nicht mehr vertrauen! (AR-Schutz, Wechsel von Privilegierungsebenen, ...)- Annahmen/Voraussetzungen:
- sämtliche Software nicht vertrauenswürdig (potenziell durch Angreifer kontrolliert)
- Kommunikation mit dem angegriffenen System nicht vertrauenswürdig (weder vertraulich noch verbindlich)
- kryptografische Algorithmen (Verschlüsselung und Signierung) sind vertrauenswürdig, also nicht für den Angreifer zu brechen
- Ziel der Isolation: Vertraulichkeit, Integrität und Authentizität(nicht Verfügbarkeit) von Anwendungen (Code) und den durch sie verarbeiteten Informationen
Enclaves
- Idee: geschützter Speicherbereich für Teilmenge der Seiten (Code und Daten) einer Task: Enclave Page Cache (EPC)
- Prozessor (und nur dieser) ver-und entschlüsselt EPC-Seiten
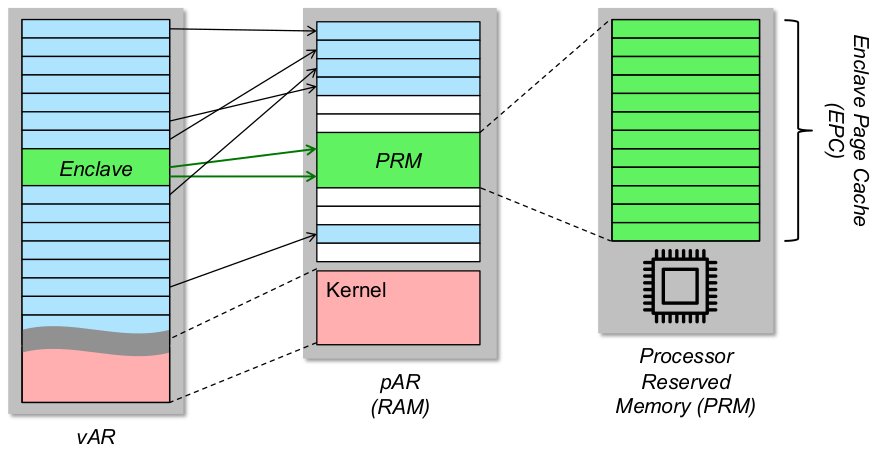
- Enclaves: Erzeugung
- Erzeugen: App.
\rightarrowSyscall\rightarrowBS-Instruktion an CPU (ECREATE) - Seiten hinzufügen: App.
\rightarrowSyscall\rightarrowBS-Instruktion an CPU (EADD)- Metainformationen für jede hinzugefügte Seite als Teil der EPC-Datenstruktur (u.a.: Enklave - ID, Zugriffsrechte, vAR-Adresse)
- Initialisieren: App.
\rightarrowSyscall\rightarrowBS-Instruktion an CPU (EINIT)- finalisiert gesamten Speicherinhalt für diese Enclave
- CPU erzeugt Hashwert = eindeutige Signatur des Enclave - Speicherinhalts
- falls BS bis zu diesem Punkt gegen Integrität der Anwendung verstoßen hat: durch Vergleich mit von dritter Seite generiertem Hashwert feststellbar!
- Erzeugen: App.
- Enclave - Zustandsmodell (vereinfacht) :
- Zugriff: App.
\rightarrowCPU-Instruktionen in User Mode (EENTER, EEXIT)- CPU erfordert, dass EPC-Seiten in vARder zugreifenden Task
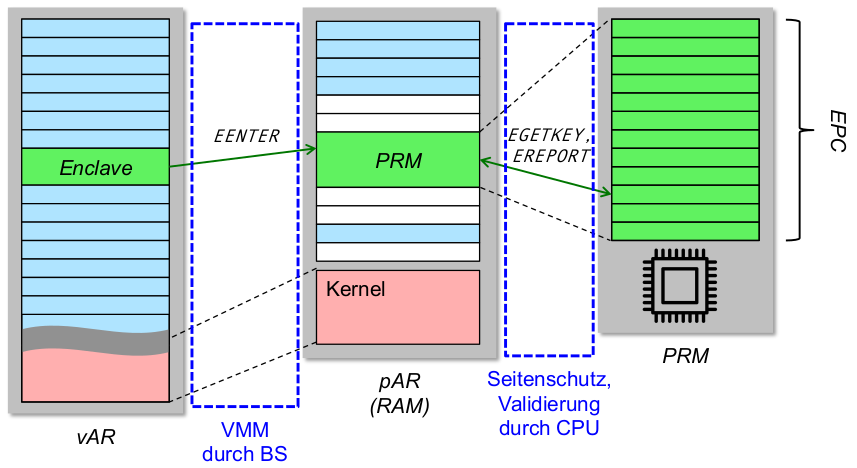
SGX: Licht und Schatten
- Einführung 2015 in Skylake - Mikroarchitektur
- seither in allen Modellen verbaut, jedoch nicht immer aktiviert
- Nutzer bislang: Demos und Forschungsprojekte, Unterstützung durch einige Cloud-Anbieter, (noch) keine größeren Märkte erschlossen
- Konzept hardwarebasierter Isolation ...
- ✓ liefert erstmals die Möglichkeit zur Durchsetzung von Sicherheitspolitiken auf Anwendungsebene
- O setzt Vertrauen in korrekte (und nicht böswillige) Hardwarevoraus
- O Dokumentation und Entwicklerunterstützung (im Ausbau ...)
- ✗ schützt mittels Enclaves einzelne Anwendungen, aber nicht das System
- ✗ steckt hinsichtlich praktischer Eigenschaften noch in den Anfängen (vgl. μKernel...):
- Performanz [WeAK18]
- Speicherkapazität(max. Größe EPC: 128 MiB, davon nur 93 MiBnutzbar)
\rightarrowkomplementäre NFE: Speichereffizienz!
Sicherheitsarchitekturen
Sicherheitsarchitektur... ist die Softwarearchitektur (Platzierung, Struktur und Interaktion) der Sicherheitsmechanismen eines IT-Systems.
- Voraussetzung zum Verstehen jeder Sicherheitsarchitektur:
- Verstehen des Referenzmonitorprinzips
- frühe Forschungen zu Betriebssystemsicherheit in 1970er-1980er Jahren durch US-Verteidigungsministerium
- Schlüsselveröffentlichung: Anderson-Report(1972)[Ande72]
\rightarrowfundamentalen Eigenschaften zur Charakterisierung von Sicherheitsarchitekturen
- Begriffe des Referenzmonitorprinzips kennen wir schon:
- Abgrenzung passiver Ressourcen (in Form einzelner Objekte, z.B. Dateien)
- von Subjekten (aktiven Elementen, z.B. laufenden Programmen, Prozessen) durch Betriebssystem
Referenzmonitorprinzip
- Idee:
\rightarrowsämtliche Autorisierungsentscheidungen durch einen zentralen (abstrakten) Mechanismus = Referenzmonitor- Bewertet jeden Zugriffsversuch eines Subjekts auf Objekt durch Anwendung einer Sicherheitspolitik (security policy)
\rightarrowvgl. SELinux
- somit: Architekturbeschreibung, wie Zugriffe auf Ressourcen (z.B. Dateien) auf solche Zugriffe, die Sicherheitspolitik erlaubt, eingeschränkt werden
- Autorisierungsentscheidungen
- basieren auf sicherheitsrelevanten Eigenschaften jedes Subjekts und jedes Objekts
- einige Beispiele kennen wir schon:
- Nutzname, Unix-Gruppe
- Prozess-ID, INode-Nummer
- SELinux-Typ
- Architekturkomponenten in a nutshell:
![nach [MaMC06], S.6](/wieerwill/Informatik/media/branch/master/Assets/AdvancedOperatingSystems-Referenzmonitorprinzip.png)
Definierende Eigenschaften: Referenzmonitor ist eine Architekturkomponenten, die
- (RM 1) bei sämtlichen Subjekt/Objekt-Interaktionen involviert sind
\rightarrowUnumgehbarkeit ( total mediation )
- (RM 2) geschützt sind vor unautorisierter Manipulation
\rightarrowManipulationssicherheit ( tamperproofness )
- (RM 3) hinreichend klein und wohlstrukturiert sind, um formalen Analysemethoden zugänglich zu sein
\rightarrowVerifizierbarkeit ( verifyability )
Referenzmonitor in Betriebssystemen
Nahezu alle Betriebssysteme implementieren irgendeine Form eines Referenzmonitors [Jaeg11] und können über Begriffe, wie
- Subjekte
- Objekte
- Regeln einer Sicherheitspolitik charakterisiert sowie auf
- Unumgehbarkeit
- Manipulationssicherheit
- Verifizierbarkeit ihrer Sicherheitsarchitektur hin untersucht werden
Beispiel: Standard- Linux
- Subjekte (generell Prozesse)
- haben reale (und effektive) Nutzer-Identifikatoren (UIDs)
- Objekte (verschiedene Systemressourcen, genutzt für Speicherung, Kommunikation: Dateien, Directories, Sockets, SharedMemory usw.)
- haben ACLs (,,rwxrw----'')
- Regeln der Sicherheitspolitik, die durch den Referenzmonitor (hier Kernel) unterstützt werden
- hart codiert, starr
- Sicherheitsattribute, die durch diese Regeln zur Prüfung genutzt werden (z.B. Zugriffsmodi)
- Objekten zugeordnet
- modifizierbar
Man beurteile die Politikimplementierung in dieser Architektur bzgl.:
- Unumgehbarkeit
- Manipulationssicherheit
- Verifizierbarkeit
Referenzmonitorimplementierung: Flask
( Flask - Architekturmodell)
![Abb. nach \[Spen07\] S. 139, Bild 11.1](/wieerwill/Informatik/media/branch/master/Assets/AdvancedOperatingSystems-referenzmonitor-flask.png)
SELinux-Architektur: Security Server
- Security Server: Laufzeitumgebung für Politik in Schutzdomäne des Kerns
- Objektmanager: implementiert in allen BS-Dienstenmittels,, Linux Security Module Framework ''
- jedes Subsystemvon SELinux , das zuständig für
- Erzeugung neuer Objekte
- Zugriff auf existierende Objekte
- Beispiele:
- Prozess-Verwaltung (behandelte Objekte: hauptsächlich Prozesse)
- Dateisystem (behandelte Objekte: hauptsächlich Dateien)
- Networking/Socket-Subsystem (behandelte Objekte: [verschiedene Typen von] Sockets)
- u.a.
- jedes Subsystemvon SELinux , das zuständig für
SELinux-Architektur: Objektklassen
- Objektmanager zur Verwaltung verschiedener Objektklassen
- spiegeln Diversität und Komplexität von Linux BS-Abtraktionen wider:
- Dateisysteme: file, dir, fd, filesystem, ...
- Netzwerk: netif, socket, tcp_socket, udp_socket, ...
- IPC: msgq, sem, shm, ...
- Sonstige: process, system, ...
- ...
Dateisystem als Objektmanager
- Durch Analyse von Linux - Dateisystem und zugehöriger API wurden zu überwachenden Objektklassen identifiziert:
- ergibt sich unmittelbar aus Linux-API:
- Dateien
- Verzeichnisse
- Pipes
- feingranularere Objektklassen für durch Dateien repräsentierte Objekte (Unix-Prinzip: ,,everythingisa file''!):
- reguläre Dateien
- symbolische Links
- zeichenorientierte Geräte
- blockorientierte Geräte
- FIFOs
- Unix-Domain Sockets (lokale Sockets)
- ergibt sich unmittelbar aus Linux-API:
- Permissions (Zugriffsrechte)
- für jede Objektklasse: Menge an Permissions definiert, um Zugriffe auf Objekte dieser Klasse zu kontrollieren
- Permissions: abgeleitet aus Dienstleistungen, die Linux-Dateisystem anbietet
\rightarrowObjektklassen gruppieren verschiedene Arten von Zugriffsoperationen auf verschiende Arten von Objekten- z.B. Permissions für alle ,,Datei''-Objektklassen (Auswahl ...): read, write, append, create, execute, unlink
- für ,,Verzeichnis''-Objektklasse: add_name, remove_name, reparant, search, rmdir
Trusted Computing Base (TCB)
Begriff zur Bewertung von Referenzmonitorarchitekturen: TCB ( Trusted Computing Base )
- = die Hard-und Softwarefunktionen eines IT-Systems, die notwendig und hinreichend sind, um alle Sicherheitsregeln durchzusetzen.
- besteht üblicherweise aus
- Laufzeitumgebung der Hardware(nicht E/A-Geräte)
- verschiedenen Komponenten des Betriebssystem-Kernels
- Benutzerprogrammen mit sicherheitsrelevanten Rechten (bei Standard-UNIX/Linux-Systemen: diejenigen mit root-Rechten)
- Betriebssystemfunktionen, die Teil der TCB sein müssen, beinhalten Teile
- des Prozessmanagements
- des Speichermanagements
- des Dateimanagements
- des E/A-Managements
- alle Referenzmonitorfunktionen
Echtzeitfähigkeit
Motivation
Echtzeitbegriff: Was ist ein Echtzeitsystem?
Any system in which the time at which output is produced is significant. This is usually because the input corresponds to some movement in the physical world, and the output has to relate to that same movement. The lag from input time to output time must be sufficiently small for acceptable timeliness. (The Oxford DictionaryofComputing)
A real-time system is any information processing activity or system which has to respond to externally generated input stimuli within a finite and specified period. [Young 1982]
A real-time system is a system that is required to react to stimuli from the environment (including the passage of physical time) within time intervals dictated by the environment. [Randall et.al. 1995]
Spektrum von Echtzeitsystemen:
- Regelungssysteme: z.B. eingebettete Systeme (exakter: Steuerungs-, Regelungs-u. Überwachungssysteme = ,,SRÜ''-Systeme)
- Endanwender-Rechnersysteme: z.B. Multimediasysteme
- Lebewesen: Menschen, Tiere
Beispiel Regelungssystem: ,,Fly-by-Wire''-Fluglage-Regelungssystem (Schema)
- Flugzeugbewegung
- Sensoren + Einstellmöglichkeiten des Piloten
- Echtzeit-Datenverarbeitung (durch Echtzeit-Rechnersystem)
- Aktoren setzen Berechnung um
- Einstellung von Regelflächen
- Aerodynamik und Flug Mechanik führt zu Flugzeugbewegung (1.)
Beispiel Überwachungssysteme
- Luftraumüberwachung:
- Ortsfeste Radarstation
- Mobile Radarstation
- Tiefflieger-Erfassungsradar
- Flugplatzradar Netzfunkstellen
- Zentrale
- Umweltüberwachung: Stickstoffdioxidkonzentration über Europa
- Vorgeburtliche Gesundheitsüberwachung: Herzschlagsüberwachungssystem für Mutter und Kind
Beispiel Multimediasystem
- zeitabhängige Datenwiedergabe
- Bildwiedergabe bei Mediendatenströmen
- Durchführung der Schritte durch Multimedia-Task binnen
t_{i+1} - t_i - Frist für Rendering in Multimedia-Tasks: festgelegt durch periodische Bildrate (24~48 fps
\rightarrow1/24 ... 1/48 s) \rightarrowBerücksichtigung bei Scheduling, Interruptbehandlung, Speicherverwaltung, ... erforderlich!
Zwischenfazit [Buttazzo97]
- Murphy‘s General Law: If something can go wrong, it will got wrong.
- Murphy‘s Constant: Damage to an object is proportional to its value.
- Johnson‘s First Law: If a system stops working, it will do it at the worst possible time.
- Sodd‘sSecond Law: Sooner or later, the worst possible combination of circumstances will happen.
Realisierung von Echtzeiteigenschaften: komplex und fragil!
Terminologie
bevor wir uns über Echtzeit-Betriebssystemen unterhalten:
- Wie ist die Eigenschaft Echtzeit definiert?
- Was sind (rechnerbasierte) Echtzeitsysteme?
- Wie können Echtzeitanwendungen beschrieben werden?
- Welche grundsätzlichen Typen von Echtzeitprozessen gibt es/wodurch werden diese charakterisiert?
Antwortzeit:
- Alle Definitionen -die zitierten u. andere - betrachten eine ,,responsetime'' (Antwortzeit, Reaktionszeit) als das Zeitintervall, das ein System braucht, um (irgend)eine Ausgabe als Reaktion auf (irgend)eine Eingabe zu erzeugen.
Frist
- Bei Echtzeitsystemen ist genau dieses
\Delta tkritisch, d.h. je nach Art des Systems darf dieses auf keinen Fall zu groß werden. - Genauer spezifizierbar wird dies durch Einführung einer Frist (deadline, due time)
d, die angibt bis zu welchem Zeitpunkt spätestmöglich die Reaktion erfolgt sein muss, bzw. wie groß das Intervall\Delta tmaximal sein darf.
Echtzeitfähigkeit und Korrektheit
- Wird genau dieses maximale Zeitintervall in die Spezifikation eines Systems einbezogen, bedeutet dies, dass ein Echtzeitsystem nur dann korrekt arbeitet, wenn seine Reaktion bis zur spezifizierten Frist erfolgt.
- Die Frist trennt also korrektes von inkorrektem Verhalten des Systems.
Harte und weiche Echtzeitsysteme
- Praktische Anwendungen erfordern oft Unterscheidung in harte und weiche Echtzeitsysteme:
- hartes Echtzeitsystem: keine Frist darf jemals überschritten werden (sonst: katastrophale Konsequenzen)
- weiches Echtzeitsystem: maßvolles (im spezifizierten Maß) Überschreiten von Fristen tolerierbar
Charakteristika von Echtzeit-Prozessen
- reale Echtzeitanwendungen beinhalten periodische oder aperiodische Prozesse (oder Mischung aus beiden)
- typische Unterscheidung:
- Periodische Prozesse
- zeitgesteuert (typisch: periodische Sensorauswertung)
- oft: kritische Aktivitäten
\rightarrowharte Fristen
- Aperiodische Prozesse
- ereignisgesteuert
- Abhängig von Anwendung: harte oder weiche Fristen, ggf. sogar Nicht-Echtzeit
- Periodische Prozesse
Periodische Prozesse
- bei Echtzeit-Anwendungen: häufigster Fall
- typisch für:
- periodische Analyse von Sensor-Daten (z.B. Umweltüberwachung)
- Aktionsplanung (z.B. automatisierte Montage)
- Erzeugung oder Verarbeitung einzelner Dateneinheiten eines multimedialen Datenstroms
- ...
- Prozessaktivierung
- ereignisgesteuert oder zeitgesteuert
- Prozesse, die Eingangsdaten verarbeiten: meist ereignisgesteuert, z.B. wenn neues Datenpaket eingetroffen
- Prozesse, die Ausgangsdaten erzeugen: meist zeitgesteuert, z.B. Ansteuerung von Roboteraktoren
Periodische Prozesse
- Fristen:
- hart oder weich (anwendungsabhängig)
- innerhalb einer Anwendung sind sowohl Prozesse mit harten oder weichen Fristen möglich
- Frist: spätestens am Ende der aktuellen Periode, möglich auch frühere Frist
- hart oder weich (anwendungsabhängig)
- Modellierung:
- unendliche Folge identischer Aktivierungen: Instanzen, aktiviert mit konstanter Rate (Periode)
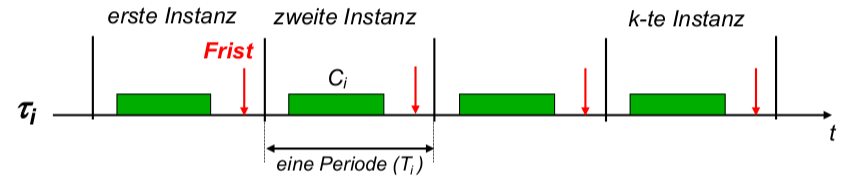
- Aufgaben des Betriebssystems:
- WennalleSpezifikationeneingehaltenwerden-muss Betriebssystem garantieren, dass
- zeitgesteuerte periodische Prozesse: mit ihrer spezifizierten Rate aktiviert werden und ihre Frist einhalten können
- ereignisgesteuerte periodische Prozesse: ihre Frist einhalten können
- WennalleSpezifikationeneingehaltenwerden-muss Betriebssystem garantieren, dass
Aperiodische Prozesse
- typisch für
- unregelmäßig auftretende Ereignisse, z.B.:
- Überfahren der Spurgrenzen, Unterschreiten des Sicherheitsabstands
\rightarrowReaktion des Fahrassistenzsystems - Nutzereingaben in Multimediasystemen (
\rightarrowSpielkonsole)
- Überfahren der Spurgrenzen, Unterschreiten des Sicherheitsabstands
- unregelmäßig auftretende Ereignisse, z.B.:
- Prozessaktivierung
- ereignisgesteuert
- Fristen
- oft weich(aber anwendungsabhängig)
- Aufgabendes Betriebssystems
- bei Einhaltung der Prozessspezifikationen muss Betriebssystem auch hier für Einhaltung der Fristen sorgen
- Modellierung
- bestehen ebenfalls aus (maximal unendlicher) Folge identischer Aktivierungen (Instanzen); aber: Aktivierungszeitpunkte nicht regelmäßig (möglich: nur genau eine Aktivierung)
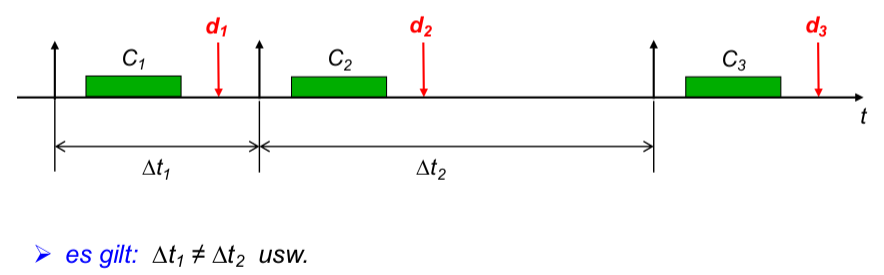
Parameter von Echtzeit-Prozessen
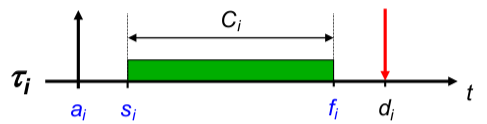
a_i: Ankunftszeitpunkt (arrival time); auch r ... request time/release time- Zeitpunkt, zu dem ein Prozess ablauffähig wird
s_i: Startzeitpunkt (start time)- Zeitpunkt, zu dem ein Prozess mit der Ausführung beginnt
f_i: Beendigungszeitpunkt (finishing time)- Zeitpunkt, an dem ein Prozess seine Ausführung beendet
d_i: Frist (deadline, due time)- Zeitpunkt, zu dem ein Prozess seine Ausführung spätestens beenden sollte
C_i: Bearbeitungszeit(bedarf) (computation time)- Zeitquantum, das Prozessor zur vollständigen Bearbeitung der aktuellen Instanz benötigt (Unterbrechungen nicht eingerechnet)
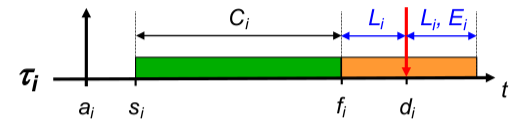
L_i: Unpünktlichkeit (lateness):L_i= f_i - d_i- Zeitbetrag, um den ein Prozess früher oder später als seine Frist beendet wird (wenn Prozess vor seiner Frist beendet, hat
L_inegativen Wert)
- Zeitbetrag, um den ein Prozess früher oder später als seine Frist beendet wird (wenn Prozess vor seiner Frist beendet, hat
E_i: Verspätung (exceeding time, tardiness):E_i= max(0, L_i)- Zeitbetrag, den ein Prozess noch nach seiner Frist aktiv ist
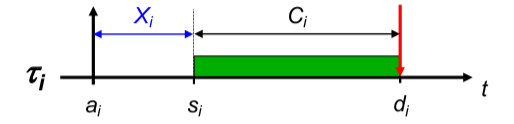
X_i: Spielraum (Laxity, Slacktime):X_i = d_i - a_i - C_i- maximales Zeitquantum, um das Ausführung eines Prozesses verzögert werden kann, damit dieser noch bis zu seiner Frist beendet werden kann (
f_i=d_i)
- maximales Zeitquantum, um das Ausführung eines Prozesses verzögert werden kann, damit dieser noch bis zu seiner Frist beendet werden kann (
- außerdem:
- criticality: Parameter zur Beschreibung der Konsequenzen einer Fristüberschreitung (typischerweise ,,hart'' oder ,,weich'')
V_i...Wert (value): Parameter zum Ausdruck der relativen Wichtigkeit eines Prozesses bezogen auf andere Prozesse der gleichen Anwendung
Echtzeitfähige Betriebssysteme
- Hauptfragestellungen
- Was muss BS zu tun, um Echtzeitprozesse zu ermöglichen? Welche Teilprobleme müssen beachtet werden?
- Welche Mechanismen müssen hierfür anders als bei nicht-echtzeitfähigen Betriebssystemen implementiert werden, und wie?
- Grundlegender Gedanke
- Abgeleitet aus den Aufgaben eines Betriebssystems sind folgende Fragestellungenvon Interesse:
- Wie müssen die Ressourcen verwaltet werden? (
\rightarrowCPU, Speicher, E/A, ...) - Sind neue Abstraktionen, Paradigmen (Herangehensweisen) und entsprechende Komponenten erforderlich (oder günstig)?
- Prozess-Metainformationen
- Frist
- Periodendauer
- abgeleitet davon: Spielraum, Unpünktlichkeit, Verspätung, ...
- im Zusammenhang damit: Prioritätsumkehr, Überlast
- Ressourcen-Management
- Wie müssen Ressourcen verwaltet werden, damit Fristen eingehalten werden können?
Wir betrachten i.F.
- Algorithmen, die Rechnersysteme echtzeitfähig machen -einschließlich des Betriebssystems:
- grundlegende Algorithmen zum Echtzeitscheduling
- Besonderheiten der Interruptbehandlung
- Besonderheiten der Speicherverwaltung
- Probleme, die behandelt werden müssen, um Echtzeitfähigkeit nicht zu be- oder verhindern:
- Prioritätsumkehr
- Überlast
- Kommunikation-und Synchronisationsprobleme
Echtzeitscheduling
- Scheduling:
- Schedulingvon Prozessen/Threads als wichtigster Einflussfaktor auf Zeitverhalten des Gesamtsystems
- Echtzeit-Scheduling:
- benötigt: Scheduling-Algorithmen, die Scheduling unter Berücksichtigung der ( unterschiedlichen ) Fristen der Prozesse durchführen können
- Fundamentale Algorithmen:
- wichtigste Strategien:
- Ratenmonotones Scheduling (RM)
- Earliest Deadline First (EDF)
- beide schon 1973 von Liu & Layland ausführlich diskutiert [Liu&Layland73]
Annahmen der Scheduling-Strategien
- A1: Alle Instanzen eines periodischen Prozesses
t_itreten regelmäßig und mit konstanter Rate auf (= werden aktiviert ). Das ZeitintervallT_izwischen zwei aufeinanderfolgenden Aktivierungen heißt Periode des Prozesses. - A2: Alle Instanzen eines periodischen Prozesses
t_ihaben den gleichen Worst-Case-RechenzeitbedarfC_i. - A3: Alle Instanzen eines periodischen Prozesses
t_ihaben die gleiche relative FristD_i, welche gleich der PeriodendauerT_iist. - A4: Alle Prozessesind kausal unabhängig voneinander (d.h. keine Vorrang- und Betriebsmittel-Restriktionen)
- A5: Kein Prozess kann sich selbst suspendieren, z.B. bei E/A-Operationen.
- A6: Alle Prozesse werden mit ihrer Aktivierung sofort rechenbereit ( release time = arrival time ).
- A7: Jeglicher Betriebssystem-Overhead (Kontextwechsel, Scheduler-Rechenzeit) wird vernachlässigt.
A5-7 sind weitere Annahmen des Scheduling Modells
Ratenmonotones Scheduling (RM)
- Voraussetzung:
- periodisches Bereitwerden der Prozesse/Threads, d.h. periodische Prozesse bzw. Threads
- Strategie RM:
- Prozess (Thread) mit höchster Ankunftsrate bekommt höchste statische Priorität (Kriterium: Wie oft pro Zeiteinheit wird Prozess bereit?)
- Scheduling-Zeitpunkt: nur einmal zu Beginn (bzw. wenn neuer periodischer Prozess auftritt)
- präemptiver Algorithmus
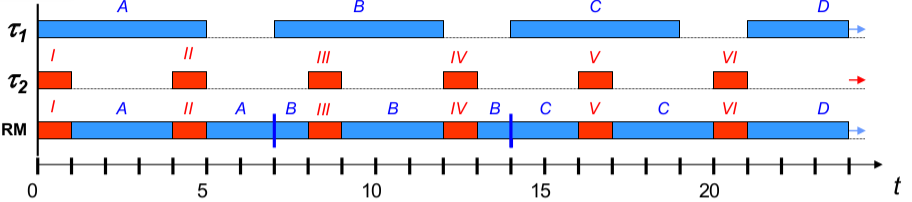
- Zuteilung eines Prozessors nach RM
t_1, t_2: Anforderungen von Prozessorzeit durch zwei periodische Prozesse- darunter: Prozessorzuteilung nach RM
- Optimalität von RM
- Unter allen Verfahren mit festen (statischen)Prioritäten ist RM optimaler Algorithmus in dem Sinne, dass kein anderes Verfahren dieser Klasse eine Prozessmenge einplanen kann, die nicht auch von RM geplant werden kann. [Liu&Layland73]
- Prozessor-Auslastungsfaktor
- Bei gegebener Menge von n periodischen Prozessen gilt:
U=\sum_{i=1}^n \frac{C_i}{T_i} - mit
\frac{C_i}{T_i}Anteil an Prozessorzeit für jeden periodischen Prozesst_i - und
USumme der Prozessorzeit zur Ausführung der gesamten Prozessmenge (,,utilization factor'')
- Bei gegebener Menge von n periodischen Prozessen gilt:
- Prozessorlast
Uist folglich Maß für die durch Prozessmenge verursachte Last am Prozessor\rightarrowAuslastungsfaktor
- Planbarkeitsanalyse einer Prozessmenge
- im allgemeinen Fall kann RM einen Prozessor nicht zu 100% auslasten
- von besonderem Interesse: kleinste obere Grenze des Auslastungsfaktors
U_{lub}(lub: ,,least upper bound'')
- Beispiel für
n=2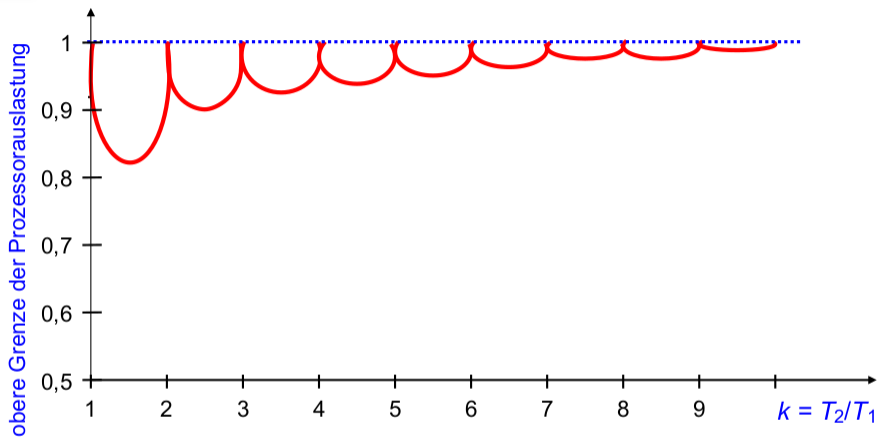
- Obere Grenze des Prozessor-Auslastungsfaktors für zwei periodische Prozesse als Funktion des Verhältnisses ihrer Perioden.
- (Abb. nach [Buttazzo97] Bild 4.7, S. 90)
- Obere Auslastungsgrenze bei RM
- nach [Buttazzo97] (S. 89-91) erhält man bei n Prozessen für RM:
U_{lub}=n(2^{\frac{1}{n}}-1) - für
n\rightarrow\inftykonvergiertU_{lub}zuln\ 2 \approx 0,6931... - Wird genannter Wert nicht überschritten, sind beliebige Prozessmengen planbar.
- (Herleitung siehe [Buttazzo97] , Kap. 4.3.3)
- nach [Buttazzo97] (S. 89-91) erhält man bei n Prozessen für RM:
Earliest Deadline First (EDF)
- Voraussetzung:
- kann sowohl periodische als auch aperiodische Prozesse planen
- Optimalität:
- EDF in Klasse der Schedulingverfahren mit dynamischen Prioritäten: optimaler Algorithmus [Liu&Layland73]
- Strategie EDF:
- Zu jedem Zeitpunkt erhält Prozess mit frühester Frist höchste dynamische Priorität
- Scheduling-Zeitpunkt: Bereitwerden eines (beliebigen) Prozesses
- präemptiver Algorithmus (keine Verdrängung bei gleichen Prioritäten)
- Beispiel

- Zuteilung eines Prozessors nach EDF
t_1, t_2: Anforderungen nach Prozessorzeit durch zwei periodische Prozesse- darunter: Prozessorzuteilung nach EDF
- Planbarkeitsanalyse:
- Mit den Regeln
A1 ... A7ergibt sich für die obere Schranke des Prozessorauslastungsfaktors:U_{lub}= 1\rightarrowAuslastung bis 100% möglich! - Eine Menge periodischer Prozesse ist demnach mit EDF planbar genau dann wenn:
U=\sum_{i=1}^n \frac{C_i}{T_i}\leq 1(Prozessor natürlich nicht mehr als 100% auslastbar)
- Mit den Regeln
- Beweis: Obere Auslastungsgrenze bei EDF
- Behauptung: Jede Menge von n periodischen Tasks ist mit EDF planbar
\Leftrightarrow:U=\sum_{i=1}^n \frac{C_i}{T_i}\leq 1 \Leftarrow:U>1übersteigt die verfügbare Prozessorzeit; folglich kann niemals eine Prozessmenge mit dieser (oder höherer) Gesamtauslastung planbar sein.\Rightarrow: Beweis durch Widerspruch. Annahme:U\leq 1und die Prozessmenge ist nicht planbar. Dies führt zu einem Schedule mit Fristverletzung zu einem Zeitpunktt_2, z.B.:- Beobachtungen an diesem Schedule:
existsein längstes, kontinuierliches Rechenintervall[t_1,t_2], in welchem nur Prozessinstanzen mit Fristen\leq t_2rechnen- die Gesamtrechenzeit
C_{bad}aller Prozesse in[t_1,t_2]muss die verfügbare Prozessorzeit übersteigen:C_{bad} > t_2-t_1(sonst: keine Fristverletzung ant_2) - Anwesenheit in
[t_1,t_2]leitet sich davon ab, ob (genauer: wie oft) die Periode eines Prozesses int_2-t_1passt:t_iin[t_1,t_2]\Leftrightarrow\lfloor\frac{t_2-t_1}{T_i}\rfloor >0 - Damit ist
C_{bad}die Summe der Rechenzeiten aller Prozessinstanzen, die garantiert in[t_1,t_2]sind, mithin:C_{bad}=\sum_{i=1}^n \lfloor\frac{t_2-t_1}{T_i}\rfloor C_i - Im Beispiel:
t_1... t_3in[t_1,t_2], folglich:C_{bad}= 2 C_1 + 1 C_2 + 1 C_3 - Zu zeigen: Beobachtung
C_{bad}> t_2-t_1widerspricht AnnahmeU\leq 1. - Es gilt
\sum_{i=1}^n \lfloor\frac{t_2-t_1}{T_i}\rfloor C_i\leq\sum_{i=1}^n\frac{t_2-t_1}{T_i}C_iwegen Abrundung. - Mit
U=\sum_{i=1}^n\frac{C_i}{T_i}folgt darausC_{bad}\leq(t_2-t_1)U C_{bad}>t_2-t_1entspricht also(t_2-t_1)U>t_2-t_1und somitU>1. Widerspruch zur Annahme!
- Behauptung: Jede Menge von n periodischen Tasks ist mit EDF planbar
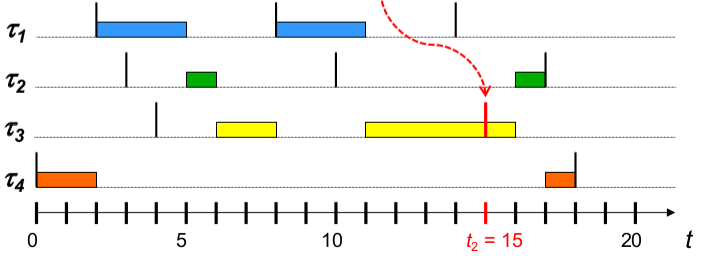
Vergleich: EDF vs. RM
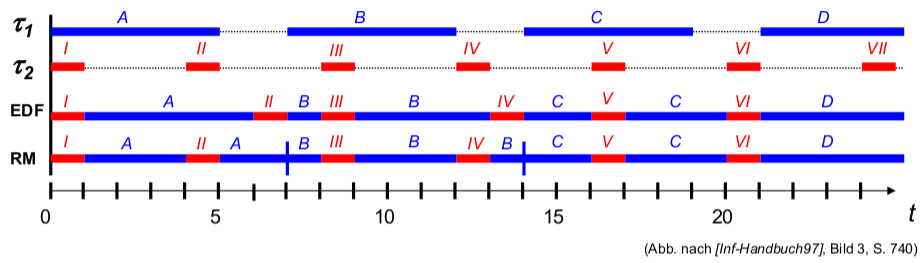
Zuteilung eines Prozessors nach EDF (dynamisch) bzw. RM (statisch) t_1,t_2: Anforderungen nach Prozessorzeit durch zwei periodische Prozesse darunter: Prozessorzuteilung nach EDF bzw. RM
- gut erkennbar: deutliche Unterschiede bei Scheduling mit statischem (RM) vs. dynamischem Algorithmus (EDF).
Vergleich: Anzahl Prozesswechsel
- Häufigkeit von Prozesswechseln im Beispiel:
- RM: 16
- EDF: 12
- Ursache: dynamische Prioritätenvergabe führt dazu, dass Instanz II von
t_2die gleiche Priorität wie Instanz A vont_1hat (usw.)\rightarrowkeine unnötige Verdrängung
Vergleich: 100% Prozessorauslastung
- EDF: erzeugt auch bei Prozessorauslastung bis 100% (immer) korrekte Schedules
- RM: kann das im allgemeinen Fall nicht
- Bedeutung von 100% Prozessorauslastung in der Praxis: Überwiegend müssen Systeme mit harten Echtzeitanforderungen auch weiche Echtzeit- sowie Nicht-Echtzeit-Prozesse unterstützen. Daher: Belegungslücken am Prozessor für die letzteren beiden nutzbar.
Vergleich: Implementierung
- RM
- statisch: jeweils eine Warteschlange pro Priorität:
- Einfügen und Entfernen von Tasks:
O(1) 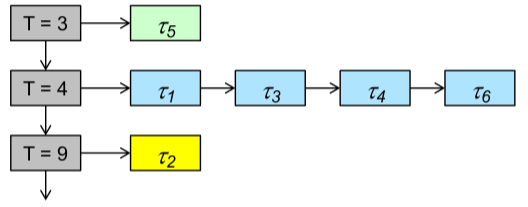
- EDF
- dynamisch: balancierter Binärbaum zur Sortierung nach Prioritäten:
- Einfügen und Entfernen von Tasks:
O(log\ n) 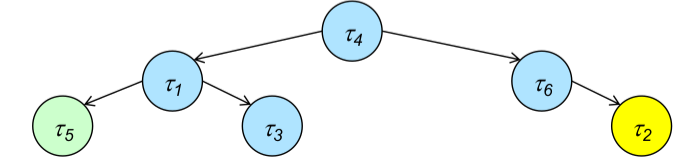
Scheduling in Multimedia-Anwendungen
- Konkretisierung des Betrachtungswinkels
- RM und EDF wurden entwickelt insbesondere für Echtzeit-Regelsysteme
\rightarrowohne Berücksichtigung von Multimediasystemen - Multimediasysteme
\rightarrowandere Probleme, schwächere Annahmen: spezialisierte Scheduling-Algorithmen - gehen meist auch von EDF und/oder RM als Grundlage aus
- RM und EDF wurden entwickelt insbesondere für Echtzeit-Regelsysteme
- Betrachteter Algorithmus:
- Beispielfür spezialisierten Scheduling-Algorithmus:
- RC-Algorithmus - entwickelt an University of Texas
- Anpassung von EDF an Charakteristika von Multimedia-Anwendungen
- Beispielfür spezialisierten Scheduling-Algorithmus:
Prozesstypen in Multimedia-Anwendungen
- Echte Multimedia-Prozesse
- periodische Prozesse: weiche Fristen
- pünktliche periodische Prozesse mit konstantem Prozessorzeitbedarf
Cfür jede Instanz (unkomprimierte Audio- und Videodaten) - pünktliche periodische Prozesse mit unterschiedlichem
Ceinzelner Instanzen (komprimierte Audio- und Videodaten) - unpünktliche periodische Prozesse:
- verspätete Prozesse
- verfrühte Prozesse
- pünktliche periodische Prozesse mit konstantem Prozessorzeitbedarf
- aperiodische-Prozesse aus Multimedia-Anwendungen: weiche Fristen
- Prozesse nebenläufiger Nicht-Multimedia-Anwendungen
- interaktive Prozesse : keine Fristen , aber: keine zu langen Antwortzeiten Ansatz (z.B.): maximal tolerierbare Verzögerung
- Hintergrund-Prozesse : zeitunkritisch, keine Fristen, aber : dürfen nicht verhungern
Multimediaanwendungen sind ein typisches Beispiel für mögliche Abweichungen der Lastpezifikation (T_i,C_i) eines Echtzeitprozesses!
Problem: Abweichungen von Lastspezifikation
- gibt Prozessor nicht frei
- verspätete periodische Prozesse
RC Algorithmus
- Ziel
- spezifikationstreue Prozesse nicht bestrafen durch Fristüberschreitung aufgrund abweichender Prozesse
- Idee
- grundsätzlich: Schedulingnach frühester Fristaufsteigend (= EDF)
\rightarrowfür eine vollständig spezifikationstreue Prozessmenge verhält sich RC wie reines EDF - Frist einer Instanz wird dynamisch angepasst:basierend auf derjenigen Periode, in der sie eigentlich sein sollte lt. Spezifikation der Prozessornutzung (
U_i, hier: ,,Rate''):U_i=\frac{C_i}{T_i} - Bsp.:
U_i =\frac{20}{40}=\frac{1}{2}(t_Bhat spezifizierte Aktivitätsrate von0,5pro Periode)
- grundsätzlich: Schedulingnach frühester Fristaufsteigend (= EDF)
RC Algorithmus: Strategie
- Variablen
a_i: Ankunftszeit der zuletzt bereitgewordenen Instanz vont_it_i^{virt}: virtuelle Zeit in aktueller Periode, diet_ibereits verbraucht hatc_i^{virt}: Netto-Rechenzeit, diet_iin aktueller Periode bereits verbraucht hatd_i: dynamische Frist vont_i, nach der sich dessen Priorität berechnet (EDF)
- Strategie
- für eine bereite (lauffähige) Instanz von
t_i: adaptiere dynamischd_ibasierend auft_i^{virt} - für eine bereit gewordene (neu angekommene oder zuvor blockierte) Instanzvon
t_i: aktualisieret_i^{virt}auf akt. Systemzeit(t)\rightarrowetwaiger ''Zeitkredit'' verfällt
- für eine bereite (lauffähige) Instanz von
RC Algorithmus: Berechnung von t_i^{virt}
Beispiel: Situation bei $t=20ms$

Da t_B aber noch weiteren Rechenbedarf hat: Situation bei $t=30 ms$
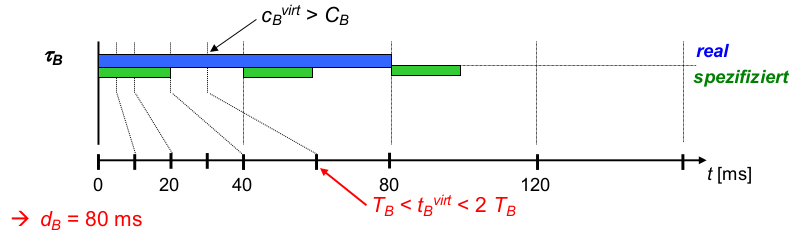
RC Algorithmus: Adaptionsfunktion
Für Prozess ti zu jedem Scheduling-Zeitpunkt:
RC (t_i) {
if (t_i. status wurde auf BEREIT gesetzt) {
t_i^virt := max( t_i^virt , t ); //kein Zeitkredit -> kein ,,Nachholen'' von verpassten/ungenutzten Perioden
} else {
c_i^virt := Gesamtprozessorzeit seit letztem Aufruf RC(t_i);
t_i^virt := t_i^virt + c_i^virt / U_i ; //Zeitwert, bis zu dem t_i Rechenzeit gemäß seiner Rate U_i erhalten hat
}
if (t_i. status != BLOCKIERT) {
finde k, so dass gilt:
a_i + (k - 1) * T_i <= t_i^virt < a_i + k * T_i ; // finde diejenige (aktuelle oder zukünftige) Periode, in der t_i^virt liegt
d_i := a_i + k * T_i ; // setze d_i auf deren Periodenende
}
}
RC Algorithmus: Scheduling
Zeitpunkte, zu denen der Scheduler aktiv wird:
- aktuell laufender Prozess
t_iblockiert:RC(t_i)
- Prozesse
t_i..._jwerden bereit:for\ x\in[i,j]: RC(t_x)
- periodischer ,,clock tick'' (SchedulingInterrupt):
t_i:= aktuell ausgeführter ProzessRC(t_i)
anschließendes Scheduling (präemptiv) = EDF:
SCHED := {t_i |t_i.status == BEREIT ⋀ d_i minimal }; // bereite(r) Prozess(e) mit nächster Frist
if (∃ t_j : t_j.status == LAUFEND) ⋀ ( d_j ≤ d_i )
do nothing; // ggf. laufenden Prozess bevorzugen
else
preempt(rnd_member( SCHED )); // sonst: irgendein Prozess mit nächster Frist verdrängt den laufenden
Umgang mit abweichenden Prozessen unter RC
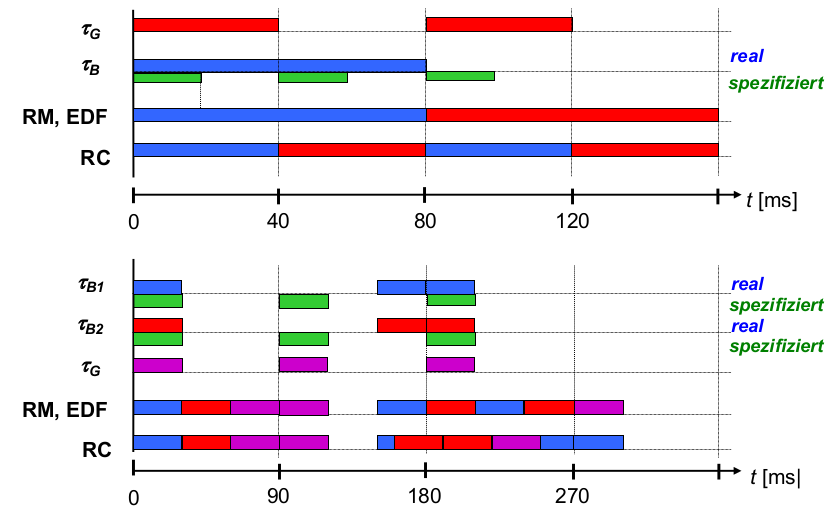
Resultat
Garantie: Prozesse, die sich entsprechend ihrer Spezifikation verhalten, erhalten bis zum Ende jeder spezifizierten Periode ihren spezifizierten Anteil an Prozessorzeit.
Auswirkung auf verschiedene Prozesstypen:
- ,,pünktliche'' Prozesse: Einhaltung der Frist in jeder Periode garantiert (unabhängig von Verhalten anderer Prozesse)
- ,,verspätete'' Prozesse: nur aktuelle Periode betrachtet, Nachholen ,,ausgelassener Perioden'' nicht möglich
- ,,gierige'' Prozesse: Prozessorentzug, sobald andere lauffähige Prozesse frühere Fristen aufweisen
- nicht-periodische Hintergrundprozesse: pro ,,Periode'' wird spezifizierte Prozessorrate garantiert (z.B. kleine Raten bei großen ,,Periodendauern'' wählen.)
Umgang mit gemischten Prozessmengen
- Hintergrund-Scheduling:
- Prinzip:
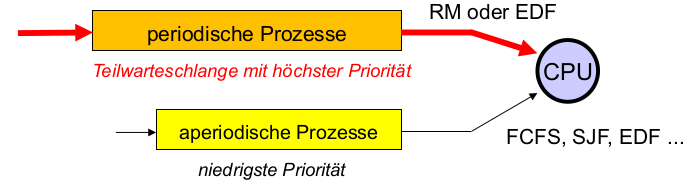
- rechenbereite Prozesse auf 2 Warteschlangen aufgeteilt (einfache Variante eines Mehr-Ebenen-Scheduling )
- Warteschlange 1:
- alle periodischen Prozesse
- mit höchster Priorität mittels RM oder EDF bedient
- Warteschlange 2:
- alle aperiodischen Prozesse
- nur bedient, wenn keine wartenden Prozesse in Warteschlange 1
- Prinzip:
Hintergrund-Scheduling: Vor- und Nachteile
- Hauptvorteil:
- einfache Implementierung
- Nachteile:
- Antwortzeit aperiodischer Prozesse kann zu lang werden (insbesondere bei hoher aperiodischer Last)
\rightarrowVerhungern möglich! - geeignet nur für relativ zeitunkritische aperiodische Prozesse
- Antwortzeit aperiodischer Prozesse kann zu lang werden (insbesondere bei hoher aperiodischer Last)
- Beispiel: Hintergrund-Scheduling mit RM
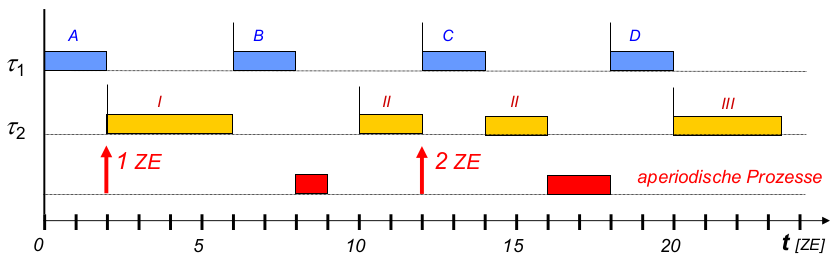
Optimierung: Server-Prozess
- Scheduling mit Server-Prozessen:
- Prinzip: periodisch aktivierter Prozess benutzt zur Ausführung aperiodischer Prozessoranforderungen
- Beschreibung Server-Prozess: durch Parameter äquivalent zu wirklichem periodischen Prozess:
- Periodendauer
T_S - ,,Prozessorzeitbedarf''
C_S; jetzt Kapazitätdes Server-Prozesses
- Periodendauer
- Arbeitsweise Server-Prozess:
- geplant mit gleichem Scheduling-Algorithmus wie periodische Prozesse
- zum Aktivierungszeitpunkt vorliegende aperiodische Anforderungen bedient bis zur Kapazität des Servers
- keine aperiodischen Anforderungen: Server suspendiert sich bis Beginn der nächsten Periode (Schedule wird ohne ihn weitergeführt
\rightarrowProzessorzeit für periodische Prozesse) - Kapazitätin jeder Server-Periode neu ''aufgeladen''
Beispiel: Server-Prozess mit RM
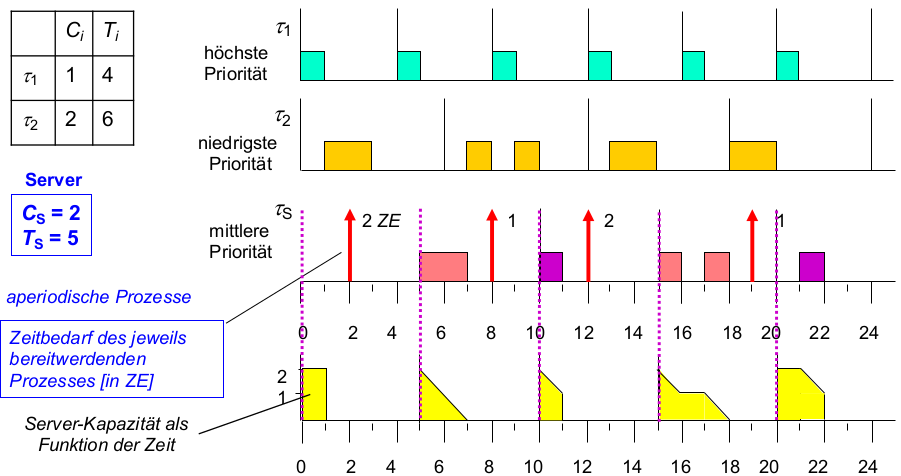
Optimierung: Slack-Stealing
- Prinzip: Es existiert passiver Prozess ,,slack stealer'' (kein periodischer Server)
- versucht so viel Zeit wie möglich für aperiodische Anforderungen zu sammeln
- realisiert durch ,,slackstealing''(= Spielraum-Stehlen) bei periodischen Prozessen
- letztere auf Zeit-Achse so weit nach hinten geschoben, dass Frist und Beendigungszeitpunkt zusammenfallen
- Sinnvoll, da normalerweise Beenden periodischer Prozesse vor ihrer Frist keinerlei Vorteile bringt
- Resultat: Verbesserung der Antwortzeiten für aperiodische Anforderungen

Prioritätsumkehr
Mechanismen zur Synchronisation und Koordination sind häufige Ursachen für kausale Abhängigkeiten zwischen Prozessen!
Problem
- Prinzip kritischer Abschnitt (Grundlagen BS):
- Sperrmechanismen stellen wechselseitigen Ausschluss bei der Benutzung exklusiver Betriebsmittel durch nebenläufige Prozesse sicher
- Benutzung von exklusiven sowie nichtentziehbaren Betriebsmitteln: kritischer Abschnitt
- Folge: Wenn ein Prozess einen kritischen Abschnitt betreten hat, darf er aus diesem nicht verdrängt werden (durch anderen Prozess, der dasselbe Betriebsmittel nutzen will)
- Konflikt: kritische Abschnitte vs. Echtzeit-Prioritäten
- Falls ein weiterer Prozess mit höherer Priorität ablauffähig wird und im gleichen kritischen Abschnitt arbeiten will, muss er warten bis niederpriorisierter Prozess kritischen Abschnitt verlassen hat
- (zeitweise) Prioritätsumkehr möglich! d.h. aus einer (Teil-) Menge von Prozessen muss derjenige mit höchster Priorität auf solche mit niedrigerer Priorität warten
Ursache der Prioritätsumkehr
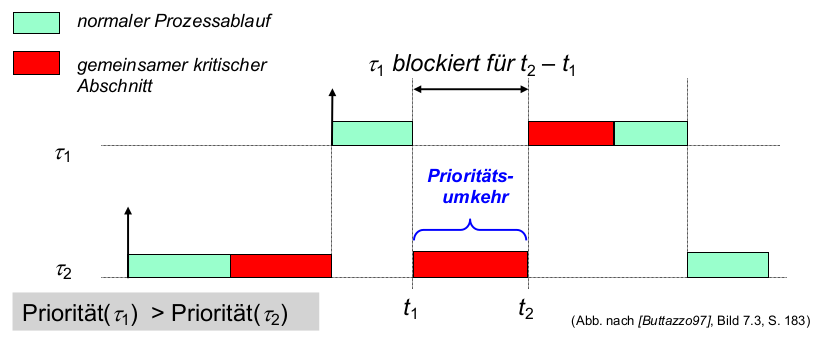
- Prioritätsumkehr bei Blockierung an nichtentziehbarem, exklusivem Betriebsmittel
\rightarrowunvermeidlich
Folgen der Prioritätsumkehr
- Kritisch bei zusätzlichen Prozessen mittlerer Priorität
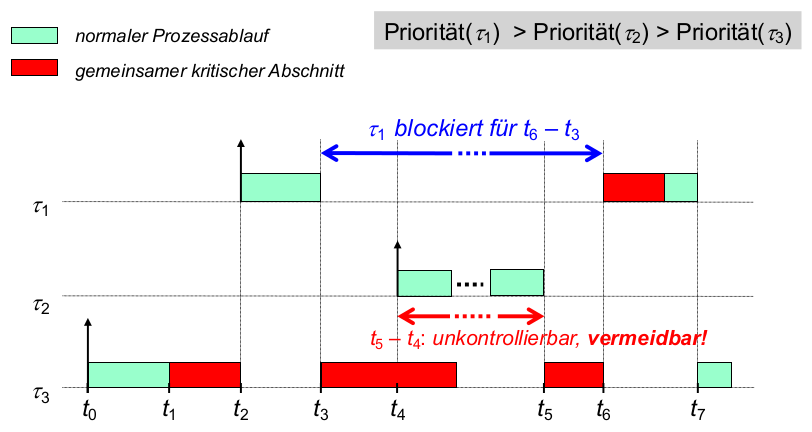
- Lösung: Priority Inheritance Protocol (PIP)
Lösung: Prioritätsvererbung
- ![Abb. nach [Buttazzo97] , Bild 7.6, S.188]
- ePrio ... effektive Priorität
Überlast
- Definition: kritische Situation - bei der die benötigte Menge an Prozessorzeit die Kapazität des vorhandenen Prozessors übersteigt
(U>1)- Folge: nicht alle Prozesse können Fristen einhalten
- Hauptrisiko: kritische Prozesse können Fristen nicht einhalten
\rightarrowGefährdung funktionaler und anderer nichtfkt. Eigenschaften (\rightarrowharte Fristen!) - Stichwort: ,,graceful degradation'' (,,würdevolle'' Verschlechterung) statt unkontrollierbarer Situation
\rightarrowWahrung von Determinismus
Wichtigkeit eines Prozesses
- Minimallösung: (lebenswichtig für Echtzeit-System)
- Unterscheidung zwischen Zeitbeschränkungen (Fristen) und tatsächlicher Wichtigkeit eines Prozesses für System
- Allgemein gilt:
- Wichtigkeit eines Prozesses ist unabhängig von seiner Periodendauer und irgendwelchen Fristen
- z.B. kann ein Prozess trotz späterer Frist viel wichtiger als anderer mit früherer Frist sein.
- Beispiel: Bei chemischem Prozess könnte Temperaturauswertung jede 10s wichtiger sein als Aktualisierung graphischer Darstellung an Nutzerkonsole jeweils nach 5s
Umgang mit Überlast: alltägliche Analogien
- Weglassen weniger wichtiger Aktionen
- ohne Frühstück aus dem Haus...
- kein Zähneputzen ...
- Wichtung vom Problem bzw. Aktivitätsträgern (hier: Personen) abhängig!
- Verkürzen von Aktivitäten
- Katzenwäsche...
- Kombinieren
- kein Frühstück + Katzenwäsche + ungekämmt
Wichtung von Prozessen
Behandlung:
- zusätzlicher Parameter V (Wert) für jeden Prozess/Thread einer Anwendung
- spezifiziert relative Wichtigkeit eines Prozesses (od. Thread) im Verhältnis zu anderen Prozessen (Threads) der gleichen Anwendung
- bei Scheduling: V stellt zusätzliche Randbedingung (primär: Priorität aufgrund von Frist, sekundär: Wichtigkeit)
Obligatorischer und optionaler Prozessanteil
- Aufteilung der Gesamtberechnung
(C_{ges})eines Prozesses in zwei Phasen - einfache Möglichkeit der Nutzung des Konzepts des anpassbaren Prozessorzeitbedarfs
- Prinzip:
- Bearbeitungszeitbedarf eines Prozesses zerlegt in
- obligatorischer Teil (Pflichtteil,
C_{ob}): muss unbedingt u. immer ausgeführt werden\rightarrowliefert bedingt akzeptables Ergebnis - optionaler Teil
(C_{opt}): nur bei ausreichender Prozessorkapazität ausgeführt\rightarrowverbessert durch obligatorischen Teil erzieltes Ergebnis
- obligatorischer Teil (Pflichtteil,
- Prinzip in unterschiedlicher Weise verfeinerbar
- Bearbeitungszeitbedarf eines Prozesses zerlegt in
Echtzeit-Interruptbehandlung
- Fristüberschreitung durch ungeeignete Interruptbearbeitung
- Lösung für Echtzeitsysteme ohne Fristüberschreitung
- Interrupt wird zunächst nur registriert (deterministischer Zeitaufwand)
- tatsächliche Bearbeitung der Interruptroutine muss durch Scheduler eingeplant werden
\rightarrowPop-up Thread 
Echtzeit-Speicherverwaltung
- Prinzip:
- Hauptanliegen: auch hier Fristen einhalten
- wie bei Interrupt-Bearbeitung und Prioritätsumkehr: unkontrollierbare Verzögerungen der Prozessbearbeitung (= zeitlicher Nichtdeterminismus) vermeiden!
- Ressourcenzuordnung, deswegen:
- keine Ressourcen-Zuordnung ,,on-demand'' (d.h. in dem Moment, wo sie benötigt werden) sondern ,,Pre-Allokation'' (= Vorab-Zuordnung)
- keine dynamische Ressourcenzuordnung (z.B. Hauptspeicher), sondern Zuordnung maximal benötigter Menge bei Pre-Allokation (
\rightarrowBS mit ausschließlich statischer Hauptspeicherallokation: TinyOS)
Hauptspeicherverwaltung
- bei Anwendung existierender Paging-Systeme
- durch unkontrolliertes Ein-/Auslagern ,,zeitkritischer'' Seiten (-inhalte): unkontrollierbare Zeitverzögerungen möglich!
- Technik hier: ,,Festnageln'' von Seiten im Speicher (Pinning, Memory Locking)
Sekundärspeicherverwaltung
-
Beispiel 1: FCFS Festplattenscheduling
- Anforderungsreihenfolge = 98, 183, 37, 122, 14, 124, 65, 67
- Zuletzt gelesener Block: 53
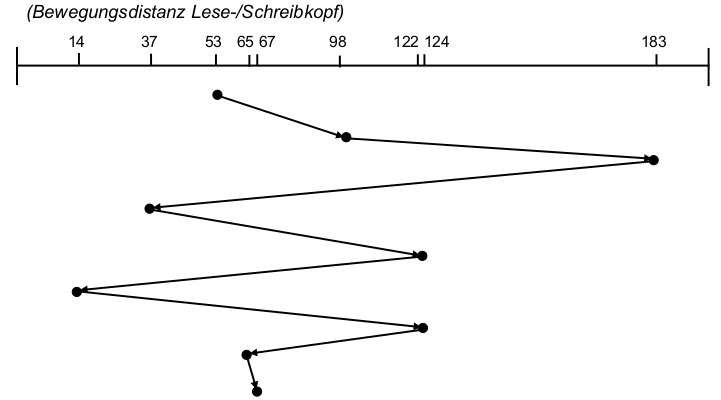
-
Beispiel 2: EDF Festplattenscheduling
- Anforderungsreihenfolge
t_1 = 98, 37, 124, 65 - Anforderungsreihenfolge
t_2 = 183, 122, 14, 67 - Zuletzt gelesener Block: 53
a_id_it_10 3 t_20 9 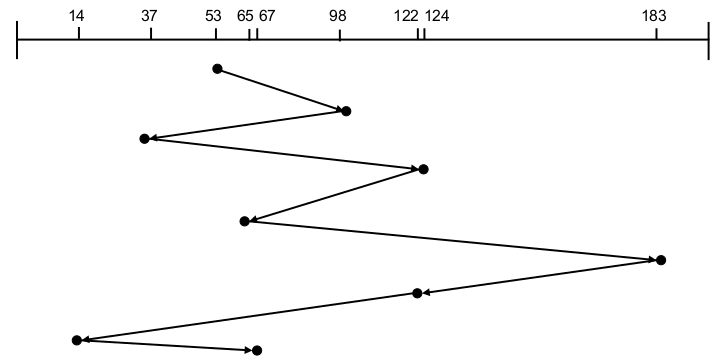
- Anforderungsreihenfolge
-
Primärziel: Wahrung der Echtzeitgarantien
- naheliegend: EA-Schedulingnach Fristen
\RightarrowEDF (wie Prozessor) - für Zugriffsreihenfolge auf Datenblöcke: lediglich deren Fristen maßgebend (weitere Regeln existieren nicht!)
- naheliegend: EA-Schedulingnach Fristen
-
Resultat bei HDDs:
- ineffiziente Bewegungen der Lese-/Schreibköpfe -ähnlich FCFS
- nichtdeterministische Positionierzeiten
- geringer Durchsatz
-
Fazit:
- Echtzeit-Festplattenscheduling
\rightarrowKompromiss zwischen Zeitbeschränkungen und Effizienz
- Echtzeit-Festplattenscheduling
-
bekannte Lösungen:
- Modifikation von EDF
- Kombination von EDF mit anderen Zugriffsstrategien
\rightarrow realisierte Strategien:
- SCAN-EDF (SCAN: Kopfbewegung nur in eine Richtung bis Mitte-/Randzylinder; EDF über alle angefragten Blöcke in dieser Richtung )
- Group Sweeping_ (SCAN mit nach Fristen gruppenweiser Bedienung)
- Mischstrategien
- Vereinfachung:
- o.g. Algorithmen i.d.R. zylinderorientiert
\rightarrowberücksichtigen bei Optimierung nur Positionierzeiten (Grund: Positionierzeit meist ≫Latenzzeit) 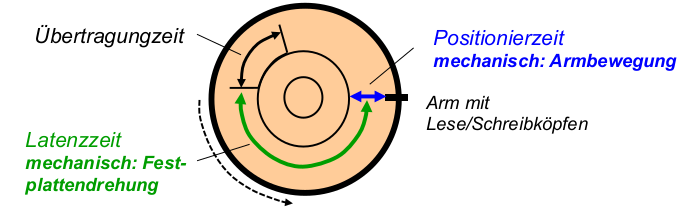
- o.g. Algorithmen i.d.R. zylinderorientiert
Kommunikation und Synchronisation
- zeitlichen Nichtdeterminismus vermeiden:
- Interprozess-Kommunikation
- Minimierung blockierender Kommunikationsoperationen
- indirekte Kommunikation
\rightarrowCAB zum Geschwindigkeitsausgleich - keine FIFO-Ordnungen (nach Fristen priorisieren)
- CAB ... Cyclic Asynchronous Buffer:
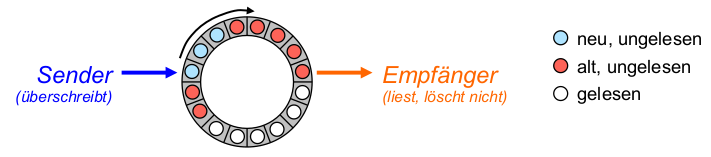
- Synchronisation
- keine FIFO-Ordnungen, z.B. bei Semaphor-Warteschlangen (vgl. o.)
Cyclic Asynchronous Buffer (CAB)
Kommunikation zwischen 1 Sender und n Empfängern:
- nach erstem Schreibzugriff: garantiert niemals undefinierte Wartezeiten durch Blockierung von Sender/Empfänger
- Lesen/Überschreiben in zyklischer Reihenfolge:
- Implementierung:
- MRW: Most-Recently-Written; Zeiger auf jüngstes, durch Sender vollständig geschriebenes Element
- LRW: Least-Recently-Written; Zeiger auf ältestes durch Sender geschriebenes Element
- Garantien:
- sowohl MRW als auch LRW können ausschließlich durch Sender manipuliert werden
\rightarrowkeine inkonsistenten Zeiger durch konkurrierende Schreibzugriffe! - sowohl MRW als auch LRW zeigen niemals auf ein Element, das gerade geschrieben wird
\rightarrowkeine inkonsistenten Inhalte durch konkurrierende Schreib-/Lesezugriffe!
- sowohl MRW als auch LRW können ausschließlich durch Sender manipuliert werden
- Regeln für Sender:
- muss nach jedem Schreiben MRW auf geschriebenes Element setzen
- muss bevor LRW geschrieben wird LRW inkrementieren
- Regel für Empfänger: muss immer nach Lesen von MRW als nächstes LRW anstelle des Listennachbarn lesen
- Sender-Regeln:
- anschaulich, ohne aktiven Empfänger
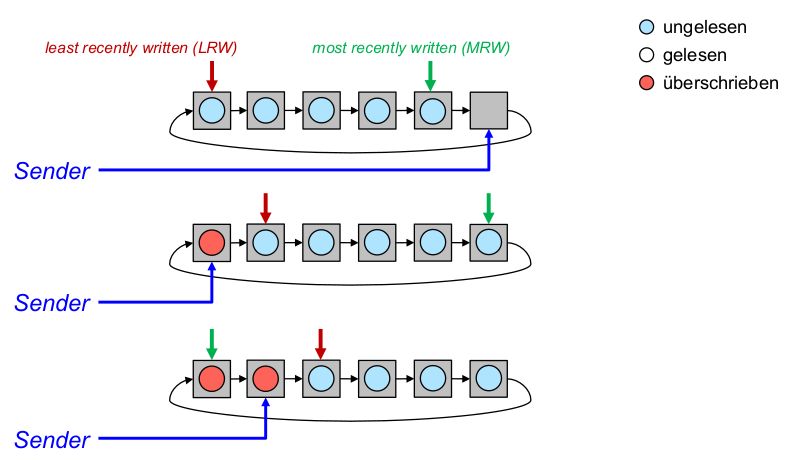
- Empfänger-Regel:
- anschaulich, ohne aktiven Sender
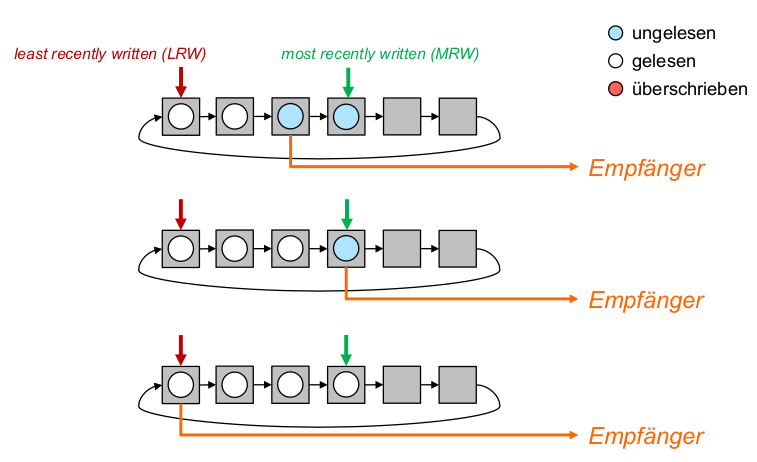
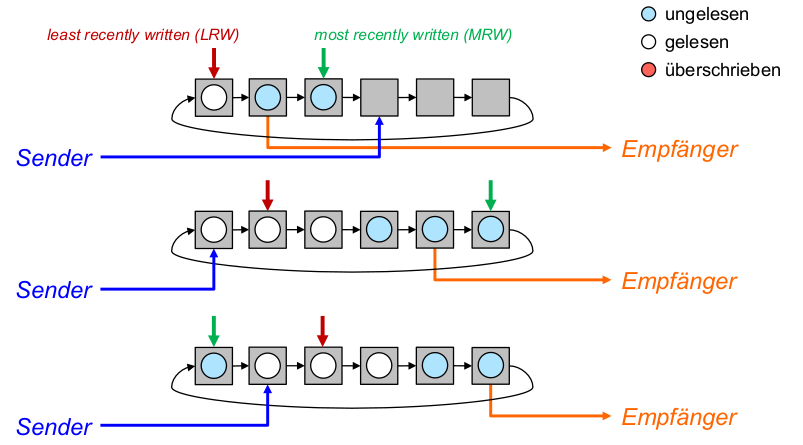
Sonderfall 1: Empfänger schneller als Sender
- nach Zugriff auf MRW muss auf Lesesequenz bei LRW fortgesetzt werden
\rightarrowtransparenter Umgang mit nicht-vollem Puffer - Abschwächung der Ordnungsgarantien:Empfänger weiß nur, dass Aktualität der Daten zwischen LRW und MRW liegt
- Empfänger (nach min. einem geschriebenen Element) niemals durch leeren Puffer blockiert
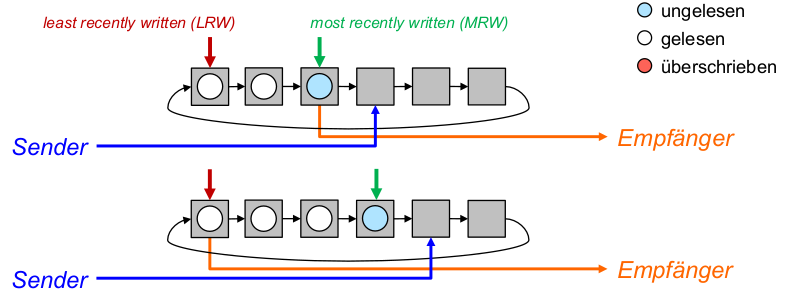
Sonderfall 2: Sender schneller als Empfänger
- Schreiben in Puffer grundsätzlich in Reihenfolge der Elemente
\rightarrowkeine blockierenden Puffergrenzen\rightarrowniemals Blockierung des Senders - keine Vollständigkeitsgarantien:Empfänger kann nicht sicher sein, eine temporal stetige Sequenz zu lesen
\rightarrowSzenarien, in denen Empfänger sowieso nur an aktuellsten Daten interessiert (z.B. Sensorwerte)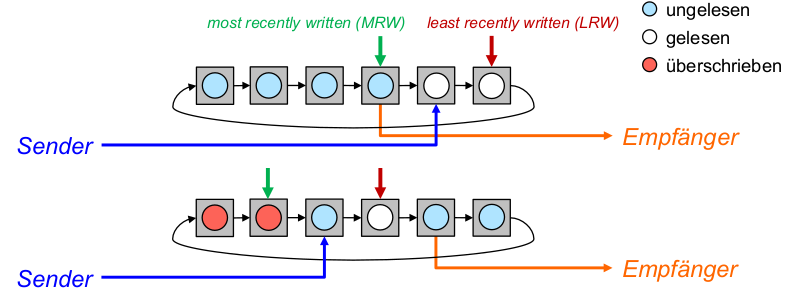
Konkurrierende Zugriffe:
- ... sind durch Empfänger immer unschädlich (da lesend)
- ... müssen vom Sender nach Inkrementieren von LRW nicht-blockierend erkannt werden (klassisches Semaphormodell ungeeignet)
- schnellerer Sender überspringtein gesperrtes Element durch erneutes Inkrementieren von LRW , muss MRW trotzdem nachziehen
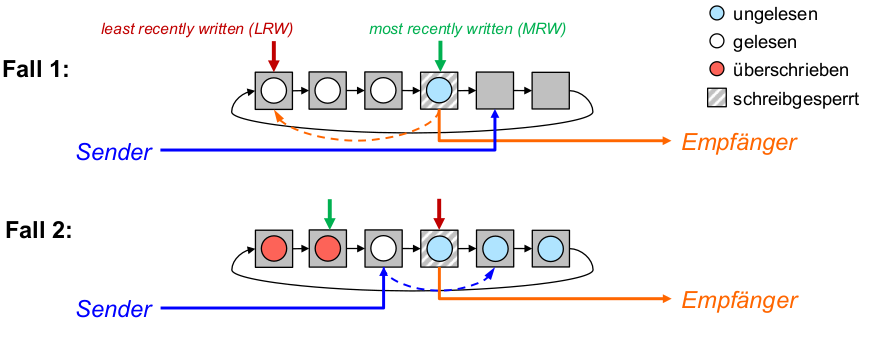
Architekturen und Beispiel-Betriebssysteme
- Architekturprinzipien:
- müssen Echtzeitmechanismen unterstützen; ermöglicht entsprechende Strategien zur Entwicklungs-oder Laufzeit (CPU-Scheduler, EA-Scheduler, IPC ...)
- müssen funktional geringe Komplexität aufweisen
\rightarrowtheoretische und praktische Beherrschung von Nichtdeterminismus- Theoretisch: Modellierung und Analyse (vgl. Annahmen für Scheduling-Planbarkeitsanalyse)
- Praktisch: Implementierung (vgl. RC-Scheduler, Prioritätsvererbung)
- Konsequenzen:
- Architekturen für komplementäre NFE:
- Sparsamkeit
\rightarrowhardwarespezifische Kernelimplementierung - Adaptivität
\rightarrowμKernel, Exokernel
- Sparsamkeit
- zu vermeiden:
- starke Hardwareabstraktion
\rightarrowVirtualisierungsarchitekturen - Kommunikation und Synchronisationskosten
\rightarrowverteilte BS - Hardwareunabhängigkeit und Portabilität
\rightarrowvgl. Mach
- starke Hardwareabstraktion
- Architekturen für komplementäre NFE:
Auswahl: Beispiel-Betriebssysteme
- wir kennen schon:
- funktional kleine Kernelimplementierung: TinyOS
- hardwarespezifischer μKernel: L4-Abkömmlinge
- Mischung aus beidem: RIOT
- Kommerziell bedeutender μKernel: QNX Neutrino
- weitere Vertreter:
- hardwarespezifische Makrokernel: VRTX, VxWorks
- μKernel: DRYOS, DROPS
- ,,Exokernel'' ...?
VRTX (Versatile Real-Time Executive)
- Entwickler:
- Hunter & Ready
- Eckdaten:
- Makrokernel
- war erstes kommerzielles Echtzeitbetriebssystem für eingebettete Systeme
- heutige Bedeutung eher historisch
- Nachfolger (1993 bis heute): Nucleus RTOS (Siemens)
- Anwendung:
- Eingebettete Systeme in Automobilen(Brems-und ABS-Controller)
- Mobiltelefone
- Geldautomaten
- Einsatzgebiete
- spektakulär: im Hubble-Weltraumteleskop
VxWorks
- Entwickler:
- Wind River Systems (USA)
- Eckdaten:
- modularer Makrokernel
- Konkurrenzprodukt zu VRTX
- Erfolgsfaktor: POSIX-konforme API
- ähnlich QNX: ,,skalierbarer'' Kernel,zuschneidbarauf Anwendungsdomäne (
\rightarrowAdaptivitätsansatz)
- Anwendung:
- eingebettete Systeme:
- industrielle Robotersteuerung
- Luft-und Raumfahrt
- Unterhaltungselektronik
- Einsatzgebiete
- Deep-Impact-Mission zur Untersuchung des Kometen Temple 1
- NASA Mars Rover
- SpaceX Dragon
DRYOS®
- Entwickler: Canon Inc.
- Eckdaten:
- Mikrokernel(Größe: 16 kB)
- Echtzeit-Middleware (Gerätetreiber
\rightarrowObjektive) - Anwendungen: AE-und AF-Steuerung/-Automatik, GUI, Bildbearbeitung, RAW-Konverter, ...
- POSIX-kompatible Prozessverwaltung
DROPS (Dresden Real-Time Operating System)
- Entwickler: TU Dresden, Lehrstuhl Betriebssysteme
- Eckdaten: Multi-Server-Architektur auf Basis eines L4-Mikrokerns
Adaptivität
Motivation
- als unmittelbar geforderte NFE:
- eingebettete Systeme
- Systeme in garstiger Umwelt (Meeresgrund, Arktis, Weltraum, ...)
- Unterstützung von Cloud-Computing-Anwendungen
- Unterstützung von Legacy-Anwendungen
- Beobachtung: genau diese Anwendungsdomänen fordern typischerweise auch andere wesentliche NFE (s.bisherige Vorlesung ...)
\rightarrowAdaptivität als komplementäre NFE zur Förderung von- Robustheit: funktionale Adaptivitätdes BS reduziert Kernelkomplexität (
\rightarrowkleiner, nicht adaptiver μKernel) - Sicherheit: wie Robustheit:TCB-Größe
\rightarrowVerifizierbarkeit, außerdem: adaptive Reaktion auf Bedrohungen - Echtzeitfähigkeit: adaptive Scheduling-Strategie (vgl. RC), adapt. Überlastbehandlung, adapt. Interruptbehandlungs-und Pinning-Strategien
- Performanz: Last-und Hardwareadaptivität
- Erweiterbarkeit: adaptive BS liefern oft hinreichende Voraussetzungen der einfachen Erweiterbarkeit von Abstraktionen, Schnittstellen, Hardware-Multiplexing-und -Schutzmechanismen ( Flexibility )
- Wartbarkeit: Anpassung des BS an Anwendungen, nicht umgekehrt
- Sparsamkeit: Lastadaptivitätvon CPUs, adaptive Auswahl von Datenstrukturen und Kodierungsverfahren
- Robustheit: funktionale Adaptivitätdes BS reduziert Kernelkomplexität (
Adaptivitätsbegriff
- Adaptability: ,,see Flexibility. '' [Marciniak94]
- Flexibility:
- ,,The ease with which a system or a component can be modified for use in applications or environments other than those for which it was specifically designed.'' (IEEE)
- für uns: entspricht Erweiterbarkeit
- Adaptivität: (unsere Arbeitsdefinition)
- Die Fähigkeit eines Systems, sich an ein breites Spektrum verschiedener Anforderungen anpassen zu lassen.
- = ... so gebaut zu sein, dass ein breites Spektrum verschiedener nicht funktionaler Eigenschaften unterstützt wird.
- letztere: komplementär zur allgemeinen NFE Adaptivität
Roadmap
- in diesem Kapitel: gleichzeitig Mechanismen und Architekturkonzepte
- Adaptivität jeweils anhand komplementärer Eigenschaften dargestellt:
- Exokernel: { Adaptivität } ∪ { Performanz, Echtzeitfähigkeit,Wartbarkeit, Sparsamkeit }
- Virtualisierung: { Adaptivität } ∪ { Wartbarkeit, Sicherheit, Robustheit }
- Container: { Adaptivität } ∪ { Wartbarkeit, Portabilität, Sparsamkeit }
- Beispielsysteme:
- Exokernel-Betriebssysteme: Aegis/ExOS, Nemesis, MirageOS
- Virtualisierung: Vmware, VirtualBox, Xen
- Containersoftware: Docker
Exokernelarchitektur
- Grundfunktion von Betriebssystemen
- physische Hardware darstellen als abstrahierte Hardware mit komfortableren Schnittstellen
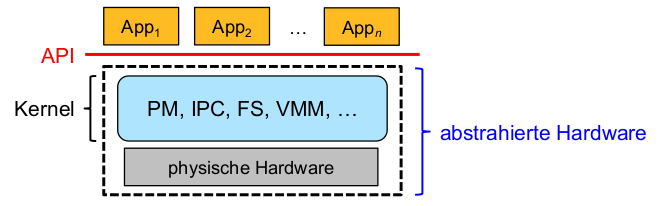
- Schnittstelle zu Anwendungen (API) : bietet dabei exakt die gleichen Abstraktionen der Hardware für alle Anwendungen an, z.B.
- Prozesse: gleiches Zustandsmodell, gleiches Threadmodell
- Dateien: gleiche Namensraumabstraktion
- Adressräume: gleiche Speicherverwaltung (VMM, Seitengröße, Paging)
- Interprozesskommunikation: gleiche Mechanismen für alle Anwendungsprozesse
- Problem:
- Implementierungsspielraumfür Anwendungen wird begrenzt:
- Vorteile domänenspezifischer Optimierungender Hardwarebenutzung können nicht ausgeschöpft werden
\rightarrowPerformanz, Sparsamkeit - die Implementierung existierender Abstraktionen kann bei veränderten Anforderungen nicht an Anwendungen angepasst werden
\rightarrowWartbarkeit - Hardwarespezifikationen, insbesondere des Zeitverhaltens (E/A, Netzwerk etc.), werden von Effekten des BS-Management überlagert
\rightarrowEchtzeitfähigkeit
- Idee von Exokernel-Architekturen:
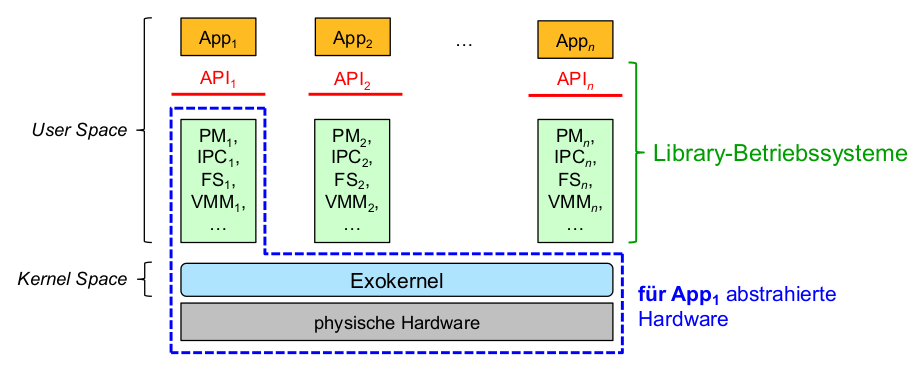
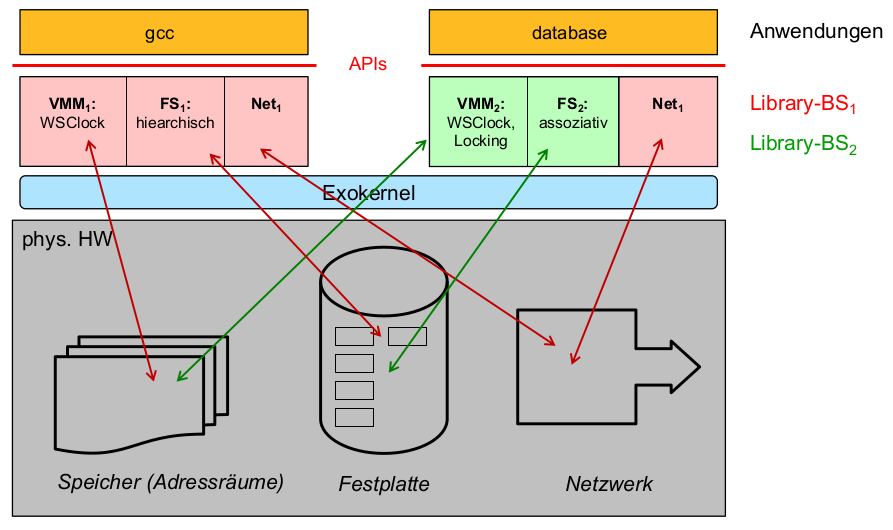
Exokernelmechanismen
- Designprinzip von Exokernelmechanismen:
- Trennung von Schutz und Abstraktion der Ressourcen
- Ressourcen-Schutz und -Multiplexing: verbleibt beim Betriebssystemkernel(dem Exokernel)
- Ressourcen-Abstraktion (und deren Management): zentrale Aufgabe der Library-Betriebssysteme
\rightarrowautonome Management-Strategien durch in Anwendungen importierte Funktionalität
- Resultat:
- systemweit(durch jeweiliges BS vorgegebene) starre Hardware-Abstraktionen vermieden
- anwendungsdomänenspezifische Abstraktionen sehr einfach realisierbar
- (Wieder-) Verwendung eigener und fremder Managementfunktionalität wesentlich erleichtert
\rightarrowkomplementäre NFEn! (Performanz, EZ-Fähigkeit, Sparsamkeit, ...)
- Funktion des Exokernels:
- Prinzip: definiert Low-level-Schnittstelle
- ,,low-level'' = so hardwarenah wie möglich, bspw. die logische Schnittstelle eines elektronischen Schaltkreises/ICs (
\rightarrowGerätetreiber\subseteqLibrary-BS!) - Bsp.: der Exokernelmuss den Hauptspeicher schützen, aber nicht verstehen, wie dieser verwaltet wird
\rightarrowAdressierung ermöglichen ohne Informationen über Seiten, Segmente, Paging-Attribute, ...
- ,,low-level'' = so hardwarenah wie möglich, bspw. die logische Schnittstelle eines elektronischen Schaltkreises/ICs (
- Library-Betriebssysteme: implementieren darauf jeweils geeignete anwendungsnahe Abstraktionen
- Bsp.: Adressraumsemantik, Seitentabellenlayout und -verwaltung, Paging-und Locking-Verfahren, ...
- Anwendungsprogrammierer: wählen geeignete Library-Betriebssysteme bzw. schreiben ihre eigenen Exokernelmechanismen
- Prinzip: definiert Low-level-Schnittstelle
- prinzipielle Exokernelmechanismen am Beispiel Aegis/ExOS [Engler+95]
- Der Exokernel...
- implementiert: Multiplexing der Hardware-Ressourcen
- exportiert: geschützte Hardware-Ressourcen
- Der Exokernel...
- minimal: drei Arten von Mechanismen
- Secure Binding: erlaubt geschützte Verwendung von Hardware-Ressourcen durch Anwendungen, Behandlung von Ereignissen
- Visible ResourceRevocation: beteiligt Anwendungen am Entzug von Ressourcen mittels (kooperativen) Ressourcen-Entzugsprotokolls
- Abort-Protokoll: erlaubt ExokernelBeendigung von Ressourcenzuordnungen bei unkooperativen Applikationen
Secure Binding
- Schutzmechanismus, der Autorisierung (
\rightarrowLibrary-BS)zur Benutzung einer Ressource von tatsächlicher Benutzung (\rightarrowExokernel) trennt - implementiert für den Exokernelerforderliches Zuordnungswissenvon (HW-)Ressource zu Mangement-Code (der im Library-BS implementiert ist)
\rightarrow''Binding'' in Aegis implementiert als Unix-Hardlinkauf Metadatenstruktur zu einem Gerät im Kernelspeicher ( ,,remember: everythingisa file...'' )- Zur Implementierung benötigt:
- Hardware-Unterstützung zur effizienten Rechteprüfung (insbes. HW-Caching)
- Software-Caching von Autorisierungsentscheidungen im Kernel (bei Nutzung durch verschiedene Library-BS)
- Downloadingvon Applikationscode in Kernel zur effizienten Durchsetzung (quasi: User-Space-Implementierung von Systemaufrufcode)
- einfach ausgedrückt: ,,Secure Binding'' erlaubt einem ExokernelSchutz von Ressourcen, ohne deren Semantik verstehen zu müssen.
Visible Resource Revocation
- monolithische Betriebssysteme: entziehen Ressourcen ,,unsichtbar'' (invisible), d.h. transparent für Anwendungen
- Vorteil: im allgemeinen geringere Latenzzeiten, einfacheres und komfortableres Programmiermodell
- Nachteil: Anwendungen(hier: die eingebetteten Library-BS) erhalten keine Kenntnis über Entzug,bspw. aufgrund von Ressourcenknappheit etc.
\rightarrowerforderliches Wissen für Management-Strategien!
- Exokernel-Betriebssysteme: entziehen(überwiegend) Ressourcen ,,sichtbar''
\rightarrowDialog zwischen Exokernel und Library-BS- Vorteil: effizientes Management durch Library-BS möglich (z.B. Prozessor: nur tatsächlich benötigte Register werden bei Entzug gespeichert)
- Nachteil : Performanz bei sehr häufigem Entzug, Verwaltungs-und Fehlerbehandlungsstrategien zwischen verschiedenen Library-BS müssen korrekt und untereinander kompatibelsein...
\rightarrowAbort - Protokoll notwendig, falls dies nicht gegeben ist
Abort - Protokoll
- Ressourcenentzug bei unkooperativen Library-Betriebssystemen ( Konflikt mit Anforderung durch andere Anwendung/deren Library-BS: Verweigerung der Rückgabe, zu späte Rückgabe, ...)
- notwendig aufgrund von Visible Ressource Revocation
- Dialog:
- Exokernel: ,,Bitte Seitenrahmen x freigeben.''
- Library-BS: ,,...''
- Exokernel: ,,Seitenrahmen x innerhalb von 50 μs freigeben!''
- Library-BS: ,,...''
- Exokernel: (führt Abort-Protokoll aus)
- Library-BS: X (,,Abort'' in diesem Bsp. = Anwendungsprozess terminieren)
- In der Praxis:
- harte Echtzeit-Fristen (,, innerhalb von 50 μs'' ) in den wenigsten Anwendungen berücksichtigt
\rightarrowAbort = lediglich Widerruf aller Secure Bindings der jeweiligen Ressource für die unkooperativeAnwendung, nicht deren Terminierung (= unsichtbarerRessourcenentzug)\rightarrowanschließend: Informieren des entsprechenden Library-BS
- ermöglicht sinnvolle Reaktion des Library-BS (in Library-BS wird ,,Repossession''-Exceptionausgelöst, so dass auf Entzug geeignet reagiert werden kann)
- bei zustandsbehafteten Ressourcen (
\rightarrowCPU): Exokernelkann diesen Zustand auf Hintergrundspeicher sichern\rightarrowManagement-Informationen zum Aufräumen durch Library-BS
- harte Echtzeit-Fristen (,, innerhalb von 50 μs'' ) in den wenigsten Anwendungen berücksichtigt
Exokernelperformanz
- Was macht Exokern-Architekturen adaptiv(er)?
- Abstraktionen und Mechanismen des Betriebssystems können den Erfordernissen der Anwendungen angepasst werden
- (erwünschtes) Ergebnis: beträchtliche Performanzsteigerungen (vgl. komplementäre Ziel-NFE: Performanz, Echtzeitfähigkeit, Wartbarkeit, Sparsamkeit )
Performanzstudien
- Aegis mit Library-BS ExOS (MIT: Dawson Engler, Frans Kaashoek)
- Xok mit Library-BS ExOS (MIT)
- Nemesis (Pegasus-Projekt, EU)
- XOmB (U Pittsburgh)
- ...
Aegis/ExOSals erweiterte Machbarkeitsstudie [Engler+95]
- machbar: sehr effiziente Exokerne
- Grundlage: begrenzte Anzahl einfacher Systemaufrufe (Größenordnung ~10) und Kernel-interne Primitiven (,,Pseudo-Maschinenanweisungen''), die enthalten sein müssen
- machbar: sicheres Hardware-Multiplexing auf niedriger Abstraktionsebene (,,low-level'') mit geringem Overhead
- traditionelle Abstraktionen (VMM, IPC) auf Anwendungsebene effizient implementierbar
\rightarroweinfache Erweiterbarkeit, Spezialisierbarkeitbzw. Ersetzbarkeit dieser Abstraktionen - für Anwendungen: hochspezialisierte Implementierungen von Abstraktionen generierbar, die genau auf Funktionalität und Performanz-Anforderungen dieser Anwendung zugeschnitten
- geschützte Kontrollflussübergabe: als IPC-Primitive im Aegis-Kernel, 7-mal schnellerals damals beste Implementierung (vgl. [Liedtke95], Kap. 3)
- Ausnahmebehandlung bei Aegis: 5-mal schneller als bei damals bester Implementierung
- durch Aegis möglich: Flexibilität von ExOS, die mit Mikrokernel-Systemen nicht erreichbar ist:
- Bsp. VMM: auf Anwendungsebene implementiert, wo diese sehr einfach mit DSM-Systemen u. Garbage-Kollektoren verknüpfbar
- Aegis erlaubt Anwendungen Konstruktion effizienter IPC-Primitiven (∆ μKernel: nicht vertrauenswürdige Anwendungen könnenkeinerlei spezialisierte IPC-Primitiven nutzen, geschweige denn selbst implementieren)
Xok/ExOS
- praktische Weiterentwicklung von Aegis: Xok
- für x86-Hardware implementiert
- Kernel-Aufgaben (wie gehabt): Multiplexing von Festplatte, Speicher, Netzwerkschnittstellen, ...
- Standard Library-BS (wie bei Aegis): ExOS
- ,,Unix as a Library''
- Plattform für unmodifizierte Unix-Anwendungen (csh, perl, gcc, telnet, ftp, ...)
- z.B. Library-BS zum Dateisystem-Management: C-FFS
- hochperformant (im Vergleich mit Makrokernel-Dateisystem-Management)
- Abstraktionen und Operationen auf Exokernel-Basis (u.a.): Inodes, Verzeichnisse, physische Dateirelokation(
\rightarrowzusammenhängendes Lesen) - Secure Bindings für Metadaten-Modifikation
- Forschungsziele:
- Aegis: Proof-of-Concept
- XOK: Proof-of-Feasibility (Performanz)
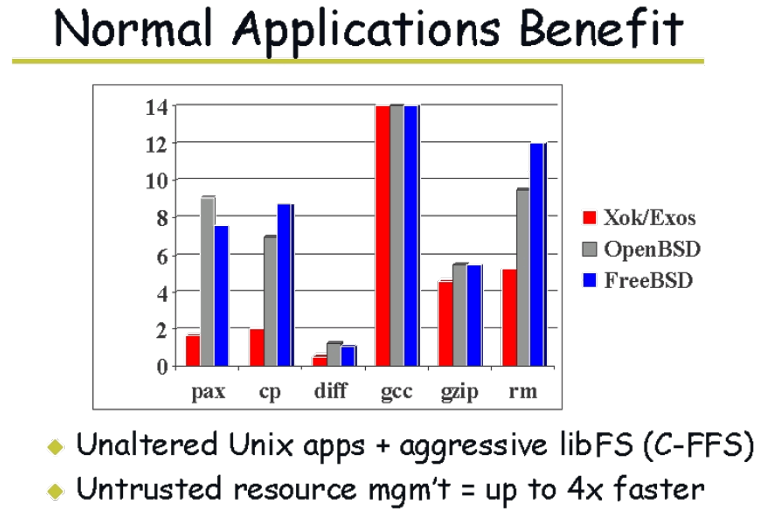
Zwischenfazit: Exokernelarchitektur
- Ziele:
- Performanz, Sparsamkeit: bei genauer Kenntnis der Hardware ermöglicht deren direkte BenutzungAnwendungsentwicklern Effizienzoptimierung
- Wartbarkeit: Hardwareabstraktionen sollen flexibel an Anwendungsdomänen anpassbar sein, ohne das BS modifizieren/wechseln zu müssen
- Echtzeitfähigkeit: Zeitverhaltendes Gesamtsystems durch direkte Steuerung der Hardware weitestgehend durch (Echtzeit-) Anwendungen kontrollierbar
- Idee:
- User-Space:anwendungsspezifische Hardwareabstraktionen im User-Space implementiert
- Kernel-Space:nur Multiplexing und Schutz der HW-Schnittstellen
- in der Praxis: kooperativer Ressourcenentzug zwischen Kernel, Lib. OS
- Ergebnisse:
- hochperformanteHardwarebenutzung durch spezialisierte Anwendungen
- funktional kleiner Exokernel(
\rightarrowSparsamkeit, Korrektheit des Kernelcodes ) - flexible Nutzung problemgerechterHW-Abstraktionen ( readymade Lib. OS)
- keine Isolation von Anwendungen (
\rightarrowParallelisierbarkeit: teuer und mit schwachen Garantien;\rightarrowRobustheit und Sicherheit der Anwendungen: nicht umsetzbar)
Virtualisierung
- Ziele (zur Erinnerung):
- Adaptivität
- Wartbarkeit, Sicherheit, Robustheit
\rightarrowauf gleicher Hardware mehrere unterschiedliche Betriebssysteme ausführbar machen
- Idee:
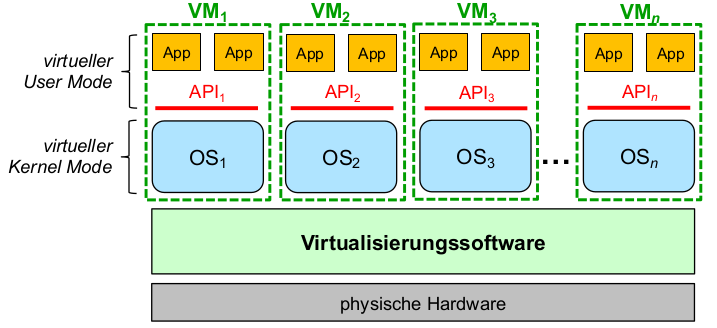
Ziele von Virtualisierung
- Adaptivität: ( ähnlich wie bei Exokernen)
- können viele unterschiedliche Betriebssysteme - mit jeweils unterschiedlichen Eigenschaften ausgeführt werden damit können: Gruppen von Anwendungen auf ähnliche Weise jeweils unterschiedliche Abstraktionen etc. zur Verfügung gestellt werden
- Wartbarkeit:
- Anwendungen - die sonst nicht gemeinsam auf gleicher Maschine lauffähig - auf einer phyischenMaschine ausführbar
- ökonomische Vorteile: Cloud-Computing, Wartbarkeit von Legacy-Anwendungen
- Sicherheit:
- Isolation von Anwendungs-und Kernelcode durch getrennte Adressräume (wie z.B. bei Mikrokern-Architekturen)
- somit möglich:
- Einschränkung der Fehlerausbreitung
\rightarrowangreifbare Schwachstellen - Überwachung der Kommunikation zwischen Teilsystemen
- Einschränkung der Fehlerausbreitung
- darüber hinaus: Sandboxing (vollständig von logischer Ablaufumgebung isolierte Software, typischerweise Anwendungen
\rightarrowsiehe z.B. Cloud-Computing)
- Robustheit:
- siehe Sicherheit!
Architekturvarianten - drei unterschiedliche Prinzipien:
- Typ-1 - Hypervisor ( früher: VMM - ,,Virtual MachineMonitor'' )
- Typ-2 - Hypervisor
- Paravirtualisierung
Typ-1 - Hypervisor
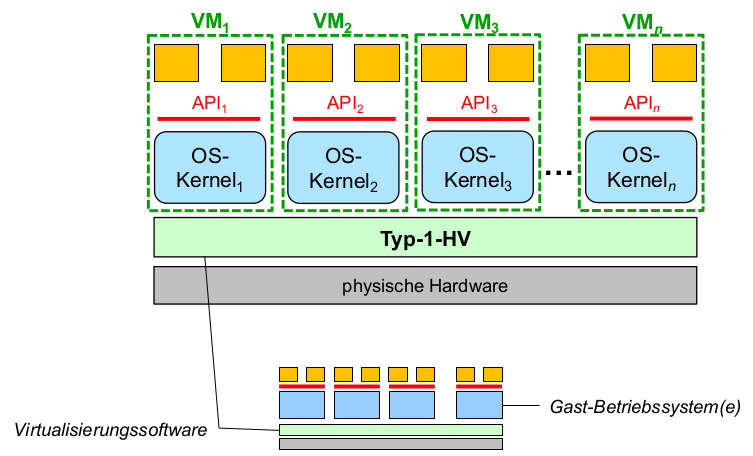
- Idee des Typ- 1 - Hypervisors:
- Kategorien traditioneller funktionaler Eigenschaften von BS:
- Multiplexing & Schutz der Hardware (ermöglicht Multiprozess-Betrieb)
- abstrahierte Maschine** mit ,,angenehmerer'' Schnittstelle als die reine Hardware (z.B. Dateien, Sockets, Prozesse, ...)
- Kategorien traditioneller funktionaler Eigenschaften von BS:
- Typ- 1 - Hypervisor trennt beide Kategorien:
- läuft wie ein Betriebssystem unmittelbar über der Hardware
- bewirkt Multiplexing der Hardware, liefert aber keine erweiterte Maschine** an Anwendungsschicht
\rightarrow,,Multi-Betriebssystem-Betrieb''
- Bietet mehrmals die unmittelbare Hardware-Schnittstelle an, wobei jede Instanz eine virtuelle Maschine jeweils mit den unveränderten Hardware-Eigenschaften darstellt (Kernel u. User Mode, Ein-/Ausgaben usw.).
- Ursprünge: Time-Sharing an Großrechnern
- Standard-BS auf IBM-Großrechner System/360: OS/360
- reines Stapelverarbeitungs-Betriebssystem (1960er Jahre)
- Nutzer (insbes. Entwickler) strebten interaktive Arbeitsweise an eigenem Terminal an
\rightarrowtimesharing (MIT, 1962: CTSS)- IBM zog nach: CP/CMS, später VM/370
\rightarrowz/VM - CP: Control Program
\rightarrowTyp- 1 - Hypervisor - CMS: ConversationalMonitor System
\rightarrowGast-BS
- IBM zog nach: CP/CMS, später VM/370
- CP lief auf ,,blanker'' Hardware (Begriff geprägt: ,,bare metal hypervisor'' )
- lieferte Menge virtueller Kopiender System/360-Hardware an eigentliches Timesharing-System
- je eines solche Kopie pro Nutzer
\rightarrowunterschiedliche BS lauffähig (da jede virtuelle Maschine exakte Kopie der Hardware) - in der Praxis: sehr leichtgewichtiges, schnelles Einzelnutzer-BS als Gast
\rightarrowCMS (heute wäre das wenig mehr als ein Terminal-Emulator...)
- heute: Forderungen nach Virtualisierung von Betriebssystemen
- seit 1980er: universeller Einsatz des PC für Einzelplatz- und Serveranwendungen
\rightarrowveränderte Anforderungen an Virtualisierung - Wartbarkeit: vor allem ökonomische Gründe:
- Anwendungsentwicklung und -bereitstellung: verschiedene Anwendungen in Unternehmen, bisher auf verschiedenen Rechnern mit mehreren (oft verschiedenen) BS, auf einem Rechner entwickeln und betreiben (Lizenzkosten!)
- Administration: einfache Sicherung, Migration virtueller Maschinen
- Legacy-Software
- später: Sicherheit, Robustheit
\rightarrowCloud-Computing-Anwendungen
- seit 1980er: universeller Einsatz des PC für Einzelplatz- und Serveranwendungen
- ideal hierfür: Typ- 1 - Hypervisor
- ✓ Gast-BS angenehm wartbar
- ✓ Softwarekosten beherrschbar
- ✓ Anwendungen isolierbar
Hardware-Voraussetzungen
- Voraussetzungen zum Einsatz von Typ-1-HV
- Ziel: Nutzung von Virtualisierung auf PC-Hardware
- systematische Untersuchung der Virtualisierbarkeit von Prozessoren bereits 1974 durch Popek & Goldberg [Popek&Goldberg74]
- Ergebnis:
- Gast-BS (welches aus Sicht der CPU im User Mode - also unprivilegiert läuft) muss sicher sein können, dass privilegierte Instruktionen (Maschinencode im Kernel) ausgeführt werden
- dies geht nur, wenn tatsächlich der HV diese Instruktionen ausführt!
- dies geht nur, wenn CPU bei jeder solchen Instruktion im Nutzermodus Kontextwechsel zum HV ausführen, welcher Instruktion emuliert!
- virtualisierbare Prozessoren bis ca. 2006:
- ✓ IBM-Architekturen(bekannt: PowerPC, bis 2006 Apple-Standard)
- ✗ Intel x86-Architekturen (386, Pentium, teilweise Core i)
Privilegierte Instruktionen ohne Hypervisor
- kennen wir schon: Instruktion für Systemaufrufe
- User Mode: Anwendung bereitet Befehl und Parameter vor
- User Mode: Privilegierte Instruktion (syscall/Trap - Interrupt)
\rightarrowCPU veranlasst Kontext-und Privilegierungswechsel, Ziel: BS-Kernel - Kernel Mode: BS-Dispatcher (Einsprungpunkt für Kernel-Kontrollfluss) behandelt Befehl und Parameter, ruft weitere privilegierte Instruktionen auf (z.B. EA-Code)

Privilegierte Instruktionen mit Typ- 1 - Hypervisor(1)
- zum Vergleich: Instruktion für Systemaufrufe des Gast-BS
- User Mode: Anwendung bereitet Befehl und Parameter vor
- User Mode: Trap
\rightarrowKontext-und Privilegierungswechsel, Ziel: Typ-1-HV - Kernel Mode: HV-Dispatcher ruft Dispatcher im Gast-BS auf
- User Mode: BS-Dispatcher behandelt Befehl und Parameter, ruft weitere privilegierte Instruktionenauf (z.B. EA-Code)
\rightarrowKontext-und Privilegierungswechsel, Ziel: Typ-1-HV - Kernel Mode: HV führt privilegierte Instruktionen anstelle des Gast-BS aus
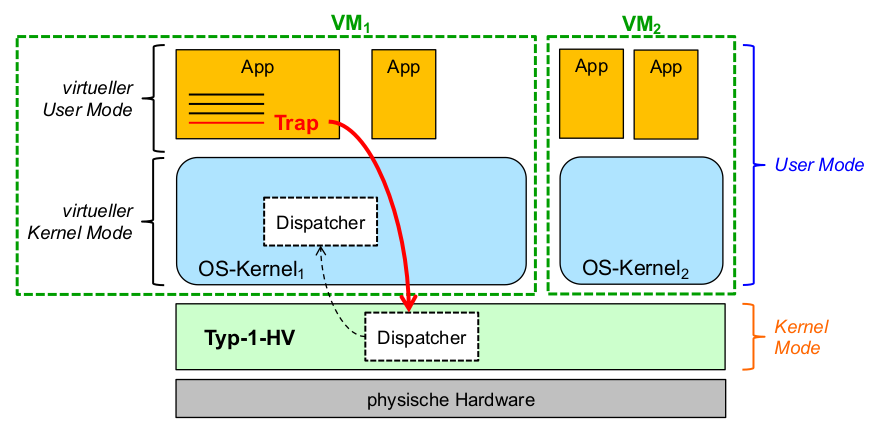
Sensible und privilegierte Instruktionen: Beobachtungen an verschiedenen Maschinenbefehlssätzen: [Popek&Goldberg74]
\existsMenge an Maschinenbefehlen, die nur im Kernel Mode ausgeführt werden dürfen (Befehle zur Realisierung von E/A, Manipulation der MMU, ...)\rightarrowsensible Instruktionen
\existsMenge an Maschinenbefehlen, die Wechsel des Privilegierungsmodus auslösen (x86: Trap ), wenn sie im User Mode ausgeführt werden\rightarrowprivilegierte Instruktionen
- Prozessor ist virtualisierbarfalls (notw. Bed.): sensible Instruktionen
\subseteqprivilegierte Instruktionen - Folge: jeder Maschinenbefehl, der im Nutzermodus nicht erlaubt ist, muss einen Privilegierungswechsel auslösen (z.B. Trap generieren)
- kritische Instruktionen = sensible Instruktionen \ privilegierte Instruktionen
- Befehle, welche diese Bedingung verletzen
\rightarrowExistenz im Befehlssatz führt zu nicht-virtualisierbarem Prozessor
- Befehle, welche diese Bedingung verletzen
- Beispiele für sensible Instruktionen bei Intel x86:
- hlt: Befehlsabarbeitung bis zum nächsten Interrupt stoppen
- invlpg: TLB-Eintrag für Seite invalidieren
- lidt: IDT (interrupt descriptor table) neu laden
- mov auf Steuerregistern
- ...
- Beispiel: Privilegierte Prozessorinstruktionen
- Bsp.: write - Systemaufruf
- Anwendungsprogramm schreibt String in Puffer eines Ausgabegeräts ohne Nutzung der libc Standard-Bibliothek:
asm ( "int $0x80" ); /* interrupt 80 (trap) */ - Interrupt-Instruktion veranlasst Prozessor zum Kontextwechsel: Kernelcode im privilegierten Modus ausführen
Vergleich: Privilegierte vs. sensible Instruktionen
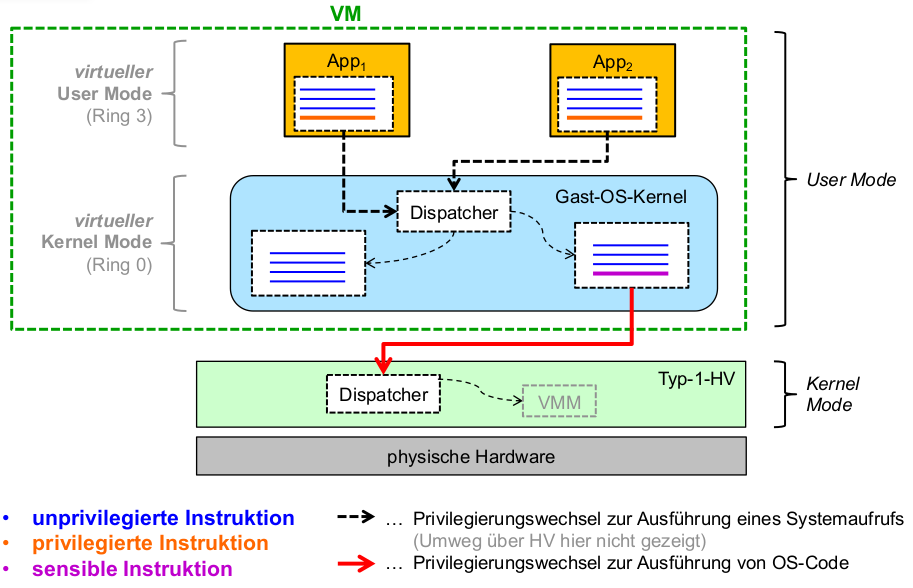
Folgen für Virtualisierung
- privilegierte Instruktionen bei virtualisierbaren Prozessoren
- bei Ausführung einer privilegierten Instruktion in virtueller Maschine: immer Kontrollflussübergabe an im Kernel-Modus laufende Systemsoftware - hier Typ-1-HV
- HV kann (anhand des virtuellen Privilegierungsmodus) feststellen:
- ob sensible Anweisung durch Gast-BS
- oder durch Nutzerprogramm (Systemaufruf!) ausgelöst
- Folgen:
- privilegierte Instruktionen des Gast-Betriebssystems werden ausgeführt
\rightarrow,,trap-and-emulate'' - Einsprung in Betriebssystem, hier also Einsprung in Gast-Betriebssystem
\rightarrowUpcall durch HV
- privilegierte Instruktionen des Gast-Betriebssystems werden ausgeführt
- privilegierte Instruktionen bei nicht virtualisierbaren Prozessoren
- solche Instruktionen typischerweise ignoriert!
Intel-Architektur ab 386
- dominant im PC-und Universalrechnersegment ab 1980er
- keine Unterstützung für Virtualisierung ...
- kritische Instruktionen im User Mode werden von CPU ignoriert
- außerdem: in Pentium-Familie konnte Kernel-Code explizit feststellen, ob er im Kernel- oder Nutzermodus läuft
\rightarrowGast-BS trifft (implementierungsabhängig) evtl. fatal fehlerhafte Entscheidungen - Diese Architekturprobleme (bekannt seit 1974) wurden 20 Jahre lang im Sinne von Rückwärtskompatibilität auf Nachfolgeprozessoren übertragen ...
- erste virtualisierungsfähige Intel-Prozessorenfamilie (s. [Adams2006] ): VT, VT-x® (2005)
- dito für AMD: SVM, AMD-V® (auch 2005)
Forschungsarbeit 1990er Jahre
- verschiedene akademische Projekte zur Virtualisierung bisher nicht virtualisierbarer Prozessoren
- erstes und vermutlich bekanntestes: DISCO- Projekt der University of Stanford
- Resultat: letztlich VMware (heute kommerziell) und Typ-2-Hypervisors...
Typ-2-Hypervisor
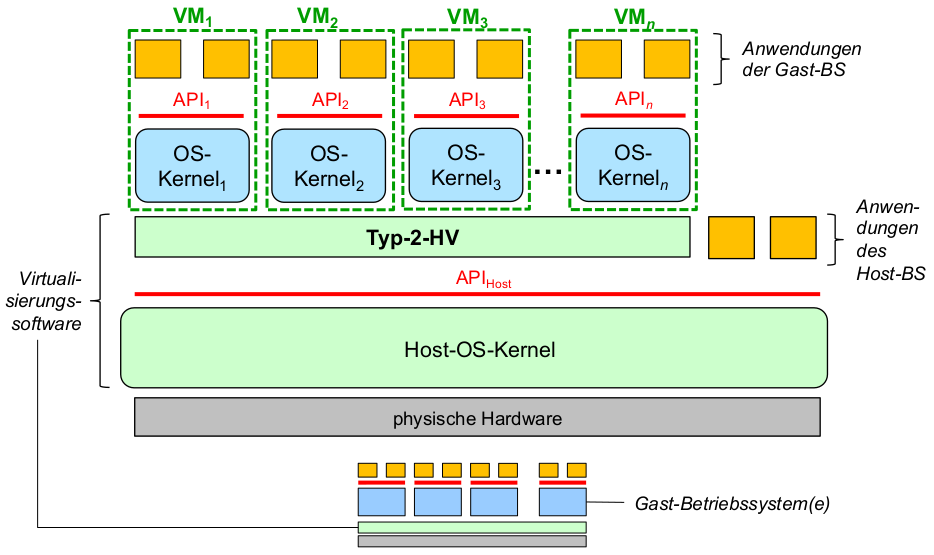
Virtualisierung ohne Hardwareunterstützung:
- keine Möglichkeit, trap-and-emulate zu nutzen
- keine Möglichkeit, um
- korrekt (bei sensiblen Instruktionen im Gast-Kernel) den Privilegierungsmodus zu wechseln
- den korrekten Code im HV auszuführen
Übersetzungsstrategie in Software:
- vollständige Übersetzung des Maschinencodes, der in VM ausgeführt wird, in Maschinencode, der im HV ausgeführt wird
- praktische Forderung: HV sollte selbst abstrahierte HW-Schnittstelle zur Ausführung des (komplexen!) Übersetzungscodes zur Verfügung haben (z.B. Nutzung von Gerätetreibern)
\rightarrowTyp-2-HV als Kompromiss:- korrekte Ausführung von virtualisierter Software auf virtualisierter HW
- beherrschbare Komplexität der Implementierung
aus Nutzersicht
- läuft als gewöhnlicher Nutzer-Prozess auf Host-Betriebssystem (z.B. Windows oder Linux)
- VMware bedienbarwie physischer Rechner (bspw. erwartet Bootmedium in virtueller Repräsentation eines physischen Laufwerks)
- persistente Daten des Gast-BS auf virtuellem Speichermedium ( tatsächlich: Image-Datei aus Sicht des Host-Betriebssystems)
Mechanismus: Code-Inspektion
- Bei Ausführung eines Binärprogramms in der virtuellen Maschine (egal ob Bootloader, Gast-BS-Kernel, Anwendungsprogramm): zunächst inspiziert Typ-2-HV den Code nach Basisblöcken
- Basisblock: Befehlsfolge, die mit privilegierten Befehlen oder solchen Befehlen abgeschlossen ist, die den Kontrollfluss ändern (sichtbar an Manipulation des Programm-Zählers eip), z.B. jmp, call, ret.
- Basisblöcke werden nach sensiblen Instruktionen abgesucht
- diese werden jeweils durchAufruf einer HV-Prozedur ersetzt, die jeweilige Instruktion behandelt
- gleiche Verfahrensweise mit letzter Instruktion eines Basis-Blocks
Mechanismus: Binary Translation (Binärcodeübersetzung)
- modifizierter Basisblock: wird innerhalbdes HVin Cachegespeichert und ausgeführt
- Basisblock ohne sensible Instruktionen: läuft unter Typ-2-HV exakt so schnell wie unmittelbar auf Hardware (weil er auch tatsächlich unmittelbar auf der Hardware läuft, nur eben im HV-Kontext)
- sensible Instruktionen: nach dargestellter Methode abgefangen und emuliert
\rightarrowdabei hilft jetzt das Host-BS (z.B. durch eigene Systemaufrufe, Gerätetreiberschnittstellen)
Mechanismus: Caching von Basisblöcken
- HV nutzt zwei parallel arbeitende Module (Host-BS-Threads!):
- Translator: Code-Inspektion, Binary Translation
- Dispatcher: Basisblock-Ausführung
- zusätzliche Datenstruktur: Basisblock-Cache
- Dispatcher: sucht Basisblock mit jeweils nächster auszuführender Befehlsadresse im Cache; falls miss
\rightarrowsuspendieren (zugunsten Translator) - Translator: schreibt Basisblöcke in Basisblock-Cache
- Annahme: irgendwann ist Großteil des Programms im Cache, dieses läuft dann mit nahezu Original-Geschwindigkeit (theoretisch)
Performanzmessungen
- zeigen gemischtes Bild: Typ2-HV keinesfalls so schlecht, wie einst erwartet wurde
- qualitativer Vergleich mit virtualisierbarer Hardware (Typ1-Hypervisor):
- ,,trap-and-emulate,,: erzeugt Vielzahl von Traps
\rightarrowKontextwechsel zwischen jeweiliger VM und HV - insbesondere bei Vielzahl an VMs sehr teuer: CPU-Caches, TLBs, Heuristiken zur spekulativen Ausführung werden verschmutzt
- wenn andererseits sensible Instruktionen durch Aufruf von VMware-Prozeduren innerhalb des ausführenden Programms ersetzt: keine Kontextwechsel-Overheads
Studie: (von Vmware) [Adams&Agesen06]
- last-und anwendungsabhängig kann Softwarelösung sogar Hardwarelösung übertreffen
- Folge: viele moderne Typ1-HV benutzen aus Performanzgründen ebenfalls Binary Translation
Paravirtualisierung
Funktionsprinzip
- ... unterscheidet sich prinzipiell von Typ-1/2-Hypervisor
- wesentlich: Quellcode des Gast-Betriebssystems modifiziert
- sensible Instruktionen: durch Hypervisor-Calls ersetzt
- Folge: Gast-Betriebssystem arbeitet jetzt vollständig wie Nutzerprogramm, welches Systemaufrufe zum Betriebssystem (hier dem Hypervisor) ausführt
- dazu:
- Hypervisor: muss geeignetes Interface definieren (HV-Calls)
\rightarrowMenge von Prozedur-Aufrufen zur Benutzung durch Gast-Betriebssystem- bilden eine HV-API als Schnittstelle für Gast-Betriebssysteme (nicht für Nutzerprogramme!)
- mehr dazu: Xen
Verwandtschaft mit Mikrokernel-Architekturen
- Geht man vom Typ-1-HV noch einen Schritt weiter ...
- und entfernt alle sensiblen Instruktionen aus Gast-Betriebssystem ...
- und ersetzt diese durch Hypervisor-Aufrufe, um Systemdienste wie E/A zu benutzen, ...
- hat man praktisch den Hypervisor in Mikrokernel transformiert.
- ... und genau das wird auch schon gemacht: $L^4$Linux (TU Dresden)
- Basis: stringente
L^4\muKernel-Implementierung (Typ-1-HV-artiger Funktionsumfang) - Anwendungslaufzeitumgebung: paravirtualisierter Linux-Kernel als Serverprozess
- Ziele: Isolation (Sicherheit, Robustheit), Echtzeitfähigkeit durch direktere HW-Interaktion (vergleichbar Exokernel-Ziel)
- Basis: stringente
Zwischenfazit Virtualisierung
- Ziele: Adaptivität komplementär zu...
- Wartbarkeit : ökonomischer Betrieb von Cloud-und Legacy-Anwendungen ohne dedizierte Hardware
- Sicherheit : sicherheitskritische Anwendungen können vollständig von nichtvertrauenswürdigen Anwendungen (und untereinander) isoliert werden
- Robustheit : Fehler in VMs (= Anwendungsdomänen) können nicht andere VMs beeinträchtigen
- Idee: drei gängige Prinzipien:
- Typ-1-HV: unmittelbares HW-Multiplexing, trap-and-emulate
- Typ-2-HV: HW-Multiplexing auf Basis eines Host-OS, binarytranslation
- Paravirtualisierung: Typ-1-HV für angepasstes Gast-OS, kein trap-and-emulate nötig
\rightarrowHV ähnelt $\mu$Kern
- Ergebnisse:
- ✓ VMs mit individuell anpassbarer Laufzeitumgebung
- ✓ isolierteVMs
- ✓ kontrollierbare VM-Interaktion (untereinander und mit HW)
- ✗ keine hardwarespezifischen Optimierungen aus VM heraus möglich
\rightarrowPerformanz, Echtzeitfähigkeit, Sparsamkeit!
Container
Ziele:
- Adaptivität , im Dienste von ...
- ... Wartbarkeit: einfachen Entwicklung, Installation, Rekonfiguration durch Kapselung von
- Anwendungsprogrammen
-
- durch sie benutzte Bibliotheken
-
- Instanzen bestimmter BS-Ressourcen
- ... Portabilität: Betrieb von Anwendungen, die lediglich von einem bestimmten BS-Kernel abhängig sind (nämlich ein solcher, der Container unterstützt); insbesondere hinsichtlich:
- Abhängigkeitskonflikten (Anwendungen und Bibliotheken)
- fehlenden Abhängigkeiten (Anwendungen und Bibliotheken)
- Versions-und Namenskonflikten
- ... Sparsamkeit: problemgerechtes ,,Packen,, von Anwendungen in Container
\rightarrowReduktion an Overhead: selten (oder gar nicht) genutzter Code, Speicherbedarf, Hardware, ...
Idee:
- private Sichten (Container) bilden = private User-Space-Instanzen für verschiedene Anwendungsprogramme
- Kontrolle dieser Container i.S.v. Multiplexing, Unabhängigkeit und API: BS-Kernel
- somit keine Form der BS-Virtualisierung, eher: ,,User-Space-Virtualisierung,,
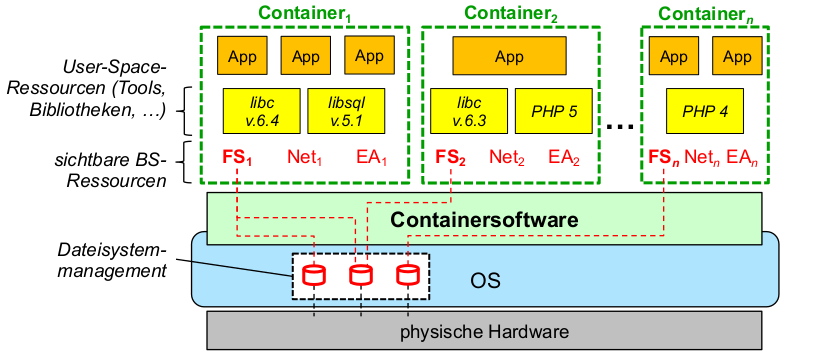
Anwendungsfälle für Container
- Anwendungsentwicklung:
- konfliktfreies Entwickeln und Testen unterschiedlicher Software, für unterschiedliche Zielkonfigurationen BS-User-Space
- Anwendungsbetrieb und -administration:
- Entschärfung von ,,dependency hell,,
- einfache Migration, einfaches Backup von Anwendungen ohne den (bei Virtualisierungsimages als Ballast auftretenden) BS-Kernel
- einfache Verteilung generischer Container für bestimmte Aufgaben
- = Kombinationen von Anwendungen
- Anwendungsisolation?
\rightarrowDocker
Zwischenfazit: Container
- Ziele: Adaptivität komplementär zu...
- Wartbarkeit : Vermeidung von Administrationskosten für Laufzeitumgebung von Anwendungen
- Portabilität : Vereinfachung von Abhängigkeitsverwaltung
- Sparsamkeit : Optimierung der Speicher-und Verwaltungskosten für Laufzeitumgebung von Anwendungen
- Idee:
- unabhängige User-Space-Instanz für jeden einzelnen Container
- Aufgaben des Kernels: Unterstützung der Containersoftware bei Multiplexing und Herstellung der Unabhängigkeitdieser Instanzen
- Ergebnisse:
- ✓ vereinfachte Anwendungsentwicklung
- ✓ vereinfachter Anwendungsbetrieb
- ✗ Infrastruktur nötig über (lokale) Containersoftware hinaus, um Containern zweckgerecht bereitzustellen und zu warten
- ✗ keine vollständige Isolationmöglich
Beispielsysteme (Auswahl)
- Virtualisierung: VMware, VirtualBox
- Paravirtualisierung: Xen
- Exokernel: Nemesis, MirageOS, RustyHermit
- Container: Docker, LupineLinux
Hypervisor
VMware
-
" ... ist Unternehmenin PaloAlto, Kalifornien (USA)
-
gegründet 1998 von 5 Informatikern
-
stellt verschiedene Virtualisierungs-Softwareprodukte her:
- VMware Workstation
- war erstes Produkt von VMware (1999)
- mehrere unabhängige Instanzen von x86- bzw. x86-64-Betriebssystemen auf einer Hardware betreibbar
- VMware Fusion: ähnliches Produkt für Intel Mac-Plattformen
- VMware Player: (eingestellte) Freeware für nichtkommerziellen Gebrauch
- VMware Server (eingestellte Freeware, ehem. GSX Server)
- VMware vSphere (ESXi)
- Produkte 1 ... 3: für Desktop-Systeme
- Produkte 4 ... 5: für Server-Systeme
- Produkte 1 ... 4: Typ-2-Hypervisor
- VMware Workstation
-
bei VMware-Installation: spezielle vm- Treiber in Host-Betriebssystem eingefügt
-
diese ermöglichen: direkten Hardware-Zugriff
-
durch Laden der Treiber: entsteht ,,Virtualisierungsschicht'' (VMware-Sprechweise)
-
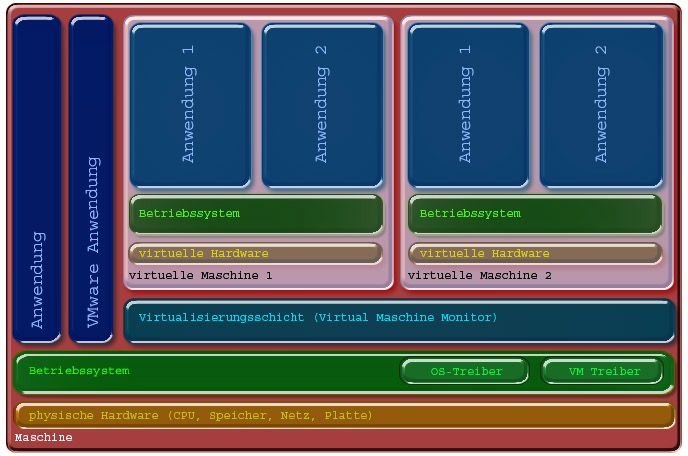
-
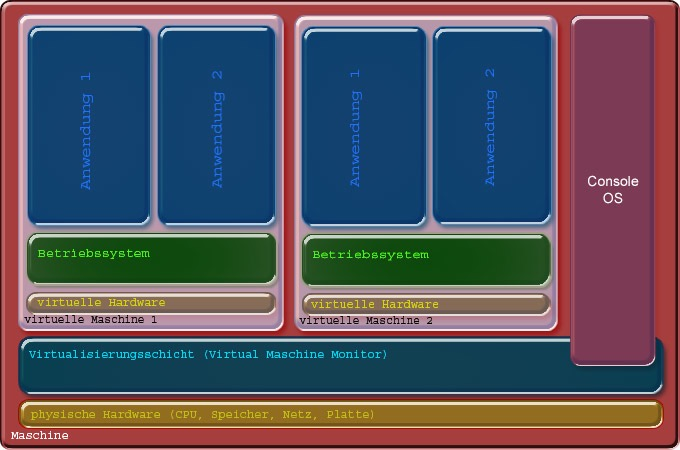
- Typ1- Hypervisor- Architektur
- Anwendung nur bei VMware ESXi
-

- Entsprechende Produkte in Vorbereitung
VirtualBox
- Virtualisierungs-Software für x86- bzw. x86-64-Betriebssysteme für Industrie und ,,Hausgebrauch'' (ursprünglich: Innotek , dann Sun , jetzt Oracle )
- frei verfügbare professionelle Lösung, als Open Source Software unter GNU General Public License(GPL) version 2. ...
- (gegenwärtig) lauffähig auf Windows, Linux, Macintosh und Solaris Hosts
- unterstützt große Anzahl von Gast-Betriebssystemen: Windows (NT 4.0, 2000, XP, Server 2003, Vista, Windows 7), DOS/Windows 3.x, Linux (2.4 and 2.6), Solaris and OpenSolaris , OS/2 , and OpenBSD u.a.
- reiner Typ-2-Hypervisor
Paravirutalisierung: Xen
- entstanden als Forschungsprojekt der University of Cambridge (UK), dann XenSource Inc., danach Citrix, jetzt: Linux Foundation (,,self-governing'')
- frei verfügbar als Open Source Software unter GNU General Public License (GPL)
- lauffähig auf Prozessoren der Typen x86, x86-64, PowerPC, ARM, MIPS
- unterstützt große Anzahl von Gast-Betriebssystemen: FreeBSD, GNU/Hurd/Mach, Linux, MINIX, NetBSD, Netware, OpenSolaris, OZONE, Plan 9
- ,,Built for the cloud before it was called cloud.'' (Russel Pavlicek, Citrix)
- bekannt für Paravirtualisierung
- unterstützt heute auch andere Virtualisierungs-Prinzipien
Xen : Architektur
- Gast-BSe laufen in Xen Domänen (,,$dom_i$'', analog
VM_i) - es existiert genau eine, obligatorische, vertrauenswürdige Domäne:
dom_0 - Aufgaben (Details umseitig):
- Bereitstellen und Verwalten der virtualisierten Hardware für andere Domänen (Hypervisor-API, Scheduling-Politiken für Hardware-Multiplexing)
- Hardwareverwaltung/-kommunikation für paravirtualisierte Gast-BSe (Gerätetreiber)
- Interaktionskontrolle (Sicherheitspolitiken)
dom_0im Detail: ein separates, hochkritisch administriertes, vertrauenswürdiges BS mit eben solchen Anwendungen (bzw. Kernelmodulen) zur Verwaltung des gesamten virtualisierten Systems- es existieren hierfür spezialisierte Variantenvon Linux, BSD, GNU Hurd
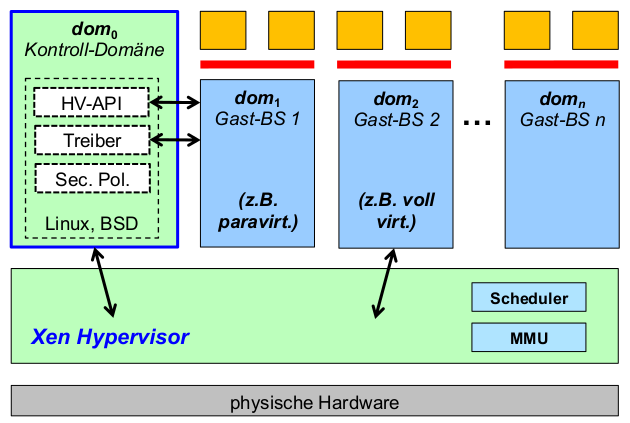
Xen : Sicherheit
- Sicherheitsmechanismusin Xen: Xen Security Modules (XSM)
- illustriert, wie (Para-) Typ-1-Virtualisierung von BS die NFE Sicherheit unterstützt
- PDP: Teil des vertrauenswürdigen BS in
dom_0, PEPs: XSMs im Hypervisor - Beispiel: Zugriff auf Hardware
- Sicherheitspolitik-Integration, Administration, Auswertung:
dom_0 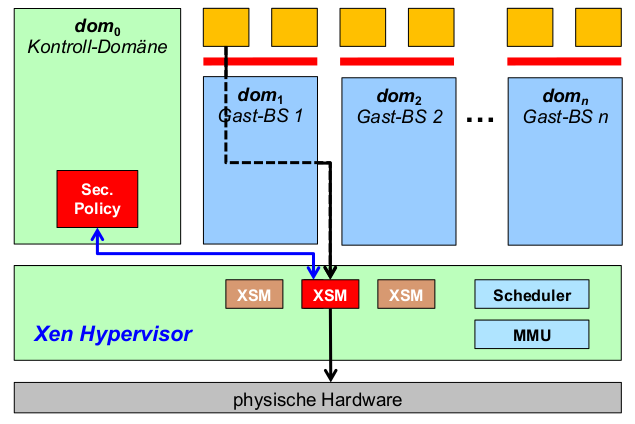
- Sicherheitspolitik-Integration, Administration, Auswertung:
- Beispiel: Inter-Domänen-Kommunikation
- Interaktionskontrolle (Aufgaben wie oben):
dom_0 - Beispiel: VisorFlow
- selber XSM kontrolliert Kommunikation für zwei Domänen
- Interaktionskontrolle (Aufgaben wie oben):
Exokernel
Nemesis
- Betriebssystemaus EU-Verbundprojekt ,,Pegasus,, zur Realisierung eines verteilten multimediafähigen Systems (1. Version: 1994/95)
- Entwurfsprinzipien:
- Anwendungen: sollen Freiheit haben, Betriebsmittel in für sie geeignetster Weise zu nutzen (= Exokernel-Prinzip)
- Realisierung als sog. vertikal strukturiertes Betriebssystem:
- weitaus meiste Betriebssystem-Funktionalität innerhalb der Anwendungen ausgeführt (= Exokernel-Prinzip)
- Echtzeitanforderungen durch Multimedia
\rightarrowVermeidung von Client-Server-Kommunikationsmodell wegen schlecht beherrschbarer zeitlicher Verzögerungen (neu)
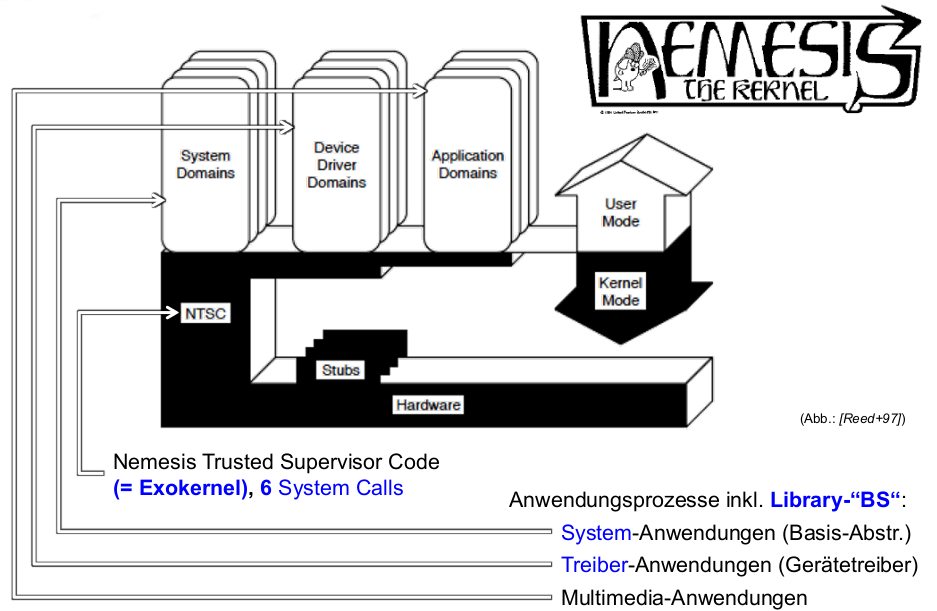
MirageOS + Xen
- Spezialfall: Exokernel als paravirtualisiertes BS auf Xen
- Ziele : Wartbarkeit (Herkunft: Virtualisierungsarchitekturen ...)
- ökonomischer HW-Einsatz
- Unterstützung einfacher Anwendungsentwicklung
- nicht explizit: Unterstützung von Legacy-Anwendungen!
- Idee: ,,Unikernel''
\rightarroweine Anwendung, eine API, ein Kernel - umfangreiche Dokumentation, Tutorials, ...
\rightarrowausprobieren - Unikernel - Idee
- Architekturprinzip:
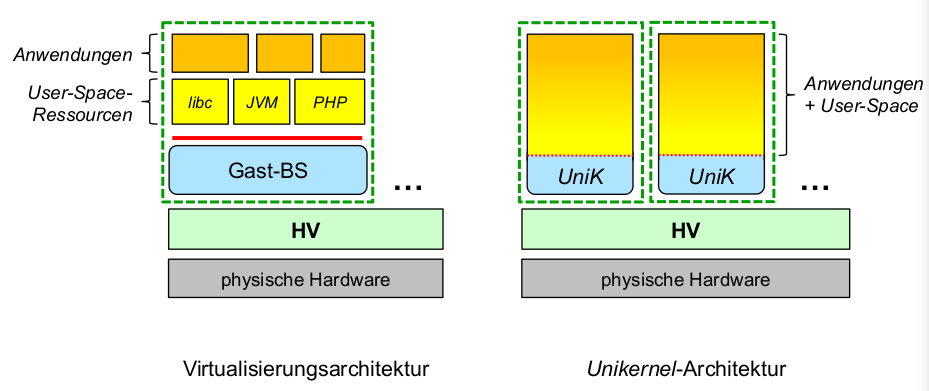
- in MirageOS:
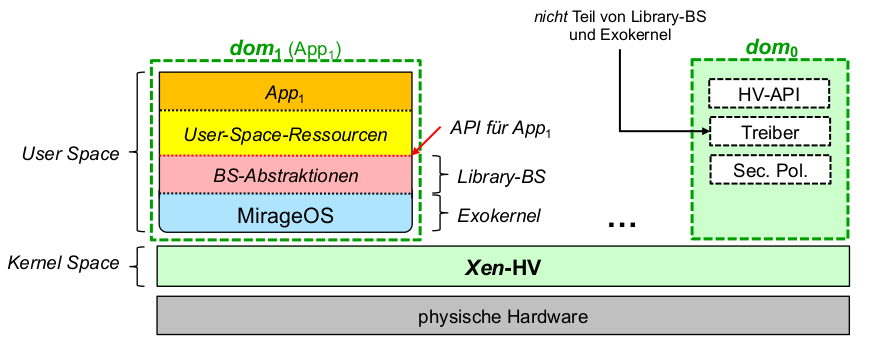
- Architekturprinzip:
- Ergebnis: Kombination von Vorteilen zweier Welten
- Virtualisierungs vorteile: Sicherheit, Robustheit (
\rightarrowXen - Prinzip genau einer vertrauenswürdigen, isolierten Domänedom_0) - Exokernelvorteile: Wartbarkeit, Sparsamkeit
- nicht: Exokernelvorteil der hardwarenahen Anwendungsentwicklung... (
\rightarrowPerformanz und Echzeitfähigkeit )
- Virtualisierungs vorteile: Sicherheit, Robustheit (
Container: Docker
- Idee: Container für einfache Wartbarkeit von Linux-Anwendungsprogrammen ...
- ... entwickeln
- ... testen
- ... konfigurieren
- ... portieren
\rightarrowPortabilität
- Besonderheit: Container können - unabhängig von ihrem Einsatzzweck - wie Software-Repositories benutzt, verwaltet, aktualisiert, verteilt ... werden
- Management von Containers: Docker Client
\rightarrowleichtgewichtiger Ansatz zur Nutzung der Wartbarkeitsvorteile von Virtualisierung - Forsetzung unter der OCI (Open Container Initiative)
- ,,Docker does a nice job [...] for a focused purpose, namely the lightweight packaging and deployment of applications.'' (Dirk Merkel, Linux Journal)
- Implementierung der Containertechnik basierend auf Linux-Kernelfunktionen:
- Linux Containers (LXC): BS-Unterstützung für Containermanagement
- cgroups: Accounting/Beschränkung der Ressourcenzuordnung
- union mounting: Funktion zur logischen Reorganisation hierarchischer Dateisysteme
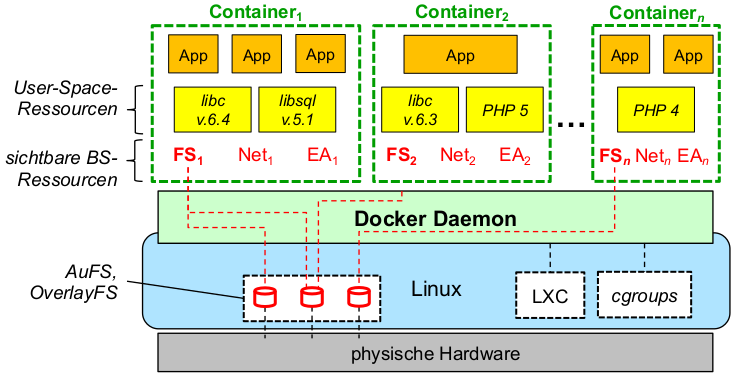
Performanz und Parallelität
Motivation
- Performanz: Wer hätte gern einen schnell(er)en Rechner...?
- Wer braucht schnelle Rechner:
- Hochleistungsrechnen, HPC (,,high performancecomputing'')
- wissenschaftliches Rechnen(z.B. Modellsimulation natürlicher Prozesse, Radioteleskop-Datenverarbeitung)
- Datenvisualisierung(z.B. Analysen großer Netzwerke)
- Datenorganisation-und speicherung(z.B. Kundendatenverarbeitung zur Personalisierung von Werbeaktivitäten, Bürgerdatenverarbeitung zur Personalisierung von Geheimdienstaktivitäten)
- nicht disjunkt dazu: kommerzielle Anwendungen
- ,,Big Data'': Dienstleistungen für Kunden, die o. g. Probleme auf gigantischen Eingabedatenmengen zu lösen haben (Software wie Apache Hadoop )
- Wettervorhersage
- anspruchsvolle Multimedia- Anwendungen
- Animationsfilme
- VR-Rendering
- Hochleistungsrechnen, HPC (,,high performancecomputing'')
Performanzbegriff
- Performance: The degree to which a system or component accomplishes its designated functions within given constraints, such as speed, accuracy, or memory usage. (IEEE)
- Performanz im engeren Sinne dieses Kapitels: Minimierung der für korrekte Funktion (= Lösung eines Berechnungsproblems) zur Verfügung stehenden Zeit.
- oder technischer: Maximierung der Anzahl pro Zeiteinheit abgeschlossener Berechnungen.
Roadmap
- Grundlegende Erkenntnis: Performanz geht nicht (mehr) ohne Parallelität
\rightarrowHochleistungsrechnen = hochparalleles Rechnen - daher in diesem Kapitel: Anforderungen hochparallelen Rechnens an ...
- Hardware: Prozessorarchitekturen
- Systemsoftware: Betriebssystemmechanismen
- Anwendungssoftware: Parallelisierbarkeitvon Problemen
- BS-Architekturen anhand von Beispielsystemen:
- Multikernel: Barrelfish
- verteilte Betriebssysteme
Hardware-Voraussetzungen
- Entwicklungstendenzen der Rechnerhardware:
- Multicore-Prozessoren: seit ca. 2006 (in größerem Umfang)
- Warum neues Paradigma für Prozessoren? bei CPU-Taktfrequenz ≫4 GHz: z.Zt. physikalische Grenze, u.a. nicht mehr sinnvoll handhabbare Abwärme
- Damit weiterhin:
- Anzahl der Kerne wächst nicht linear
- Taktfrequenz wächst asymptotisch, nimmt nur noch marginal zu
Performanz durch Parallelisierung ...
Folgerungen
- weitere Performanz-Steigerung von Anwendungen: primär durch Parallelität (aggressiverer) Multi-Threaded-Anwendungen
- erforderlich: Betriebssystem-Unterstützung
\rightarrowScheduling, Sychronisation - weiterhin erforderlich: Formulierungsmöglichkeiten (Sprachen), Compiler, verteilte Algorithmen ...
\rightarrowhier nicht im Fokus
... auf Prozessorebene
Vorteile von Multicore-Prozessoren
- möglich wird: Parallelarbeit auf Chip-Ebene
\rightarrowVermeidung der Plagen paralleler verteilter Systeme - bei geeigneter Architektur: Erkenntnisse und Software aus Gebiet verteilter Systeme als Grundlage verwendbar
- durch gemeinsame Caches (architekturabhängig): schnellere Kommunikation (speicherbasiert), billigere Migration von Aktivitäten kann möglich sein
- höhere Energieeffizienz: mehr Rechenleistung pro Chipfläche, geringere elektrische Leistungsaufnahme
\rightarrowweniger Gesamtabwärme, z.T. einzelne Kerne abschaltbar (vgl. Sparsamkeit , mobile Geräte) - Baugröße: geringeres physisches Volumen
Nachteile von Multicore-Prozessoren
- durch gemeinsam genutzte Caches und Busstrukturen: Engpässe (Bottlenecks) möglich
- zur Vermeidung thermischer Zerstörungen: Lastausgleich zwingend erforderlich! (Ziel: ausgeglichene Lastverteilung auf einzelnen Kernen)
- zum optimalen Einsatz zwingend erforderlich:
- Entwicklung Hardwarearchitektur
- zusätzlich: Entwicklung geeigneter Systemsoftware
- zusätzlich: Entwicklung geeigneter Anwendungssoftware
Multicore-Prozessoren
- Sprechweise in der Literatur gelegentlich unübersichtlich...
- daher: Terminologie und Abkürzungen:
- MC ...multicore(processor)
- CMP ...chip-level multiprocessing, hochintegrierte Bauweise für ,,MC''
- SMC ...symmetric multicore
\rightarrowSMP ... symmetric multi-processing - AMC ...asymmetric (auch: heterogeneous ) multicore
\rightarrowAMP ... asymmetric multi-processing - UP ...uni-processing , Synonym zu singlecore(SC) oder uniprocessor
Architekturen von Multicore-Prozessoren
- A. Netzwerkbasiertes Design
- Prozessorkerne des Chips u. ihre lokalen Speicher (oder Caches): durch Netzwerkstruktur verbunden
- damit: größte Ähnlichkeit zu traditionellen verteilten Systemen
- Verwendung: bei Vielzahl von Prozessorkernen (Skalierbarkeit!)
- Beispiel: Intel Teraflop-Forschungsprozessor Polaris (80 Kerne als 8x10-Gitter)
- B. Hierarchisches Design
- mehrere Prozessor-Kerne teilen sich mehrere baumartig angeordnete Caches
- meistens:
- jeder Prozessorkern hat eigenen L1-Cache
- L2-Cache, Zugriff auf (externen) Hauptspeicher u. Großteil der Busse aber geteilt
- Verwendung: typischerweise Serverkonfigurationen
- Beispiele:
- IBM Power
- Intel Core 2, Core i
- Sun UltraSPARCT1 (Niagara)
- C. Pipeline-Design
- Daten durch mehrere Prozessor-Kerne schrittweise verarbeitet
- durch letzten Prozessor: Ablage im Speichersystem
- Verwendung:
- Graphikchips
- (hochspezialisierte) Netzwerkprozessoren
- Beispiele: Prozessoren X10 u. X11 von Xelerator zur Verarbeitung von Netzwerkpaketen in Hochleistungsroutern (X11: bis zu 800 Pipeline-Prozessorkerne)
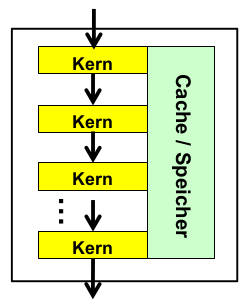
Symmetrische u. asymmetrische Multicore-Prozessoren
- symmetrische Multicore-Prozessoren (SMC)
- alle Kerne identisch, d.h. gleiche Architektur und gleiche Fähigkeiten
- Beispiele:
- Intel Core 2 Duo
- Intel Core 2 Quad
- ParallaxPropeller
- asymmetrische MC-Prozessoren (AMC)
- Multicore-Architektur, jedoch mit Kernen unterschiedlicher Architektur und/oder unterschiedlichen Fähigkeiten
- Beispiel: Kilocore:
- 1 Allzweck-Prozessor (PowerPC)
-
- 256 od. 1024 Datenverarbeitungsprozessoren
Superskalare Prozessoren
- Bekannt aus Rechnerarchitektur: Pipelining
- parallele Abarbeitung von Teilen eines Maschinenbefehls in Pipeline-Stufen
- ermöglicht durch verschiedene Funktionseinheiten eines Prozessors für verschiedene Stufen:
- Control Unit (CU)
- ArithmeticLogicUnit (ALU)
- Float Point Unit (FPU)
- Memory Management Unit (MMU)
- Cache
- sowie mehrere Pipeline-Register
- superskalare Prozessoren: solche, bei denen zur Bearbeitung einer Pipeling-Stufe erforderlichen Funktionseinheiten n-fach vorliegen
- Ziel:
- Skalarprozessor (mit Pipelining): 1 Befehl pro Takt (vollständig) bearbeitet
- Superskalarprozessor: bis zu n Befehle pro Taktbearbeitet
- Verbereitung heute: universell (bis hin zu allen Desktop-Prozessorfamilien)
Parallelisierung in Betriebssystemen
- Basis für alle Parallelarbeit aus BS-Sicht: Multithreading
- wir erinnern uns ...:
- Kernel-Level-Threads (KLTs): BS implementiert Threads
\rightarrowScheduler kann mehrere Threads nebenläufig planen\rightarrowParallelität möglich - User-Level-Threads (ULTs): Anwendung implementiert Threads
\rightarrowkeine Parallelität möglich!
- Kernel-Level-Threads (KLTs): BS implementiert Threads
- grundlegend für echt paralleles Multithreading:
- parallelisierungsfähige Hardware
- kausal unabhängige Threads
- passendes (und korrekt eingesetztes!) Programmiermodell, insbesondere Synchronisation!
\rightarrowProgrammierer + Compiler
Vorläufiges Fazit:
- BS-Abstraktionen müssen Parallelität unterstützen (Abstraktion nebenläufiger Aktivitäten: KLTs)
- BS muss Synchronisationsmechanismen implementieren
Synchronisations- und Sperrmechanismen
- Synchronisationsmechanismen zur Nutzung
- ... durch Anwendungen
\rightarrowTeil der API - ... durch den Kernel (z.B. Implementierung Prozessmanagement, E/A, ...)
- ... durch Anwendungen
- Aufgabe: Verhinderung konkurrierender Zugriffe auf logische oder physische Ressourcen
- Vermeidung von raceconditions
- Herstellung einer korrekten Ordnung entsprechend Kommunikationssemantik (z.B. ,,Schreiben vor Lesen'')
- (alt-) bekanntes Bsp.: Reader-Writer-Problem
Erinnerung: Reader-Writer-Problem
- Begriffe: (bekannt)
- wechselseitiger Ausschluss ( mutual exclusion)
- kritischer Abschnitt (critical section)
- Synchronisationsprobleme:
- Wie verhindern wir ein write in vollen Puffer?
- Wie verhindern wir ein read aus leerem Puffer?
- Wie verhindern wir, dass auf ein Element während des read durch ein gleichzeitiges write zugegriffen wird? (Oder umgekehrt?)
Sperrmechanismen ( Locks )
- Wechselseitiger Ausschluss ...
- ... ist in nebenläufigen Systemen zwingend erforderlich
- ... ist in echt parallelen Systemen allgegenwärtig
- ... skaliert äußerst unfreundlich mit Code-Komplexität
\rightarrow(monolithischer) Kernel-Code!
- Mechanismen in Betriebssystemen: Locks
- Arten von Locks am Beispiel Linux:
- Big Kernel Lock (BKL)
- historisch (1996-2011): lockkernel(); ... unlockkernel();
- ineffizient durch massiv gestiegene Komplexität des Kernels
- atomic-Operationen
- Spinlocks
- Semaphore (Spezialform: Reader/Writer Locks)
- Big Kernel Lock (BKL)
atomic*
- Bausteine der komplexeren Sperrmechanismen:
- Granularität: einzelne Integer- (oder sogar Bit-) Operation
- Performanz: mittels Assembler implementiert, nutzt Atomaritäts garantiender CPU ( TSL - Anweisungen: ,,test-set-lock'' )
- Benutzung:
atomic_t x; atomic_set(&x, 42); int y = atomic_read(&x);atomic_*Geschmacksrichtungen: read, set, add, sub, inc, dec u. a.- keine explizite Lock-Datenstruktur
\rightarrowDeadlocks durch Mehrfachsperrung syntaktisch unmöglich - definierte Länge des kritischen Abschnitts (genau diese eine Operation)
\rightarrowunnötiges Sperren sehr preiswert
Spinlock
- Lockingfür längere kritische Abschnitte:
- wechselseitiger Ausschluss durch aktives Warten
- Granularität: einfach-exklusive Ausführung von Code, der ...
- ... nicht blockiert
- ... (vorhersehbar) kurze Zeit den kritischen Abschnitt nutzt
- Performanz: keine Scheduler-Aktivierung, keine sperrbedingten Kontextwechsel (alle wartenden Threads bleiben ablaufbereit!)
- Benutzung:
DEFINE_SPINLOCK(the_lock);
spin_lock(&the_lock);
... // critical section
spin_unlock(&the_lock);
- explizite Lock-Datenstruktur
\rightarrowDeadlocks durch Mehrfachsperrung oder multiple Locks möglich - variable Länge des kritischen Abschnitts
\rightarrowunnötiges Sperren sehr teuer! (aktives Warten verschwendet Prozessorzeit)
Semaphor
- Lockingfür komplexere kritische Abschnitte:
- wechselseitiger Ausschluss durch suspendieren von Threads
- Granularität: n - exklusive Ausführung von (nahezu) beliebigem Code, über längere oder unbekannt lange (aber endliche) kritische Abschnitte
- Performanz: nutzt Scheduler(Suspendierung und Reaktivierung wartender Threads), verursacht potenziell Kontextwechsel, implementiert Warteschlange
- Benutzung:
struct semaphore the_semaphor;
sema_init(&the_semaphor, n); // Zählsemaphor mit n Plätzen
if (down_interruptible(&the_semaphor))
{ // unterbrechbares Warten... }
... // critical section
up(&the_semaphor);
- mehrfach nutzbare krit. Abschnitte möglich (
\rightarrowbegrenzt teilbare Ressourcen) - explizite Reaktion auf Signale während des Wartens möglich
- Deadlocks möglich, unnötiges Sperren teuer
R/W-Lock
- Reader/Writer Locks: Spezialformen von Spinlocksund binären Semaphoren ( n = 1)
- Steigerung der Locking-Granularität
\rightarrowOptimierung des Parallelitätsgrades - Idee: sperrende Threads nach Zugriffssemantik auf kritischen Abschnitt in zwei Gruppen unterteilt:
- Reader: nur lesende Zugriffe auf Variablen
- Writer: mindestens ein schreibender Zugriff auf Variablen
- R/W-Spinlock/Semaphor muss explizit als Reader oder Writer gesperrt werden
- Performanz: analog Spinlock/Semaphor
- Steigerung der Locking-Granularität
- Benutzung analog Spinlock/Semaphor, z.B.:
DEFINE_RWLOCK(the_lock); read_lock(&the_lock); ... // read-only critical section read_unlock(&the_lock);
Fazit: Locks im Linux-Kernel
- Locking-Overhead: Sperrkosten bei korrekter Benutzung
- Lock-Granularität (ebenfalls bei korrekter Benutzung):
- mögliche Länge des kritischen Abschnitts
- Granularität der selektiven Blockierung (z.B. nur Leser , nur Schreiber )

- Locking-Sicherheit: Risiken und Nebenwirkungen hinsichtlich ...
- fehlerhaften Sperrens (Auftreten von Synchronisationsfehlern)
- Deadlocks
- unnötigen Sperrens (Parallelität ad absurdum ...)
Lastangleichung und Lastausgleich
- Probleme bei ungleicher Auslastung von Multicore-Prozessoren:
- Performanzeinbußen
- stark belastete Prozessorkerne müssen Multiplexing zwischen mehr Threadsausführen als schwach belastete
- dadurch: Verlängerungder Gesamtbearbeitungsdauer
- Akkumulation der Wärmeabgabe
- bedingt durch bauliche Gegebenheiten (Miniaturisierung, CMP)
- Kontrolle erforderlich zur Vermeidung thermischer Probleme (bis zu Zerstörung der Hardware)
- Lösung: Angleichung der Last auf einzelnen Prozessorkernen
Lastangleichung
- Verfahren zur Lastangleichung
- statische Verfahren: einmalige Zuordnung von Threads
- Korrekturen möglich nur durch geeignete Verteilung neuer Threads
- Wirksamkeit der Korrekturen: relativ gering
- dynamische Verfahren: Optimierung der Zielfunktion zur Laufzeit
- Zuordnungsentscheidungen dynamisch anpassbar
- Korrekturpotentialzur Laufzeitdurch Zuweisung eines anderen Prozessorkerns an einen Thread ( Migration )
- aber: algorithmisch komplexer, höhere Laufzeitkosten
- statische Verfahren: einmalige Zuordnung von Threads
- verbreitete Praxis in Universalbetriebssystemen: dynamische
Dynamische Lastangleichung
- Anpassungsgründe zur Laufzeit
- Veränderte Lastsituation: Beenden von Threads
- Verändertes Verhaltens einzelner Threads: z.B. Änderung des Parallelitätsgrads, vormals E/A-Thread wird prozessorintensiv, etc.
- Zuordnungsentscheidungen
- auf Grundlage von a-priori - Informationen über Prozessverhalten
- durch Messungen tatsächlichen Verhaltens
\rightarrowÜbergang von Steuerung zu Regelung
- Kosten von Thread-Migration
- zusätzliche Thread-bzw. Kontextwechsel
- kalte Caches
\rightarrowMigrationskosten gegen Nutzen aufwiegen
grundlegende Strategien:
- Lastausgleich (loadbalancing oder loadleveling)
- Ziel: gleichmäßige Verteilung der Last auf alle Prozessorkerne
- Lastverteilung (loadsharing)
- verwendet schwächere Kriterien
- nur extreme Lastunterschiede zwischen einzelnen Prozessorkernen ausgeglichen(typisch: Ausgleich zwischen leerlaufenden bzw. überlasteten Kernen)
- Anmerkungen
- Lastausgleich: verwendet strengere Kriterien, die auch bei nicht leerlaufenden und überlasteten Kernen greifen
- 100%tiger Lastausgleich nicht möglich (2 Threads auf 3 CPUs etc.)
Lastverteilung beim Linux-Scheduler
globale Entscheidungen
- anfängliche Lastverteilung auf Prozessorkerne grobbzgl. Ausgewogenheit
- dynamische Lastverteilung auf Prozessorkerne durch
- loadbalancing-Strategie
- idlebalancing-Strategie
Verteilungsstrategien
- ,,load balancing'' - Strategie
- für jeden Kern nach Zeitscheibenprinzip (z.B. 200 ms) aktiviert:
- ,,Thread-Stehlen'' vom am meisten ausgelasteten Kern
- aber: bestimmte Threads werden (vorerst) nicht migriert
- solche, die nicht auf allen Kernen lauffähig
- die mit noch ,,heißem Cache''
- erzwungene Thread-Migration (unabhängig von heißen Caches), wenn ,,loadbalancing'' mehrmals fehlgeschlagen
- für jeden Kern nach Zeitscheibenprinzip (z.B. 200 ms) aktiviert:
- ,,idle balancing'' - Strategie
- von jedem Kern aktiviert, bevor er in Leerlauf geht:
- Versuch einer ,,Arbeitsbeschaffung''
- mögliche Realisierung: gleichfalls als ,,Thread-Stehlen'' vom am meisten ausgelasteten Kern
Heuristische Lastverteilung
- in der Praxis: Heuristiken werden genutzt ...
- ... für alle Entscheidungen bzgl.
- loadbalancing (,,Migrieren oder nicht?'')
- threadselection (,,Welchen Threads von anderem Prozessor migrieren?'')
- time-slicing (,,Zeitscheibenlänge für loadbalancing?'')
- ... unter Berücksichtigung von
- Systemlast
- erwarteter Systemperformanz
- bisherigem Thread-Verhalten
- ... für alle Entscheidungen bzgl.
- Bewertung
- Heuristiken verwenden Minimum an Informationen zur Realisierung schneller Entscheidungen
\rightarrowPerformanz der Lastverteilung - Tradeoff: höhere Performanz für aktuelle Last durch teurere Heuristiken (Berücksichtigung von mehr Informationen)?
- Heuristiken verwenden Minimum an Informationen zur Realisierung schneller Entscheidungen
Grenzen der Parallelisierbarkeit
(oder: warum nicht jedes Performanzproblemdurch zusätzliche Hardware gelöst wird)
- Parallelarbeit aus Anwendungssicht: Welchen Performanzgewinn bringt die Parallelisierung?
- naiv:
- 1 Prozessor
\rightarrowBearbeitungszeit t - n Prozessoren
\rightarrowBearbeitungszeit t/n
- 1 Prozessor
- Leistungsmaß für den Performanzgewinn: Speedup
S(n)=\frac{T(1)}{T(n)},T(n)bearbeitungszeit bei n Prozessoren
Amdahls Gesetz: ,,Auch hochgradig parallele Programme weisen gewisse Teile strenger Datenabhängigkeit auf - die nur sequenziell ausgeführt werden können -und daher den erzielbaren Speed-up grundsätzlich limitieren.''
Jedes Programm besteht aus einem nur sequenziell ausführbaren und einem parallelisierbaren Anteil: T(1)=T_s + T_p
mit als sequenziellem Anteil (z.B. \rightarrow 10% sequenzieller Anteil): Effizienz f=\frac{T_s}{T_s+T_p} wobei 0\leq f \leq 1
Damit ergibt sich im günstigsten Fall für Bearbeitungszeit bei Prozessoren: T(n)=f*T(1)+ (1-f)\frac{T(1)}{n}
Speedup nach Amdahl: S(n)=\frac{T(1)}{T(n)}=\frac{1}{f+\frac{1-f}{n}}
Praktische Konsequenz aus Amdahls Gesetz:
- mögliche Beschleunigung bei Parallelisierung einer Anwendung i.A. durch die Eigenschaften der Anwendungselbst begrenzt (sequenzieller Anteil)
- Erhöhung der Prozessorenanzahlüber bestimmtes Maß hinaus bringt nur noch minimalen Performanzgewinn
Annahme bisher:
- parallelisierbarer Anteil auf beliebige Anzahl Prozessoren parallelisierbar
- genauere Problembeschreibung möglich durch Parallelitätsprofil: maximaler Parallelitätsgrad einer Anwendung in Abhängigkeit von der Zeit
- Für ein bestimmtes Problem bringt ab einer Maximalzahl (
p_{max}) jede weitere Erhöhung der Prozessoren-Anzahl keinen weiteren Gewinn, da die Parallelisierbarkeitdes Problems begrenzt ist.
Einfluss von Kommunikation und Synchronisation
- Threads eines Prozesses müssen kommunizieren (Daten austauschen), spätestens nach ihrer Beendigung
- hierzu i.A. auch Synchronisation (Koordination) erforderlich
- Resultat: Prozessoren nicht gesamte Zeit für Berechnungen nutzbar
Overhead durch Kommunikation und Synchronisation
aus Erfahrungen und theoretischen Überlegungen: Zeitaufwand für Kommunikation und Synchronisation zwischen Prozessen (bzw. Threads) einer Anwendung auf verschiedenen Prozessoren:
- streng monoton wachsende Funktion der Prozessoren-Anzahl n (d.h. Funktion nicht nach oben beschränkt)
- praktische Konsequenz von Kommunikation und Synchronisation:
- zu viele Prozessoren für eine Anwendung bedeutet
- keine Geschwindigkeitssteigerung
- sogar Erhöhung der Gesamtbearbeitungszeit
T_{\sum} \rightarrowfallender Speedup
- zu viele Prozessoren für eine Anwendung bedeutet
- Für minimale Bearbeitungsdauer gibt es eine optimale Anzahl Prozessoren
Leistungsmaß Effizienz
Effizienz des Speedups E(n)=\frac{S(n)}{n}
- Normierung des Speedupauf CPU-Anzahl entspricht Wirkungsgrad der eingesetzten Prozessoren
- Idealfall:
S(n)=n\Rightarrow E(n)=\frac{S(n)}{n}=1
Optimale Prozessorenanzahl
T(n) Gesamtbearbeitungszeit
- Im Bereich des Minimums: sehr flacher Verlauf
- (geringe) Änderung der Prozessoren-Anzahl in diesem Bereich: kaum Auswirkungen auf Rechenzeit (im steilen, fallenden Bereich hat Prozessorenanzahl jedoch gewaltige Auswirkungen auf Rechenzeit)
E(n) Effizienz (Auslastung der Prozessoren)
- verringert sich stetig mit zunehmender Prozessoren-Anzahl
- Konflikt zwischen Kostenminimierung (= Minimierung der Ausführungszeit bzw. Maximierung des Speed-up) und Nutzenmaximierung (= Maximierung der Effizienz)
\rightarrowKompromissbereich
Nutzen(E(n))-Kosten(T(n))-Quotienten maximieren: \mu(n)=\frac{E(n)}{T(n)} T(1)=S(n)*E(n)=\frac{S(n)^2}{n}
- Effizienz maximieren:
n_{opt}=n^*_E = 1unsinnig - Speedup maximieren = Ausführungszeit minimieren:
n_{opt}=n^*_SIndividuell für jedes Programm - Nutzen-Kosten-Funktion maximieren:
n_{opt}=n^*_{\mu}individuell für jedes Programm
Beispiel-Betriebssysteme
- Auswahl: Betriebssysteme, die mit Fokus auf Hochparallelität entworfen wurden
- Konsequenzen für BS-Architekturen:
- Parallelität durch Abstraktion von Multicore-Architekturen: Multikernel
- Parallelität durch netzwerkbasierteMulticore-Architekturen: Verteilte Betriebssysteme
Multikernel: Barrelfish
In a nutshell:
- seit ca. 2009 entwickeltes, experimentelles Forschungs-Betriebssystem (open source)
- Untersuchungen zur Struktur künftiger heterogener Multicore-Systeme
- gegenwärtig in Entwicklung an ETH Zürich
- in Zusammenarbeit mit Microsoft
- Forschungsfragen
- Betriebssystemarchitektur
- Trend stetig wachsender Anzahl Prozessorkerne
\rightarrowSkalierbarkeit des Betriebssystems zur Maximierung von Parallelität? - zunehmende Menge an Varianten der Hardware-Architektur, betreffend z.B.
- Speicherhierarchien
- Verbindungsstrukturen
- Befehlssatz
- E/A-Konfiguration
-
\rightarrowUnterstützung zunehmend heterogener Hardware-Vielfalt (insbesondere noch zu erwartender Multicore-Prozessoren)?
- Wissensdarstellung
- Betriebssystem und Anwendungen Informationen über aktuelle Architektur zur Laufzeit liefern
\rightarrowInformationen zur Adaptivitätdes BS an Last und Hardware zur Maximierung von Parallelität?
- Betriebssystem-Architektur für heterogene Multicore-Rechner
- Idee: Betriebssystem wird strukturiert ...
- als verteiltes System von Kernen,
- die über Botschaften kommunizieren (Inter-Core-Kommunikation) und
- keinen gemeinsamen Speicher besitzen.
- Entwurfsprinzipien:
- alle Inter-Core-Kommunikation explizit realisiert d.h. keine implizite Kommunikation z.B. über verteilte Speichermodelle wie DSM (Distributed SharedMemory), Botschaften zum Cache-Abgleich etc.
- Betriebssystem-Struktur ist Hardware-neutral
- Zustandsinformationen als repliziert (nicht als verteilt)betrachtet
\rightarrowschwächere Synchronisationsanforderungen!
- Idee: Betriebssystem wird strukturiert ...
- Ziele dieser Entwurfsprinzipien
- Verbesserte Performanz auf Grundlage des Entwurfs als verteiltes System
- Natürliche Unterstützung für Hardware-Inhomogenitäten
- Größere Modularität
- Wiederverwendbarkeit von Algorithmen, die für verteilte Systeme entwickelt wurden
- Implementierung: auf jedem Prozessorkern Betriebssystem-Instanz aus CPU-''Treiber'' und Monitor-Prozess
CPU Driver
- Aufgabe: Umsetzung von Strategien zur Ressourcenverwaltung, z.B.
- Durchsetzung von Zugriffssteuerungsentscheidungen
- Zeitscheiben-Multiplexing von Threads
- Vermittlung von Hardware-Zugriffendes Kernels (MMU, Clockusw.)
- Ereignisbehandlung
- Implementierung:
- hardwarespezifisch
- vollständig ereignisgesteuert, single-threaded, nicht-präemptiv
- läuft im privilegierten Modus (Kernel-Modus)
- ist absolut lokal auf jedem Prozessor-Kern (gesamte Inter-Core-Kommunikation durch die Monitore realisiert)
- ist vergleichsweise klein, so dass er im Lokalspeicher des Prozessorkerns untergebracht werden kann
\rightarrowWartbarkeit, Robustheit, Korrektheit
Monitor
- Wichtige Angaben
- läuft im Nutzer-Modus
- Quellcode fast vollständig prozessorunabhängig
- Monitore auf allen Prozessorkernen: koordinieren gemeinsam systemweite Zustandsinformationen
- auf allen Prozessor-Kernen replizierte Datenstrukturen: mittels Abstimmungsprotokollkonsistent gehalten (z.B. Speicherzuweisungstabellen u. Adressraum-Abbildungen)
\rightarrowimplementiert Konsensalgorithmenfür verteilte Systeme
- Monitore: enthalten die meisten wesentlichen Mechanismen und Strategien, die in monolithischem Betriebssystem-Kernel (bzw. $\mu$Kernel-Serverprozessen) zu finden sind
Verteilte Betriebssysteme
- hier nur Einblick in ein breites Themenfeld
- Grundidee: Ortstransparenz
- FE des Betriebssystems:
- abstrahieren ...
- multiplexen ...
- schützen ...
- hierzu: lokaler BS-Kernel kommuniziert mit über Netzwerk verbundenen, physisch verteilten anderen Kernels (desselben BS)
- Anwendungssicht auf (nun verteilte) Hardware-Ressourcen identisch zu Sicht auf lokale Hardware
\rightarrowOrtstransparenz
- FE des Betriebssystems:
- Zwei Beispiele:
- Amoeba: Forschungsbetriebssystem, Python-Urplattform
- Plan 9 fom Bell Labs: everything is a file
Amoeba
Architektur:
- verteiltes System aus drei (nicht zwingend disjunkten)Arten von Knoten:
- Workstation (GUI/Terminalprozess, Benutzerinteraktion)
- Pool Processor (nicht-interaktive Berechnungen)
- Servers(File ~, Directory ~, Networking ~, ...)
- Betriebssystem: $\mu$Kernel (identisch auf allen Knoten) + Serverprozesse (dedizierte Knoten, s.o.: Servers )
\rightarrowVertreter einer verteilten μKernel-Implementierung- Kommunikation:
- LAN (Ethernet)
- RPCs (Remote ProcedureCalls)
\rightarrowrealisieren ortstransparenten Zugriff auf sämtliche BS-Abstraktionen (Amoeba: objects )
Plan 9
- verteiltes BS der Bell Labs (heute: Open Source Projekt)
- Besonderheit: Semantik der Zugriffe auf verteilte BS-Abstraktionen
- ortstransparent (s. Amoeba)
- mit ressourcenunabhängig identischen Operationen - deren spezifische Funktionalität wird für die Anwendung transparent implementiert
\rightarrowKonzept ,,everything is a file''... bis heute in unixoiden BS und Linux!
- Beispiele:
- Tastatureingabenwerden aus (Pseudo-) ,,Datei'' gelesen
- Textausgabenwerden in ,,Datei'' geschrieben -aus dieser wiederum lesen Terminalanwendungen
- all dies wird logisch organisiert durch private Namensräume
\rightarrowKonzept hierarchischer Dateisysteme
Zusammenfassung
Funktionale und nichtfunktionale Eigenschaften
- Funktionale Eigenschaften: beschreiben, was ein (Software)-Produkt tun soll
- Nichtfunktionale Eigenschaften: beschreiben, wie funktionale Eigenschaften realisiert werden, also welche sonstigen Eigenschaftendas Produkt haben soll ... unterteilbar in:
- Laufzeiteigenschaften (zur Laufzeit sichtbar)
- Evolutionseigenschaften (beim Betrieb sichtbar: Erweiterung, Wartung, Test usw.)
Roadmap (... von Betriebssystemen)
- Sparsamkeit und Effizienz
- Robustheit und Verfügbarkeit
- Sicherheit
- Echtzeitfähigkeit
- Adaptivität
- Performanzund Parallelität
Sparsamkeit und Effizienz
- Sparsamkeit: Die Eigenschaft eines Systems, seine Funktion mit minimalem Ressourcenverbrauch auszuüben.
- Effizienz: Der Grad, zu welchem ein System oder eine seiner Komponenten seine Funktion mit minimalem Ressourcenverbrauch ausübt.
\rightarrowAusnutzungsgrad begrenzter Ressourcen - Die jeweils betrachtete(n) Ressource(n) muss /(müssen) dabei spezifiziert sein!
- sinnvolle Möglichkeiten bei Betriebssystemen:
- Sparsamer Umgang mit Energie , z.B. energieeffizientes Scheduling
- Sparsamer Umgang mit Speicherplatz (Speichereffizienz)
- Sparsamer Umgang mit Prozessorzeit
- ...
Sparsamkeit mit Energie
- Sparsamkeit mit Energie als heute extrem wichtigen Ressource, mit nochmals gesteigerter Bedeutung bei mobilen bzw. vollständig autonomen Geräten Maßnahmen:
- Hardware-Ebene: momentan nicht oder nicht mit maximaler Leistung benötigte Ressourcen in energiesparenden Modus bringen: abschalten, Standby, Betrieb mit verringertem Energieverbrauch ( abwägen gegen verminderte Leistung). (Geeignete Hardware wurde/wird ggf. erst entwickelt)
- Software-Ebene: neue Komponenten entwickeln, die in der Lage sein müssen:
- Bedingungenzu erkennen, unter denen ein energiesparender Modus möglich ist;
- Steuerungs-Algorithmen für Hardwarebetrieb so zu gestalten, dass Hardware-Ressourcen möglichst lange in einem energiesparenden Modus betrieben werden.
- Energie-Verwaltungsstrategien: energieeffizientes Scheduling zur Vermeidung von Unfairness und Prioritätsumkehr
- Beispiele: energieeffizientes Magnetfestplatten-Prefetching, energiebewusstes RR-Scheduling
Sparsamkeit mit Speicherplatz
- Betrachtet: Sparsamkeit mit Speicherplatz mit besonderer Wichtigkeit für physisch beschränkte, eingebettete und autonome Geräte
- Maßnahmen Hauptspeicherauslastung:
- Algorithmus und Strategie z.B.:
- Speicherplatz sparende Algorithmen zur Realisierung gleicher Strategien
- Speicherverwaltung von Betriebssystemen:
- physische vs. virtuelle Speicherverwaltung
- speichereffiziente Ressourcenverwaltung
- Speicherbedarfdes Kernels
- direkte Speicherverwaltungskosten
- Algorithmus und Strategie z.B.:
- Maßnahmen Hintergrundspeicherauslastung:
- Speicherbedarf des Betriebssystem-Images
- dynamische SharedLibraries
- VMM-Auslagerungsbereich
- Modularität und Adaptivität des Betriebssystem-Images
- Nicht betrachtet: Sparsamkeit mit Prozessorzeit
\rightarrow99% Überschneidung mit NFE Performanz
Robustheit und Verfügbarkeit
- Robustheit: Zuverlässigkeit unter Anwesenheit externer Ausfälle
- fault, aktiviert
\rightarrowerror, breitet sich aus\rightarrowfailure
Robustheit
- Erhöhung der Robustheit durch Isolation:
- Maßnahmen zur Verhinderung der Fehlerausbreitung:
- Adressraumisolation: Mikrokernarchitekturen,
- kryptografische HW-Unterstützung: Intel SGX und
- Virtualisierungsarchitekturen
- Erhöhung der Robustheit durch Behandlung von Ausfällen: Micro-Reboots
Vorbedingung für Robustheit: Korrektheit
- Korrektheit: Eigenschaft eines Systems sich gemäß seiner Spezifikation zu verhalten (unter der Annahme, dass bei dieser keine Fehler gemacht wurden).
- Maßnahmen (nur angesprochen):
- diverse Software-Tests:
- können nur Fehler aufspüren, aber keine Fehlerfreiheit garantieren!
- Verifizierung:
- Durch umfangreichen mathematischen Apparat wird Korrektheit der Software bewiesen.
- Aufgrund der Komplexität ist Größe verifizierbarer Systeme (bisher?) begrenzt.
- Betriebssystem-Beispiel: verifizierter Mikrokern seL
Verfügbarkeit
- Verfügbarkeit: Der Anteil an Laufzeit eines Systems, in dem dieses seine spezifizierte Leistung erbringt.
- angesprochen: Hochverfügbare Systeme
- Maßnahmen zur Erhöhung der Verfügbarkeit:
- Robustheitsmaßnahmen
- Redundanz
- Redundanz
- Redundanz
- Ausfallmanagement
Sicherheit
- Sicherheit (IT-Security): Schutz eines Systems gegen Schäden durch zielgerichtete Angriffe, insbesondere in Bezug auf die Informationen, die es speichert, verarbeitet und kommuniziert.
- Sicherheitsziele:
- Vertraulichkeit (Confidentiality)
- Integrität (Integrity)
- Verfügbarkeit (Availability)
- Authentizität (Authenticity)
- Verbindlichkeit (Non-repudiability)
Security Engineering
- Sicherheitsziele
\rightarrowSicherheitspolitik\rightarrowSicherheitsarchitektur\rightarrowSicherheitsmechanismen - Sicherheitspolitik: Regeln zum Erreichen eines Sicherheitsziels.
- hierzu formale Sicherheitsmodelle:
- IBAC, TE, MLS
- DAC, MAC
- Sicherheitsmechanismen: Implementierung der Durchsetzung einer Sicherheitspolitik.
- Zugriffssteuerungslisten(ACLs)
- SELinux
- Sicherheitsarchitektur: Platzierung, Struktur und Interaktion von Sicherheitsmechanismen.
- wesentlich: Referenzmonitorprinzipien
- RM1: Unumgehbarkeit
\rightarrowvollständiges Finden aller Schnittstellen - RM2: Manipulationssicherheit
\rightarrowSicherheit einerSicherheitspolitik selbst - RM3: Verifizierbarkeit
\rightarrowwohlstrukturierte und per Designkleine TCBs
Echtzeitfähigkeit
- Echtzeitfähigkeit: Fähigkeit eines Systems auf eine Eingabe innerhalb eines spezifizierten Zeitintervalls eine korrekte Reaktion hervorzubringen.
- Maximum dieses relativen Zeitintervalls: Frist d
- echtzeitfähige Scheduling-Algorithmen für Prozessoren
- zentral: garantierte Einhaltung von Fristen
- wichtige Probleme: Prioritätsumkehr, Überlast, kausale Abhängigkeit
- echtzeitfähige Interrupt-Behandlung
- zweiteilig:asynchron registrieren, geplant bearbeiten
- echtzeitfähige Speicherverwaltung
- Primärspeicherverwaltung, VMM (Pinning)
- Sekundärspeicherverwaltung, Festplattenscheduling
Adaptivität
- Adaptivität: Eigenschaft eines Systems, so gebaut zu sein, dass es ein gegebenes (breites) Spektrum nichtfunktionaler Eigenschaften unterstützt.
- Beobachtung: Adaptivität i.d.R. als komplementär und synergetisch zu anderen NFE:
- Sparsamkeit
- Robustheit
- Sicherheit
- Echzeitfähigkeit
- Performanz
- Wartbarkeit und Portierbarkeit
Adaptive Systemarchitekturen
- Zielstellungen:
- Exokernel: { Adaptivität } ∪ { Performanz, Echtzeitfähigkeit, Wartbarkeit, Sparsamkeit }
- Virtualisierung: { Adaptivität } ∪ { Wartbarkeit, Sicherheit, Robustheit }
- Container: { Adaptivität } ∪ { Wartbarkeit, Portabilität, Sparsamkeit }
Performanz und Parallelität
- Performanz (wie hier besprochen): Eigenschaft eines Systems, die für korrekte Funktion (= Berechnung) benötigte Zeit zu minimieren.
- hier betrachtet: Kurze Antwort-und Reaktionszeiten
- vor allen Dingen: Parallelisierung auf Betriebssystemebene zur weiteren Steigerung der Performanz/Ausnutzung von Multicore-Prozessoren(da Steigerung der Prozessortaktfrequenz kaum noch möglich)
- weiterhin: Parallelisierung auf Anwendungsebene zur Verringerung der Antwortzeiten von Anwendungen und Grenzen der Parallelisierbarkeit(für Anwendungen auf einem Multicore-Betriebssystem).
Mechanismen, Architekturen, Grenzen der Parallelisierung
- Hardware:
- Multicore-Prozessoren
- Superskalarität
- Betriebssystem:
- Multithreading(KLTs) und Scheduling
- Synchronisation und Kommunikation
- Lastangleichung
- Anwendung(sprogrammierer):
- Parallelisierbarkeiteines Problems
- optimaler Prozessoreneinsatz, Effizienz
Synergetische und konträre Eigenschaften
- Normalerweise:
- Eine nichtfunktionale Eigenschaft bei IT-Systemen meist nicht ausreichend
- Beispiel: Was nützt ein Echtzeit-Betriebssystem - z.B. innerhalb einer Flugzeugsteuerung - wenn es nicht auch verlässlich arbeitet?
- In diesem Zusammenhang interessant:
- Welche nichtfunktionalen Eigenschaften mit Maßnahmen erreichbar, die in gleiche Richtung zielen, bei welchen wirken Maßnahmen eher gegenläufig?
- Erstere sollen synergetische, die zweiten konträre (also in Widerspruch zueinander stehende) nichtfunktionale Eigenschaften genannt werden.
- Zusammenhang nicht immer eindeutig und offensichtlich, wie z.B. bei: ,,Sicherheit kostet Zeit.'' (d.h. Performanz und Sicherheit sind nichtsynergetische Eigenschaften)
Notwendige NFE-Paarungen
- Motivation: Anwendungen (damit auch Betriebssysteme) für bestimmte Einsatzgebiete brauchen oft mehrere nichtfunktionale Eigenschaften gleichzeitig - unabhängig davon, ob sich diese synergetisch oder nichtsynergetisch zueinander verhalten.
- Beispiele:
- Echtzeit und Verlässlichkeit: ,,SRÜ''-Systeme an potentiell gefährlichen Einsatzgebieten (Atomkraftwerk, Flugzeugsteuerung, Hinderniserkennung an Fahrzeugen, ...)
- Echtzeit und Sparsamkeit: Teil der eingebetteten Systeme
- Robustheit und Sparsamkeit: unter entsprechenden Umweltbedingungen eingesetzte autonome Systeme, z.B. smart-dust-Systeme
Überblick: NFE und Architekturkonzepte
| Makrokernel | Mikrokernel | Exokernel | Virtualisierung | Multikernel | |
|---|---|---|---|---|---|
| Energieeffizienz | (✓) | ✗ | ✗ | ||
| Speichereffizienz | ✗ | (✓) | (✓) | ✗ | |
| Robustheit | ✗ | ✓ | ✗ | ✓ | |
| Verfügbarkeit | ✗ | (✓) | (✓) | (✓) | |
| Korrektheit | ✗ | ✓ | ✗ | ✗ | (✓) |
| Sicherheit | ✗ | ✓ | ✗ | ✓ | |
| Echtzeitfähigkeit | (✓) | (✓) | ✓ | ✗ | ✗ |
| Adaptivität | ✗ | (✓) | ✓ | ✓ | (✓) |
| Wartbarkeit | ✓ | ✓ | ✓ | ||
| Performanz | (✓) | ✗ | ✓ | ✗ | ✓ |
- ✓ ... Zieleigenschaft
- ( ✓ ) ... synergetische Eigenschaft
- ✗ ... konträre Eigenschaft
- Leere Zellen: keine pauschale Aussage möglich.
Fazit: Breites und offenes Forschungsfeld \rightarrow werden Sie aktiv!
Prüfungsschwerpunkte
- Basiswissen: Allgemeines zu NFEn, NFE-Ziele (Anwendungsbsp.), Probleme und deren Lösungskonzepte (Strategien, Mechanismen, Architekturen)!
- zu jeder NFE: Konzepte und Strategien der Mechanismen (Idee), relevante System-Architekturen (Idee, Vor-und Nachteile)
- z.B.: Warum Sicherheit? Wo? Welche BS-Probleme sind zur Herstellung von Sicherheitseigenschaften zu lösen? Durch welche Konzepte (z.B. Zugriffssteuerungsmechanismen, Referenzmonitor-Arch.) ist dies möglich?
- Basiswissen plus (= für gute Noten):
- Mechanismen: prinzipieller Ablauf von Algorithmen, praktische Eigenheiten/Implementierungsprobleme
- Beispiel-BSe(Idee, ggf. deren Aufbau)
- Vergleichende Bewertung synergetischer und konträrer NFE anhand ihrer jeweils relevanten Mechanismen und Architekturen (Stoffquerschnitt)
- Tipp: Übungsstoff zu 90% aus diesen beiden Schwerpunktklassen
- Spezialwissen (= für supergute Noten):
- Sparsamkeit: Implementierung energiebewusstes RR
- Robustheit: Details zur L4-Abstraktion von hierarchischen Adressräumen
- Sicherheit: TCBs, ACL-Implementierung, HRU- und BLP Sicherheitsmodelle, SELinux: grundlegende Politiksemantik
- Echtzeit: RC Algorithmus über die ,,Idee'' hinausgehend , Strategien zur Sekundärspeicherverwaltung, Formeln fur
U_{lub} - Adaptivität: Details zur ExOS, XoK
- Performanz: BKLs in $\mu$Kernels, Formeln zur Parallelisierbarkeit
- Zusatzwissen (= für‘s Leben, nicht für die Prüfung):
- Sparsamkeit: Hardware-Maßnahmen, Details zu DPM und DVS
- Robustheit: Verfügbarkeitsklassen in Zahlen
- Sicherheit: Syntax zur Definition der SELinux-Politik, Benutzung von SGX-Enclaves
- Echtzeit: Beweis: Obere Auslastungsgrenze bei EDF
- Adaptivität: Assembler-Beispiel zur sensiblen Instruktionen
- Performanz: Berechnung des Optimums der Beschleunigungseffizienz, Plan 9
Literatur
- NFE in Betriebssystemen
- Eeles, Peter; Cripps, Peter: The Process of Software Architecting
- Funktionale Eigenschaften eines Betriebssystem
- Tanebaum, Andrews; Bos, Herbert: Modern Operating Systems
- Tanebaum, Andrews; Woodhull, Alberts: Operating Systems Design and Implementation
- Stallings, William: Operating Systems: Internals and Design Principles
- Energieeffizienz
- GUPTA, RAJESHK.; IRANI, SANDY; SHUKLA, SANDEEPK.; SHUKLA, SANDEEPK.: Formal Methods for Dynamic Power Management
- RANGANATHAN, PARTHASARATHY: Recipe for efficiency: principles of power-aware computing
- SIMUNIC, TAJANA; BENINI, LUCA; GLYNN, PETER; DEMICHELI, GIOVANNI: Dynamic Power Management for Portable Systems
- Effiziente Hauptspeicherverwaltung
- DINIZ, BRUNO; GUEDES, DORGIVAL; MEIRA, WAGNER, JR.; BIANCHINI, RICARDO: Limiting the Power Consumption of Main Memory
- Traditionelles Festplatten-Prefetching
- CAO, PEI; FELTEN, EDWARDW.; KARLIN, ANNAR.; LI, KAI: A Study ofIntegrated Prefetching and Caching Strategies
- Effizienter Betrieb von Festplatten
- PAPATHANASIOU, ATHANASIOSE.; SCOTT, MICHAELL.: Energy Efficient Prefetching and Caching
- Energieeffizientes Scheduling
- KLEE, CHRISTOPH: Design and Analysis of Energy-Aware Scheduling Policies
- Energieeffiziente Betriebssysteme
- LANG, CLEMENS: Components for Energy-Efficient Operating Systems
- YAN, LE; ZHONG, LIN; JHA, NIRAJK.: Towards a Responsive, Yet Power-efficient, Operating System: A Holistic Approach
- YAN, LE; ZHONG, LIN; JHA, NIRAJK.: User-perceived Latency Driven Voltage Scaling for Interactive Applications
- Eingebettete Systeme
- MANLEY, JOHNH.: Embedded Systems, MARCINIAK, J. J.(Hrsg.)
- TinyOS
- KELLNER, SIMON; BELLOSA, FRANK: Energy Accounting Support in TinyOS
- KELLNER, SIMON: Flexible Online Energy Accounting in TinyOS
- Verlässlichkeitsbegriff, Fehlermodell:
- [ALRL04] AVIŽIENIS, ALGIRDAS; LAPRIE, JEAN-CLAUDE; RANDELL, BRIAN; LANDWEHR, CARL: Basic Concepts and Taxonomy of Dependable and Secure Computing. In: IEEE Trans. Dependable Secur. Comput. https://doi.org/10.1109/TDSC.2004.2
- [AvLR04] AVIŽIENIS, ALGIRDAS; LAPRIE, JEAN-CLAUDE; RANDELL, BRIAN: Dependability and Its Threats: A Taxonomy. In: JACQUART, R.(Hrsg.): Building theInformation Society , IFIP International Federation for Information Processing : Springer US, 2004, https://doi.org/10.1007/978
- DeepSpace 1 Remote Debugging:
- GARRET, RON: Lispingat JPL. URL http://www.flownet.com/gat/jpl-lisp.html
- Kernelarchitekturdesign und Mikrokernelprinzip:
- [Heis19] HEISER, GERNOT: COMP9242 Advanced Operating Systems. Lecture Slides UNSW Australia, 2019. Courtesy of Gernot Heiser, UNSW. https://www.cse.unsw.edu.au/~cs9242/19/lectures.shtml
- [TaBo15] TANENBAUM, ANDREWS; WOODHULL, ALBERTS: Operating Systems Design and Implementation. 3. Aufl. UpperSaddleRiver, NJ, USA: Prentice-Hall, Inc., 2005
- Mikrokerneldesign, L4:
- [Lied95] LIEDTKE, JOCHEN: On μ-Kernel Construction. In: Operating Systems Review. Special issue for the Fifteenth ACM Symposium on Operating System Principles Bd. 29 (1995), https://doi.org/10.1145/224056.224075
- MINIX:
- HERDER, JORRITN.; BOS, HERBERT; GRAS, BEN; HOMBURG, PHILIP; TANENBAUM, ANDREWS.: MINIX 3: A Highly Reliable, Self-repairing Operating System. In: ACM SIGOPS Operating Systems Review https://doi.org/10.1145/1151374.1151391
- TANENBAUM, ANDREWS. APPUSWAMY, RAJA; BOS, HERBERTJ. ; CAVALLARO, LORENZO; GIUFFRIDA, CRISTIANO; HRUBY, TOMAS; HERDER, JORRIT; VANDERKOUWE, ERIK; U.A.: MINIX 3: Status Report and Current Research. In: login: The USENIX Magazine Bd. 35 (2010) https://www.usenix.org/publications/login/june- 2010
- [TaWo05] TANENBAUM, ANDREWS; WOODHULL, ALBERTS: Operating Systems Design and Implementation. 3. Aufl. UpperSaddleRiver, NJ, USA: Prentice-Hall, Inc.
- Sicherheitsbedrohungen:
- [Stal18] STALLINGS, WILLIAM: Operating Systems: Internals and Design Principles. Pearson, 2018
- Sicherheitsmodelle:
- [Amth16] AMTHOR, PETER: The Entity LabelingPattern for Modeling Operating Systems Access Control. In: OBAIDAT, S. M.; LORENZ, P.(Hrsg.): E-Business and Telecommunications: 12th International Joint Conference, ICETE 2015, Colmar, France, http://dx.doi.org/10.1007/978-3-319-30222-5_13
- [BeLa76] BELL, D. ELLIOTT; LAPADULA, LEONARDJ.: Secure Computer System: Unified Exposition and MulticsInterpretation (Technical Report Nr. AD-A023 588): MITRE, 1976
- [Biba77] BIBA, KENNETHJ.: IntegrityConsiderationsforSecure Computer Systems (Technical Report Nr. ESD-TR-76-372). Bedford, Massachusetts: MITRE, 1977 http://seclab.cs.ucdavis.edu/projects/history/papers/biba75.pdf (digitalisierte Fassung von 1975)
- [HaRU76] HARRISON, MICHAELA.; RUZZO, WALTERL.; ULLMAN, JEFFREYD.: Protectionin Operating Systems. In: Communications oftheACM Bd. 19 (1976), Nr.8, S. 461 - 471 http://doi.acm.org/10.1145/360303.360333
- SELinux:
- [LoSm01] LOSCOCCO, PETERA.; SMALLEY, STEPHEND.: Integrating Flexible Support for Security Policies into the Linux Operating System. In: COLE, C.(Hrsg.): Proceedings of the FREENIX Track: 2001 USENIX Annual Technical Conference. Berkeley, CA, USA: USENIX Association
- [MaMC06] MAYER, FRANK; MACMILLAN, KARL; CAPLAN, DAVID: SELinux by Example: Using Security Enhanced Linux (Prentice Hall Open Source Software Development Series). UpperSaddle River, NJ, USA: PrenticeHall PTR, 2006
- [Spen07] SPENNEBERG, RALF: SELinux & AppArmor: Mandatory Access Control für Linux einsetzen und verwalten. 1. Aufl. München: Addison-Wesley Verlag, 2007
- Microsoft Singularity:
- [HLAA05] HUNT, GALEN; LARUS, JAMES; ABADI, MARTIN; AIKEN, MARK; BARHAM, PAUL; FÄHNDRICH, MANUEL; HAWBLITZEL, CHRIS; HODSON, ORION; U.A.: An Overview of the Singularity Project (Nr. MSR-TR-2005-135): Microsoft Research, Redmond, 2005 http://research.microsoft.com/pubs/52716/tr-2005-135.pdf
- Intel SGX:
- [CoDe16] COSTAN, VICTOR; DEVADAS, SRINIVAS: Intel SGX Explained , 2016. Published: Cryptology ePrintArchive, Report 2016/086 https://eprint.iacr.org/2016/086.pdf
- [WeAK18] WEICHBRODT, NICO; AUBLIN, PIERRE-LOUIS; KAPITZA, RÜDIGER: Sgx-perf: A Performance Analysis Tool forIntel SGX Enclaves. In: Proceedingsofthe19th International Middleware Conference , Middleware ’18. New York, NY, USA: ACM, 2018. Rennes, France, S. 201 - 213 http://doi.acm.org/10.1145/3274808.3274824 Referenzmonitor:
- [Ande72] ANDERSON, JAMESP.: Computer Security Technology Planning Study (Nr. ESD-TR-73-51). HanscomAFB, Bedford, MA, USA: Air Force Electronic Systems Division, 1972
- [Jaeg11] JAEGER, TRENT: Reference Monitor. In: VANTILBORG, H. C. A.; JAJODIA, S.(Hrsg.): Encyclopedia of Cryptography and Security. Boston, MA: Springer US, 2011, S. 1038 - 1040 http://www.cse.psu.edu/~trj1/cse543-s15/docs/refmon.pdf
- [Buttazzo97], [Buttazzo2000] Giorgio C. Buttazzo: Hard Real-Time Computing Systems - Predictable Scheduling Algorithms and Applications, Kluwer Academic Publishers Boston / Dordrecht / London, 1997
- [Burns+89] Alan Burns, Andy Wellings: Real-Time Systems andProgrammingLanguages, Addison-Wesley, 3rd edition 2001
- [Liu&Layland73] C. L. Liu, James W. Layland: Scheduling Algorithms for Multiprogramming in a Hard-Real-Time Environment, Journal of the ACM, Vol. 20, Nr. 1 (Januar 1973)
- [Quade+2012] Jürgen Quade, Michael Mächtel: Moderne Realzeitsysteme kompakt -Eine Einführung mit Embedded Linux, dpunkt.verlag, 2012
- [Liu2000] Jane W. S. Liu: Real-Time Systems, PrenticeHall 2000
- [Clark89] Dayton Clark: HIC: An Operating System for Hierarchies of Servo Loops, Proceedings of the 1989 International Conference on Robotics and Automation
- [Deitel90] Harvey M. Deitel: Operating Systems, Addison-Wesley, 1990
- [Goyal+96] PawanGoyal, XingangGuo, HarrickM. Vin: A HierarchicalCPU Scheduler forMultimedia Operating Systems, OSDI (ACM-Konferenz ,,Operating System Design andImplementation'') 1996
- [Hamann+97] Claude-Joachim Hamann u.a. http://os.inf.tu-dresden.de/drops/doc.html
- [Sha+90] L. Sha, R. Rajkumar, J. P. Lehoczky: Priority Inheritance Protocols: An Approach to Real-Time Synchronization, IEEE Transactions on Computers, September 1990
- [Inf-Handbuch97] Peter Rechenberg, Gustav Pomberger (Hrsg.): Informatik-Handbuch, Carl-Hanser-Verlag München Wien, 1997
- [Schiebe+92] Michael Schiebe (Hrsg.): Real-time Systems -Engineering andApplications, Kluwer Academic Publishers 1992
- [Silberschatz+91] Abraham Silberschatz, James L. Peterson, Peter B. Galvin: Operating Systems Concepts(3rd edition), Addison-Wesley Publishing Company, 1991
- [Steinmetz95] Ralf Steinmetz: Analyzing the Multimedia Operating System, IEEE Multimedia, Vol. 2, Nr. 1 (Spring 1995)
- [Wörn+2005] Heinz Wörn, Uwe Brinkschulte: Echtzeitsysteme - Grundlagen, Funktionsweisen, Anwendungen, Springer-Verlag Berlin Heidelberg 2005
- [Yau+96] David K. Y. Yau, Simon S. Lam: Adaptive Rate-Controlled Scheduling for Multimedia Applications, Proceedings of the 4th ACM International Multimedia Conference 1996
- Container:
- [Merkel14] Dirk Merkel: Docker: Lightweight Linux Containers for Consistent Development and Deployment, Linux Journal, No. 239 (Mar 2014).
- Adaptivitätsbegriff:
- [Marciniak94] John J. Marciniak (Hrsg.): Encyclopedia of Software Engineering, Vol. 1, John Wiley& Sons, 1994
- Exokernel:
- [Engler+95] Dawson R. Engler, M. Frans Kaashoek, James O‘TooleJr.: Exokernel: An Operating System Architecture for Application-Level Resource Management, 15th ACM Symposium on Operating System Principles(SOSP), 1995
- [Engler98] Dawson R. Engler: The Exokernel Operating System Architecture, Ph.D. Thesis, Massachusetts Institute ofTechnology, 1998
- [Engler+97] M. Frans Kaashoek, Dawson R. Engler, Gregory R. Ganger, Héctor M. Briceño, Russell Hunt, David Mazieres, Thomas Pinckney, Robert Grimm, John Jannotti, Kenneth Mackenzie: Application Performance and Flexibility of Exokernel Systems, 16th ACM Symposium on Operating System Principles(SOSP), 1997
- [Engler+96] Dawson R. Engler, M. Frans Kaashoek, Gregory R. Ganger, Héctor M. Briceño, Russell Hunt, David Mazieres, Thomas Pinckney, John Jannotti: Exokernels (Präsentation, online verfügbar unter: https://pdos.csail.mit.edu/exo/exo-slides/sld001.htm)
- Nemesis:
- [Reed+97] Dickon Reed, Robin Fairbairns (Hrsg.): Nemesis, The Kernel - Overview, Technischer Bericht, 1997, (verfügbar unter: http://citeseerx.ist.psu.edu/viewdoc/summary?doi=10.1.1.57.512)
- MirageOS:
- [Scott+13] Anil Madhavapeddy, David J. Scott: Unikernels: Rise of the Virtual Library Operating System, ACM Queue -Distributed Computing, Vol. 11, No. 11 (Nov 2013), https://dl.acm.org/citation.cfm?id=2566628
- Virtualisierung:
- [Popek&Goldberg74] Gerald J. Popek, Robert P. Goldberg: Formal Requirements for Virtualizable Third Generation Architectures, Communications of the ACM, Vol. 17, No.7, 1974
- [Adams&Agesen06] Keith Adams, Ole Agesen: A Comparison of Software and Hardware Techniques for x86 Virtualization, 12th Int. Conf. on Architectural Support for Programming Languages and Operating, Systems(ASPLOS XII), 2006
- [Agesen+12] Ole Agesen,Jim Mattson,Radu Rugina, Jeffrey Sheldon: Software Techniques for Avoiding Hardware Virtualization Exits, 2012 USENIX Annual Technical Conference (USENIX ATC '12), 2012
- Parallelisierbarkeit:
- [Heiss94] Hans-Ulrich Heiss: Prozessorzuteilung in Parallelrechnern, B.I. Wissenschaftsverlag: Mannheim, Leipzig, Wien, Zürich, 1994, ISBN: 3-411-17061-1
- [Keckler+2009] Stephen W. Keckler: Multicore Processors and Systems, Springer Science+BusinessMedia, LLC 2009, ISBN 978-1-4419-0263-4
- Barrelfish:
- [Baumann+2009b] Andrew Baumann et al.: The Multikernel: A newOS architecture for scalable multicoresystems, Proceedings ACM SOSP (Symposium on Operating System Principles) 2009
- Amoeba:
- [Tanenbaum+91] AndrewS. Tanenbaum, M. Frans Kaashoek, Robbertvan Renesse, Henri E. Bal: The Amoeba Distributed Operating System - A Status Report Elsevier Computer Communications, Vol. 14, No.6, 1991, S. 324 - 335